Good evening, brothers, I am Azu. Many people write APRO and fall into a misconception: treating it as 'just another price oracle' and then comparing who is faster or who covers more pairs. The problem is, if you only use 'feed price' to understand APRO, you won't be able to explain why it needs to integrate AI, unstructured data, conflict resolution, API/WebSocket, and all these elements into the same system. A more accurate way to say it is: APRO is more like a hybrid of 'Oracle + AI middleware.' It not only delivers a price but also attempts to standardize the entire process of 'off-chain information processing → trustworthy verification → on-chain execution' as a service, allowing developers to avoid reinventing the wheel. Binance Research has a clear definition of it: this is a decentralized oracle network integrated with AI capabilities, capable of processing news, social media, complex documents, and other unstructured data with large models, converting them into structured, verifiable on-chain data.
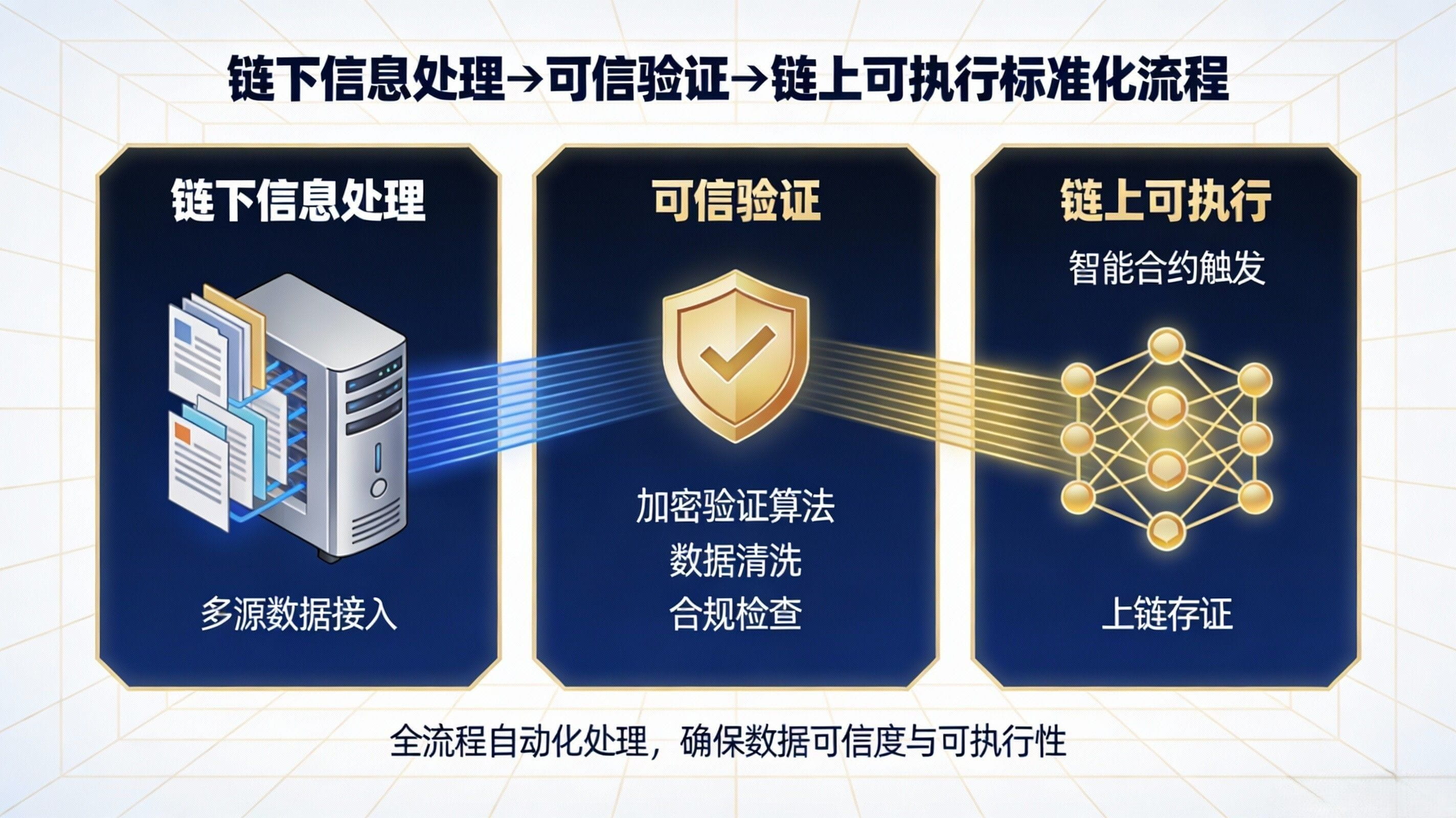
If you view APRO as the core evidence of 'AI middleware', it actually separates off-chain processing from on-chain verification and then stitches them back together with a feasible calling path. Binance Square's introduction states it very plainly: off-chain, it will collect data from trusted providers, then go through an AI-driven verification layer for consistency checks, anomaly filtering, and manipulation detection before entering on-chain verification and delivery. This statement translated into engineering language means: it not only delivers results but also provides the capability of 'how the results were filtered'—this capability is often scattered across the project party's self-built data scraping scripts, risk control rules, manual whitelists, and even temporary judgments from operations colleagues in the traditional oracle era, while APRO attempts to productize it.
More crucially, it provides developers not with a single path, but a 'combination of API/contract interfaces', which is where the middleware flavor is strongest. If you are doing traditional DeFi and just want to steadily read a price, the Data Push contract table has clearly listed trading pairs, deviation thresholds, heartbeat, and contract addresses, which constitutes a typical standardized entry for 'directly reading contracts', ready for developers to use. However, if you are dealing with trading, perpetuals, or aggregators that are more sensitive to time scales, the logic of Data Pull resembles 'on-demand data retrieval and bringing it on-chain at the needed moment': the official Getting Started clearly states that contracts can fetch real-time price data on demand when needed, with data sourced from many independent nodes, suitable for a 'retrieve when needed' model. At the same time, it also provides explanations for API & WebSocket, telling you how to get reports from the interface, how to handle missing feeds, and other return scenarios—this is very much like cloud services: you can either go for 'pure on-chain readings' or take a more flexible path of 'off-chain report retrieval + on-chain verification + triggering logic'.

Why is this combination of 'off-chain processing + on-chain verification' important? Because it directly changes the way developers call, which is the rule change that you need me to clarify: the calling path has become more flexible. Previously, many projects needing complex data (especially those with semantics and evidence) could only build their own data pipelines: grabbing sources, cleaning, deduplication, time alignment, anomaly detection, then writing an on-chain submitter, while also worrying about being injected with garbage information or being led by the rhythm. The architecture narrative of APRO is the opposite—it handles 'complex input' off-chain, then uses verification mechanisms on-chain to ensure 'whether the result is trustworthy and executable', and delivers capabilities to you through contracts and two types of interfaces. ZetaChain's documentation has also summarized it very succinctly: APRO provides reliable data services through off-chain processing and on-chain verification, covering different needs through two service models.
The impact on users (especially developers and project parties) is very real: what you save is not just a line or two of code, but the long-term maintenance cost of building your own data pipeline. The most expensive part of a data pipeline has never been 'setting it up on the first day', but 'you still have to maintain it on the 90th day': when the data source changes, the interface shakes, extreme market conditions arise, or malicious samples come in, you will find yourself maintaining a half-baked middleware. If APRO can solidify 'semantic processing of unstructured input, conflict adjudication, and verifiable delivery' into network capabilities, then project parties can focus more on business logic, risk control strategies, and product experience, rather than constantly firefighting data issues. Binance Research has articulated its mission in a way that resembles a 'middleware vision': enabling Web3/AI agents to bridge real data and structuring it to put on-chain.
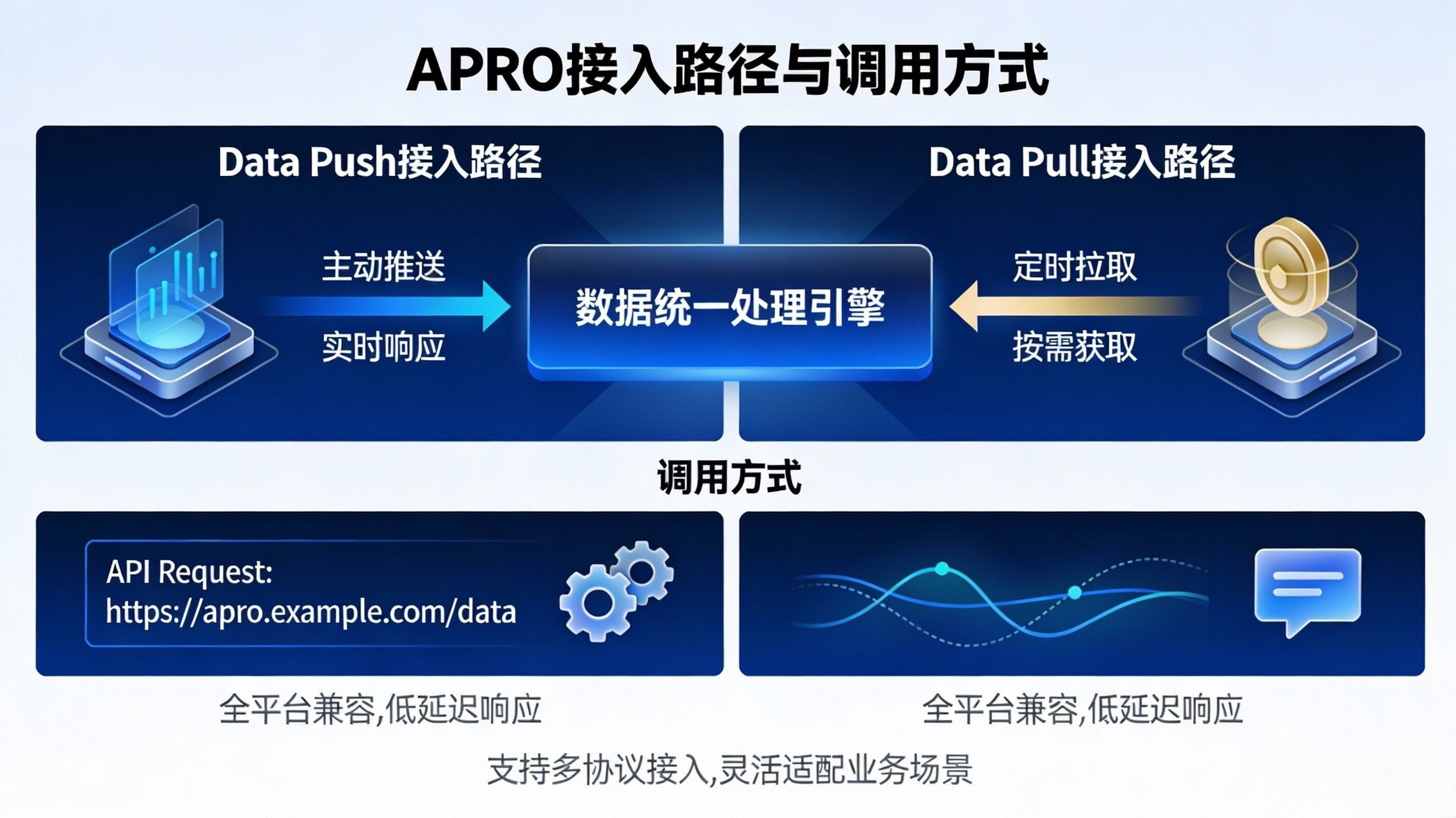
Finally, use the action guide you want to wrap up. I suggest you write it as a very specific interaction: let the readers compare their project tech stack and draw a 'connection path map'. You don't need to make it look as professional as an architecture diagram; just draw according to the real process: where your data comes from now, whether it's read directly from the chain, relies on CEX API, or scrapes announcements and PDFs; where you currently do cleaning and anomaly handling, whether it's backend services, scripts, or manual work; how you now feed the results to the contract, whether it's timed pushing, reading during a trade, or putting the signed report into the transaction for verification. Then you can integrate the two entry points of APRO: can the standard scenario directly use Data Push contract readings, can the trading/high-frequency scenario use the Data Pull report to complete data retrieval and verification in 'the same transaction', and can the semantic/evidence chain scenario let off-chain handle it first, with on-chain only doing final verification and execution. Once you draw this map, readers will immediately understand my statement today: APRO is not competing with you for business; it is productizing the 'data middleware' on your behalf.

