Friends, Azou is here, and I am increasingly feeling that the oracle track is undergoing a transition very similar to 'cloud service': In the past, everyone treated oracle as a pipe, and the discussion points were always about 'speed, accuracy, and coverage'; but as the blockchain begins to absorb RWA, prediction markets, and AI agents—scenarios that require high responsibility—this single pipe is no longer sufficient. The market will force you to decompose services, decompose quality, and decompose prices to resemble more like cloud vendors' product lines. APRO is worth using as a sample because it binds these two aspects together in its positioning: it needs to provide structured data required by traditional DeFi applications and also use LLM to process unstructured data from the real world, combining traditional verification with AI analysis through a layered network.
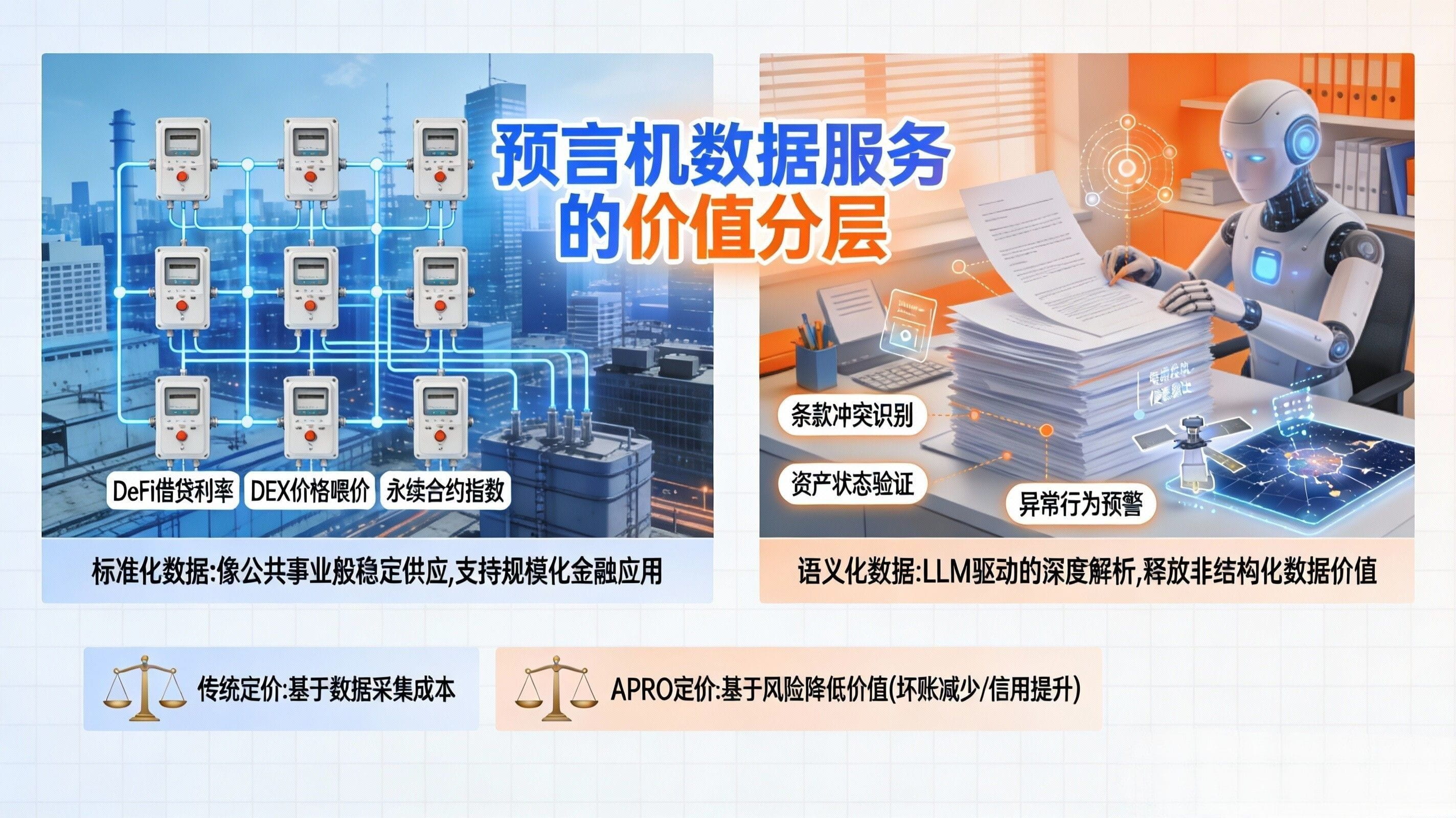
First, let’s clarify the 'standard data layer', which corresponds to the needs most familiar to DeFi: price feeds, trading pairs, update frequency, deviation thresholds, contract entry points. In simple terms, it allows lending, DEX, perpetuals, and aggregators to reliably use 'available digits'. APRO's documentation breaks down this capability very clearly: Data Service is divided into Data Push and Data Pull, with two models targeting different business forms; it also specifies that it currently supports 161 Price Feed services, covering 15 major networks. You see, this is a typical characteristic of standard data: scalable, replicable, and connectable, more like 'water, electricity, and gas'. For project parties, the most important aspect of this data layer is not the flashy features, but predictability—when updates happen, how updates are triggered, whether the on-chain contract can be consistently read, and whether there are clear rollback paths in case of issues.
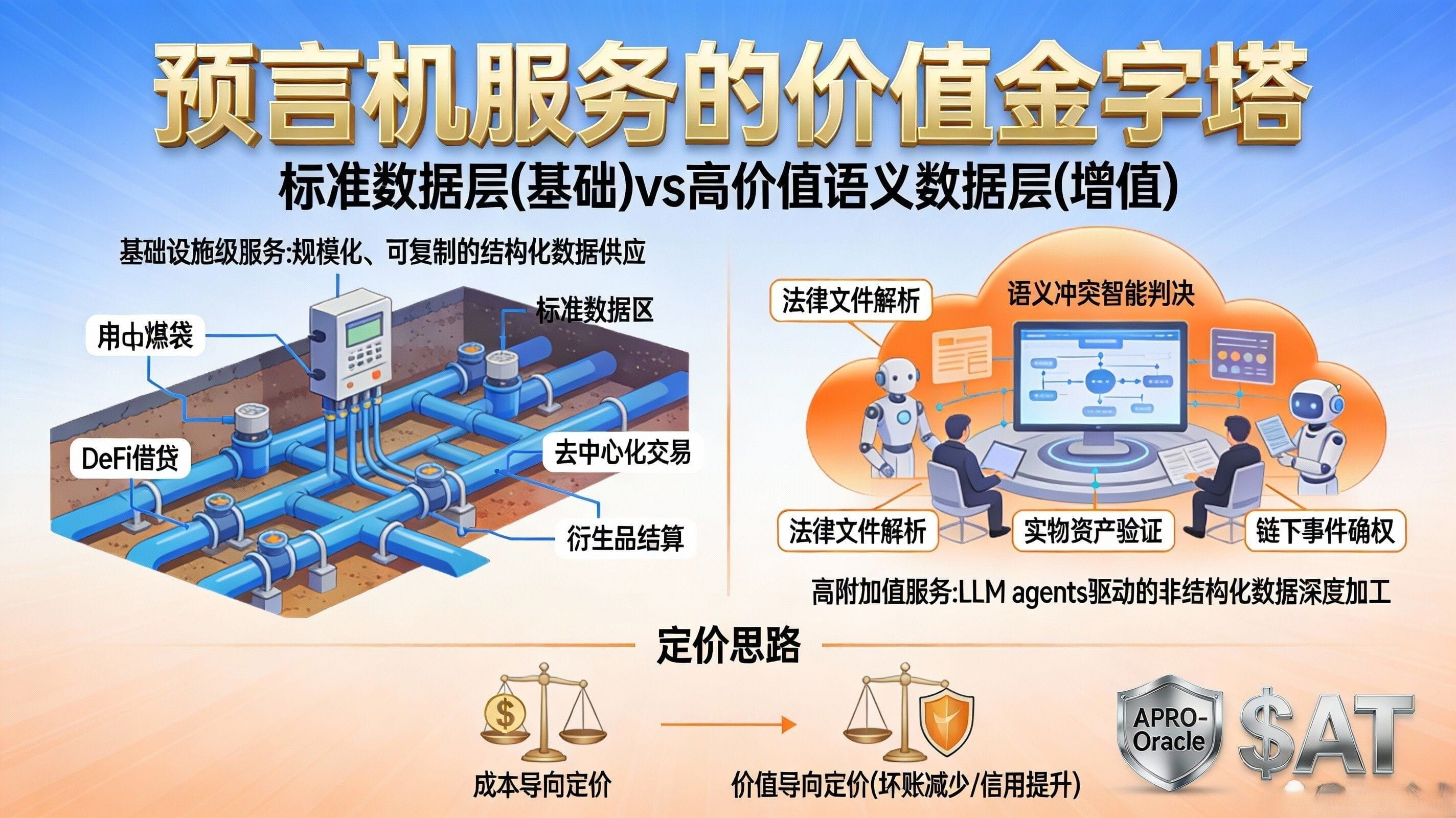
But when you take another step forward, you will encounter the 'high-value semantic data layer'. The common point of this layer of data is: it answers not 'how much', but 'did this event actually happen?'; 'is this asset truly covered?'; 'what are the key terms in this document?'; 'has this information been edited/taken out of context?', essentially compressing the semantics and evidence chain of the real world into inputs that can be settled on-chain. APRO has positioned 'being able to handle unstructured data' as one of its core selling points in project analysis at Binance and explicitly mentions that its Verdict Layer utilizes LLM agents to handle conflicts. When you combine this with the PoR (Proof of Reserves) feed categories that have already been launched in its documentation, it becomes easier to understand why this layer of data is more 'expensive': PoR feeds do not simply report a price; they need to provide a verifiable signal of 'reserve status' on-chain, and support chain type, contract address, and other entry points that are verifiable.
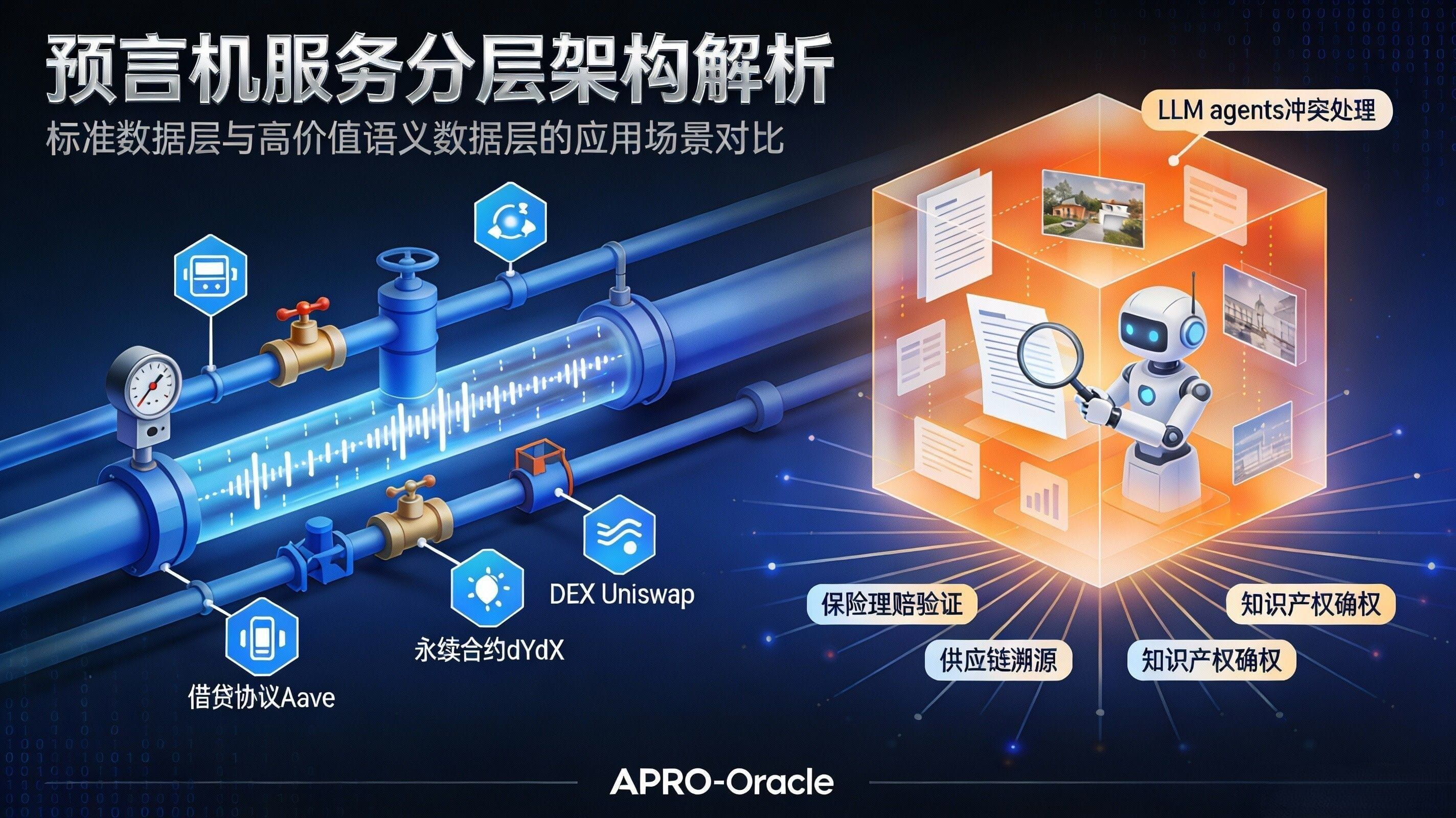
Thus, the meaning of 'layering' emerges: standard data is like 'general commodities', while high-value semantic data resembles 'responsible professional services'. When you create a price feed, you need to address latency, coverage, resistance to manipulation, and availability; when creating a PoR or more complex semantic data, you also need to resolve sources of evidence, version differences, conflict resolution, traceability, and auditability, and in some scenarios, you must also consider privacy and compliance. From an engineering cost perspective alone, the two cannot be priced the same, let alone the risk exposures they bring are not on the same level: a price error might result in slippage or liquidation errors; a factual error could lead to credit events, disputed settlements, or even legal risks. The reason APRO's architectural narrative emphasizes 'AI judgment layer + submission verification layer + on-chain settlement' repeatedly is essentially to reserve 'thicker verification budgets' for such high-value scenarios.
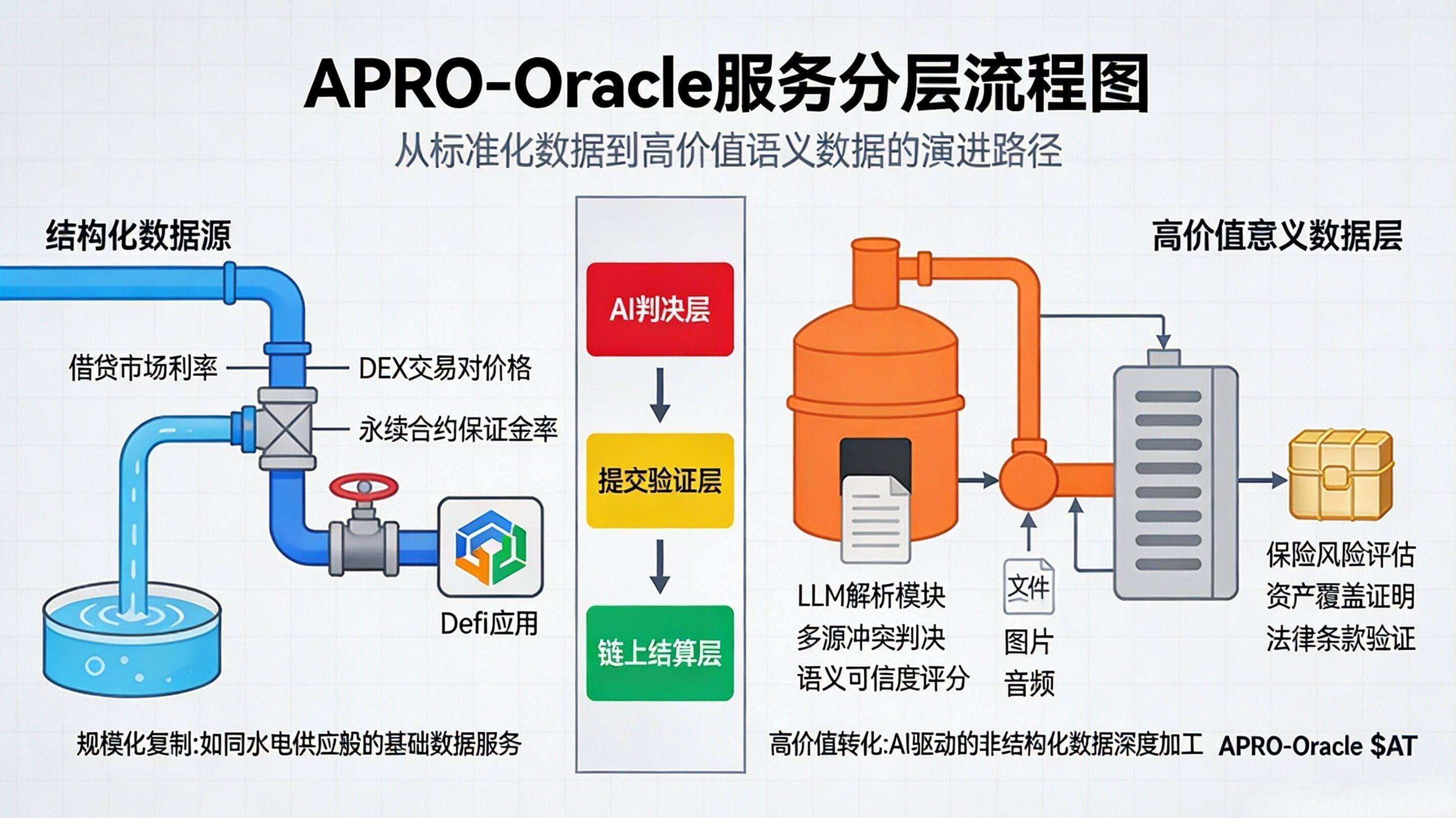
This is the change in rules I want to discuss today: the oracle product line is starting to adopt tiered pricing like cloud services, no longer a 'one-price-fits-all' approach. You can think of it as a very realistic market evolution: standard price feeds will increasingly resemble basic packages, charging based on chain type, trading pairs, call volume, or update method; while high-value semantic data will increasingly resemble premium packages, priced according to evidence chain depth, auditability, conflict resolution complexity, and even SLA and liability boundaries. The key here is not to 'earn more', but to 'reasonably map costs and risks to prices'; otherwise, you can only rely on subsidies to scale, and the larger the scale, the more likely it is to fail in high-responsibility scenarios. APRO's approach, which covers both structured and unstructured data, will naturally push this layering to the forefront, as it already meets the conditions of 'the same set of network services serving two levels of demand.'
The impact on users, I believe, will be more positive than many people imagine: payment expectations will be clearer. DeFi users and protocol parties will find it easier to understand what layer of capability they are paying for, whether it is for on-demand data with low latency or for traceable proof of facts; users in scenarios like RWA, prediction markets, and Agents will also find it easier to accept that 'high-quality data is more expensive' because what they are buying is not a more attractive interface, but a lower probability of disputes, a lower probability of being influenced, and a lower probability of erroneous settlements. The APRO documentation clearly outlines the service model, chain entry points, and even the supported chain list for PoR, essentially helping the market form a new common understanding: data is a commodity, but 'the proof and judgment behind the data' is a service.
Finally, I will use a 'discussion guide' to wrap up Day 38: how should high-value data be priced? I give you a Azur-style way of thinking—don't start from 'cost', but rather from 'what disasters it saves you from'. Suppose you are in lending, low-latency price feeds reduce your bad debts and liquidation errors, then its price should be tied to risk exposure; suppose you are in RWA, PoR reduces credit doubts and panic withdrawals, then its price should be linked to auditability and evidence chain strength; suppose you are in prediction markets, semantic judgments reduce dispute arbitration and invalid frequency, then its price should be related to conflict resolution complexity and auditability. You can even pose this as an interactive question to the readers: if you were a protocol party, how much more would you be willing to pay for 'lower latency', how much for 'more auditability', and how much for 'stronger resistance to narrative contamination'? These three answers basically determine whether the future oracle will resemble 'water, electricity, and gas' or 'cloud services'.
\u003cm-27/\u003e \u003cc-29/\u003e \u003ct-31/\u003e


