
#Neuraxon Academia Inteligenței — Volumul 10
De echipa științifică Qubic

Dacă construim un sistem artificial și vrem să știm dacă este inteligent, ce anume măsurăm? Credem că știm când auzim că ChatGPT-5 anunță că a învins DeepSeek și apoi că Claude ia Gemini.
Dar întrebarea rămâne, intactă. Măsurarea inteligenței artificiale nu este măsurarea vitezei sau temperaturii. Nu avem o unitate de măsură, oricât de ciudat ar părea.
În psihologie ne ocupăm de această problemă de mai bine de un secol. Inteligența artificială a fost la ea timp de un deceniu. Și o face cu grabă, cu mulți bani în joc și cu o tentație constantă: a declara victorie.
Factorul g: Un singur număr pentru a rezuma inteligența generală
La începutul secolului XX, Charles Spearman a realizat că, atunci când un copil se descurca bine într-o materie, avea tendința să se descurce bine și în celelalte, chiar dacă erau materii fără o aparentă legătură. Scorurile se corelau între ele, toate pozitiv. El a numit acel model manifoldul pozitiv și a dedus că trebuie să existe un factor latent comun în spatele tuturor acelor abilități disparate: factorul g sau inteligența generală (Spearman, 1904).
Ideea este seducătoare. Dacă toate testele cognitive se încarcă pe un singur factor, este suficient să extragi acel factor prin analiza factorilor pentru a avea o măsură sumară a capacității generale. În practica umană, acel prim factor explică de obicei între 40 și 50 % din varianta în performanță (Detterman & Daniel, 1989; Deary et al., 2009).
Dar fii atent, pentru că aici se află prima capcană. Factorul g este populațional. Nu măsoară individul, ci variația între indivizi (Hernández-Orallo et al., 2021). A spune că un subiect specific are atâta g este, strict vorbind, o greșeală. g apare când compari mulți subiecți, nu când examinezi unul. Ca personalitate, ești cel mai extrovertit din grupul tău de vârstă. Și rămâi așa la 50 de ani în raport cu grupul tău, chiar dacă în intensitate ești mai puțin extrovertit decât la 20.
Ce măsoară de fapt IQ-ul? Înțelegerea scorurilor de inteligență
Dar atunci, ce măsoară IQ-ul?
Măsoară o poziție relativă. Scala este calibrată pe un eșantion cu media 100, deviația standard 15. Un IQ de 130 nu reprezintă o cantitate absolută de inteligență stocată în capul cuiva; este afirmația că această persoană este cu două deviații standard deasupra mediei grupului său normativ. Numărul este atașat individului, da, dar semnificația sa este populațională. Este o poziție într-un clasament, nu un conținut.
Înălțimea ta este absolută: ești înalt de 180 cm chiar dacă ești ultimul om de pe Pământ. IQ-ul tău nu este: a fi deasupra mediei necesită o medie, iar o medie necesită alții. Nimeni nu poate fi mai inteligent decât media pe o insulă pustie.
Acum se înțelege de ce transferul acestui lucru la AI este atât de delicat. Când cineva calculează un g pentru un set de modele de limbaj mari (LLM-uri), acel factor este un artifact al setului pe care l-a ales. Măsurăm o poziție într-un tabel și o prezentăm ca și cum ar fi o proprietate internă a sistemului.
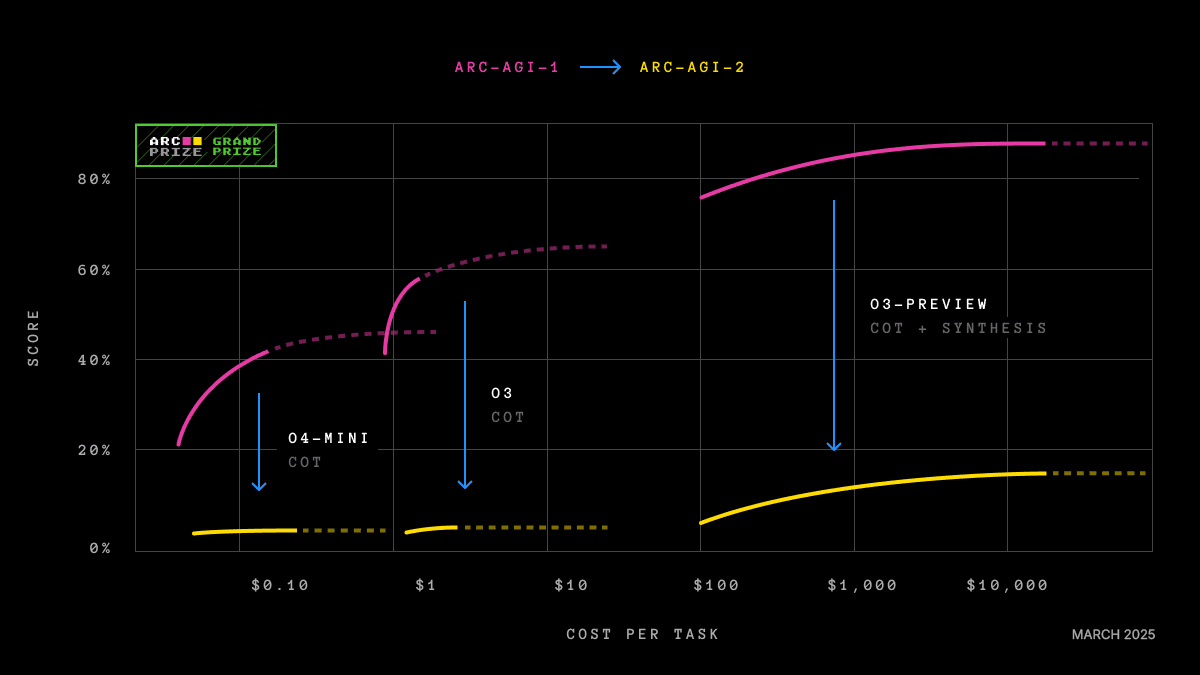
Aplicarea factorului g la inteligența artificială: o tentație periculoasă
Tentatia de a transfera totul la AI a fost irezistibila. Gignac și Szodorai au propus că, dacă performanța modelelor pe diverse sarcini se corelează pozitiv, ar trebui să fie posibil să identificăm un factor general de capacitate în sistemele artificiale. Și într-adevăr, mai multe lucrări recente aplică analiza factorilor pentru a testa bateriile în LLM-uri și găsesc un factor g unidimensional care rămâne stabil între modele, baterii și metode de extracție (Ilić, 2023). Pare a fi o confirmare. Este înțelept să fim suspicioși.
Apariția unui factor dominant de primă linie nu dovedește că există o capacitate generală analogică cu cea umană. Dovedește că scorurile acelor modele covariază. Și covariază dintr-un motiv foarte superficial: împărtășesc arhitectura, împărtășesc corpusul de antrenament, împărtășesc rețetele de optimizare. Un model mare, bine antrenat face totul mai bine decât unul mic și prost antrenat, în toate sarcinile deodată. Asta este suficient pentru a fabrica un frumos manifold pozitiv care nu ne spune nimic despre generalitatea cognitivă. Ne spune despre scala de calcul. FII ATENT: factorul pe care îl extragem poate fi pur și simplu un factor de dimensiune mascat ca inteligență.
Creierul, în plus, nu concentrează inteligența într-un singur modul. O multitudine de subsisteme specializate procesează în paralel și, atunci când o bucată de informație câștigă competiția, devine disponibilă global pentru restul sistemului, care o poate recombina apoi pentru scopuri noi (Baars, 1988; Dehaene & Changeux, 2011). Ceea ce numim generalitate este disponibilitatea globală: punerea unei părți învățate într-un context în serviciul unei probleme într-altul. Nu este un număr scalar stocat; este un model de acces și integrare. Acesta este tipul de arhitectură funcțională pe care Neuraxon încearcă să îl emuleze - subsisteme modulare cu dinamici continue în timp și plasticitate pe mai multe scale temporale, mai degrabă decât un transformator monolitic.
François Chollet și Abordarea Modernă: Măsurarea a ceea ce nu știi încă cum să faci
Împotriva legăturii psihometrice, François Chollet a propus în 2019 o întoarcere conceptuală. Argumentul său, în Despre Măsura Inteligenței, este că măsuram lucrul greșit.
Benchmark-urile AI tradiționale recompensează abilități, competențe specifice în sarcini concrete. Dar o abilitate poate fi cumpărată cu date și calcul: este suficient să te antrenezi suficient pe o sarcină pentru a o stăpâni. Inteligența, susține Chollet, nu este abilitate, ci eficiență în dobândirea abilităților: cât de mult înveți din cât de puțin, când te confrunți cu o sarcină cu adevărat nouă (Chollet, 2019).
Inteligența este ceea ce faci când nu știi ce să faci.
Această distincție schimbă totul. Un sistem care rezolvă un milion de probleme pentru că a văzut zece milioane de probleme similare nu este inteligent. Un sistem inteligent este acela care, confruntându-se cu o problemă pentru care nu s-a putut pregăti, descoperă structura și se adaptează cu puține exemple. Măsura nu mai este rezultatul final, ci devine panta învățării.
ARC-AGI: Benchmarkul care testează raționarea reală AI
ARC-AGI s-a născut din această idee, iar cea mai recentă versiune, ARC-AGI-3, o duce mai departe. Nu este un test de întrebări și răspunsuri. Este un set de medii interactive, ca mini-videogame, în care agentul explorează o lume necunoscută, deduce care este obiectivul fără a fi spus în limbaj natural, construiește un model al mediului și își adaptează strategia pas cu pas (ARC Prize, 2025).
Principiile de design sunt explicite: medii 100 % rezolvabile de oameni, fără cunoștințe preîncărcate sau instrucțiuni ascunse, și cu suficientă noutate pentru a preveni memorarea. Ceea ce se punctează nu este corectitudinea, ci eficiența în dobândirea abilității în timp.
Este opusul factorului g: în loc să caute ceea ce un sistem deja stăpânește și să-l rezume, caută ceea ce încă nu știe să facă și măsoară cât de mult îi costă să învețe.
Contaminarea datelor: De ce scorurile benchmark-urilor LLM sunt umflate
Motivul final pentru care abordarea lui Chollet contează, și de ce factorul g aplicat LLM-urilor este atât de alunecos, are un nume tehnic: contaminarea datelor. Dacă examenul, sau ceva aproape identic, a fost în notele pe care studentul le-a studiat, nota lor nu măsoară ce pot raționa. Măsoară ce au memorat.
Modelele de limbaj sunt antrenate pe cărți, forumuri, depozite de cod, articole, practic tot textul disponibil. Standardele cu care le evaluăm ulterior sunt publicate pe internet. Concluzia este că fragmente din teste ajung în datele de antrenament, ceea ce încalcă separarea între antrenament și evaluare și umflă scorurile (Xu et al., 2024; Deng et al., 2024). Auditările empirice au detectat niveluri de contaminare între 1 % și 45 % în standardele utilizate pe scară largă, iar problema crește în timp (Li et al., 2024).
Nu este o problemă minoră de câteva întrebări scurse. În standardele menționate ca MMLU sau GSM8K, o parte din ceea ce interpretăm ca raționare poate fi pură memorare (Chen et al., 2025). Când se aplică tehnici de decontaminare care rescriu elementele scurse fără a le altera dificultatea, acuratețea scade: într-un studiu, 22.9 % pe GSM8K și 19.0 % pe MMLU (Zhu et al., 2024).
Elementele parafrazate, sau chiar cele traduse într-o altă limbă, evită detectoarele de suprapunerii superficiale și continuă să umfle rezultatele (Yang et al., 2023; Yao et al., 2024). Soluțiile obișnuite (parafrazarea, traducerea, ajustarea contextului) sunt presupuse a fi eficiente fără a fi validate riguros. Și pentru cele mai multe modele deschise nu putem verifica nimic, deoarece datele lor de antrenament nu sunt publicate. Notăm examene fără a ști ce a studiat studentul.
Aici se înțelege de ce ARC-AGI a ales calea pe care a ales-o. Un mediu interactiv, nou, fără instrucțiuni în limbaj natural și conceput pentru a preveni memorarea brută, este, prin construcție, rezistent la contaminare.
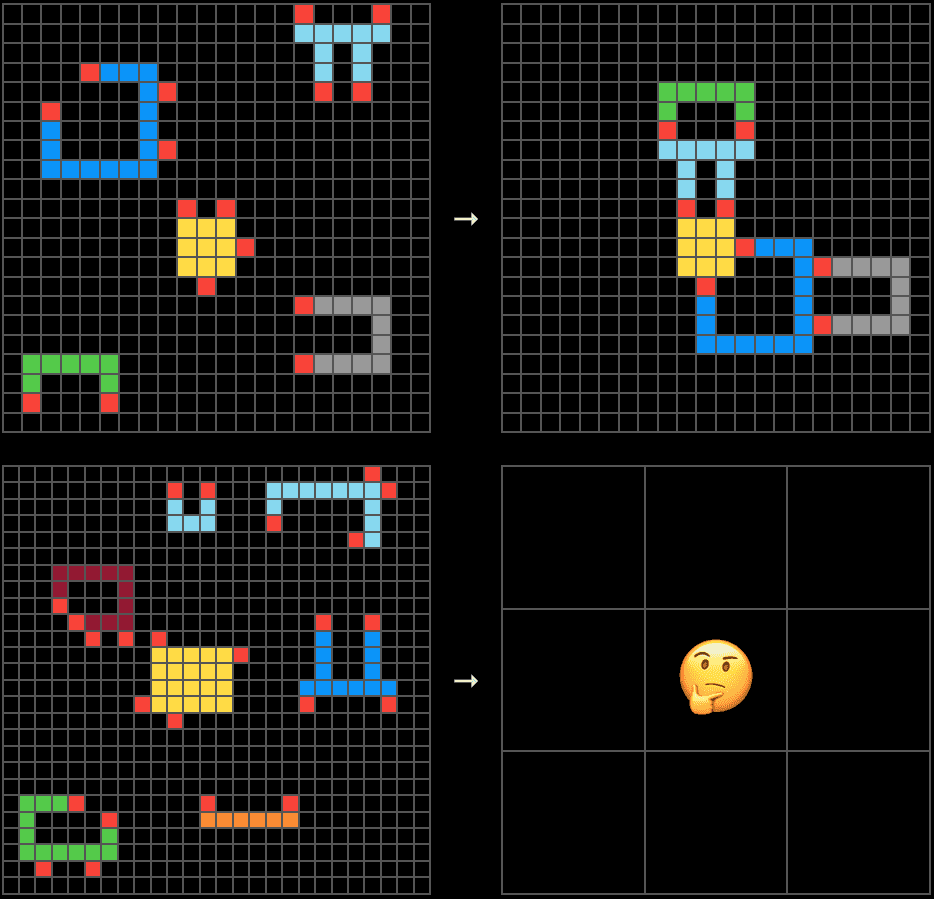
Deci, ce ar trebui să măsurăm pentru a evalua inteligența mașinilor?
Factorul g este o proprietate populațională care, aplicată modelelor ce împărtășesc arhitectura și corpusul, riscă să măsoare scala de calcul și nu generalitatea. Lecția pentru oricine construiește sisteme artificiale nu este să aleagă între factorul g și ARC-AGI ca și cum ar fi echipe rivale. Este să înțeleagă ce întrebare răspunde fiecare. O analiză a factorilor poate fi utilă pentru a descrie structura internă a performanței unui sistem, atâta timp cât primul factor nu este confundat cu o esență a inteligenței. Și un protocol de tip ARC este indispensabil pentru ceea ce contează cu adevărat: a verifica dacă sistemul generalizează dincolo de ceea ce a văzut, sau pur și simplu recită.
Când evaluăm un sistem doar prin răspunsul său final, îl măsurăm cu ochii închiși la dimensiunea sa temporală: planificare, actualizarea credințelor, integrarea dovezilor pe parcursul mai multor pași. Exact asta a decis ARC-AGI-3 să puncteze, și exact ceea ce un examen static nu poate vedea.

De ce arhitecturile AI inspirate de creier, cum ar fi Neuraxon, urmează o cale diferită
Dacă inteligența nu este un număr stocat, ci integrarea eficientă a subsistemelor specializate, așa cum sugerează teoria integrării parieto-frontale (P-FIT) și disponibilitatea globală a spațiului de lucru în creier...
Dacă acea integrare este în primul rând un fenomen temporal, cu scale de timp...
Astfel, un sistem construit pe arhitecturi modulare cu sfere funcționale, plasticitate pe multiple scale temporale și dinamici continue nu trebuie evaluat cerându-i să recite răspunsuri.
Întrebarea corectă nu este câte benchmark-uri înfruntă, ci cu ce eficiență dobândește un comportament nou, în timp, în medii pentru care nu a fost pregătit. Aceasta este direcția pe care Neuraxon încearcă să o urmeze. A calcula timpul - adică, adaptarea - nu răspunsurile memorate care simulează a fi un student bun, când, în realitate, deja știe întrebările.
Referințe
Chollet, F. (2019). Despre Măsura Inteligenței. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). Neuroștiința diferențelor de inteligență umană. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Abordări experimentale și teoretice ale procesării conștiente. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Corelațiile testelor mentale între ele și cu variabilele cognitive. Inteligență.
Gignac, G. E., & Szodorai, E. T. (2024). Definirea și identificarea unui factor general de abilitate în sistemele AI.
Guttman, L. (1955). Determinarea matricelor scorurilor factorilor cu implicații pentru alte cinci probleme de bază ale teoriei factorilor comuni. British Journal of Statistical Psychology.
Hernández-Orallo, J., et al. (2021). Inteligența generală dezvăluită printr-o metrică de generalitate pentru inteligența naturală și artificială. Scientific Reports.
Honey, C. J., et al. (2012). Dinamica lentă a cortexului și acumularea de informații pe durate lungi. Neuron, 76(2), 423–434.
Ilić, D. (2023). Dezvăluirea Factorului de Inteligență General în Modelele de Limbaj: O Abordare Psihometrică. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). Teoria Integrării Parieto-Frontală (P-FIT) a inteligenței. Behavioral and Brain Sciences.
Spearman, C. (1904). "Inteligența generală" determinată și măsurată obiectiv. American Journal of Psychology, 15, 201–293.
Roberts, M., et al. (2024). Dovezi temporale ale contaminării din datele de întrerupere a antrenamentului.
Schönemann, P. H. (2008). Un răspuns la Mackintosh și câteva observații asupra conceptului de inteligență generală. arXiv:0808.2343.
Xu, C., et al. (2024). Contaminarea datelor de benchmark în modelele de limbaj mari: un studiu.
Yang, S., et al. (2023). Regândirea benchmark-ului și contaminării pentru modelele de limbaj cu mostre reformulate.
Zhu, Q., et al. (2024). Decontaminarea în timpul inferenței: reutilizarea benchmark-urilor scurse pentru evaluarea LLM-urilor. Descoperiri ale EMNLP 2024.
ARC Prize (2025). ARC-AGI-3: Un benchmark interactiv de raționare. Raport tehnic.
Explorează întreaga serie a Academiei de Inteligență Neuraxon
Acesta este Volumul 10 al Academiei de Inteligență Neuraxon de către Echipa Științifică Qubic. Dacă tocmai te alături, explorează întreaga serie pentru a construi o înțelegere completă a științei din spatele Neuraxon, Aigarth și abordarea Qubic pentru inteligența artificială descentralizată inspirată de creier:
NIA Volumul 1: De ce inteligența nu este calculată în pași, ci în timp - Explorează de ce inteligența biologică operează în timp continuu mai degrabă decât în pași computaționali discreți, ca LLM-urile tradiționale.
NIA Volumul 2: Dinamica ternară ca model al inteligenței vii - Explică dinamica ternară și de ce logica în trei stări (excitatorie, neutră, inhibitoare) contează pentru modelarea sistemelor vii.
NIA Volumul 3: Neuromodularea și AI inspirată de creier - Acoperă neuromodularea și modul în care semnalizarea chimică a creierului (dopamină, serotonină, acetilcolină, norepinefrină) inspiră arhitectura Neuraxon.
NIA Volumul 4: Rețele neuronale în AI și neuroștiință - O comparație profundă între rețele neuronale biologice, rețele neuronale artificiale și abordarea de a treia cale a Neuraxon.
NIA Volumul 5: Astrocytele și AI inspirată de creier - Cum porțile astrocytice transformă plasticitatea rețelei neuronale prin cadrul AGMP în Neuraxon.
NIA Volumul 6: Mașini conștiente vs Organisme inteligente: Conștiința AI explicată - Explorează conștiința AI prin prisma Teoriei Spațiului Global de Lucru, Teoria Informației Integrate și codificarea predictivă.
NIA Volumul 7: Jocul vieții al lui Conway, viața artificială și ecosistemele digitale - știința din spatele complexității emergente a Qubic, Aigarth și Neuraxon și criticitatea auto-organizată.
NIA Volumul 8: Criticitatea creierului și raportul de ramificare în rețele neuronale și artificiale - De ce un raport de ramificare aproape de 1 și criticitatea auto-organizată sunt principii de design inspirate biologic în Neuraxon.
NIA Volumul 9: Originile factorului g: De la educație și neuroștiință la inteligența artificială - Explorează originile factorului g în educație, neuroștiință și AI.
$Qubic este o rețea descentralizată, open-source pentru tehnologie experimentală. Pentru a afla mai multe, vizitați qubic.org. Alăturați-vă discuției pe X, Discord și Telegram.