

Been digging into OpenLedger’s Datanets lately and it took me longer than I expected to really get why this setup feels different.
I’ve followed the project since the Binance listing last September, watched the mainnet drop in November, and kept an eye on the token. But the data layer is where things actually start to make sense once you zoom in.
What I noticed today
Datanets are basically community-owned, domain-specific data networks that live on-chain. You can create one or join an existing one — stuff like Data Intelligence, Creator, Web3 Dev, or DePIN-focused pools. Contributors drop in data (text, images, documents, labels), validators check quality, and owners set the rules for that niche.
The piece that stands out is Proof of Attribution. When a model gets trained or runs inference on data from these pools, the chain records which contributions actually influenced the output and by how much. Then smart contracts handle automatic payouts to the people who supplied the data. No spreadsheets, no trust-me-later promises. It’s built to make data liquid and payable.

Mainnet has been live since mid-November. Testnet already showed real scale with over 25 million transactions and millions of nodes. Today $OPEN is trading around $0.212, up roughly 2% in the last 24 hours with $33 million+ in volume. Market cap sits near $45 million with about 215 million tokens circulating. We’re still sitting roughly 88% below the $1.82 ATH from the Binance listing day, but the volume has stayed decent even through the drawdown.

Most AI-crypto projects either focus on compute, agents, or just slap “decentralized” on a model marketplace. $OPEN Ledger is trying to solve the actual data problem at the root — the part that’s currently dominated by centralized scraping with zero compensation to the people who created the data.
The attribution layer changes the incentive. Instead of hoping someone credits you later, your contribution is tracked and rewarded proportionally every time it’s used. That turns static datasets into something that can keep earning. It also makes specialized, high-quality data more valuable because domain-specific Datanets should produce better results than generic scrapes.
Volume holding above $30M while price is this low tells me there’s still genuine interest, not just listing hype. The fact that mainnet has been running for six months without major drama is worth noting too — a lot of AI chains are still promising infrastructure that doesn’t exist yet.
That said, adoption is still early. We don’t have massive public numbers on how many models are actively pulling from live Datanets or how much is being paid out daily. Execution on the contributor side will decide if this stays a cool idea or becomes actual usage.
I’m cautiously optimistic. The incentive design around data ownership and automatic rewards feels cleaner than most narratives in this space. I don’t think it’s going to flip the entire AI industry overnight, but it addresses a real pain point that centralized players have ignored for years.
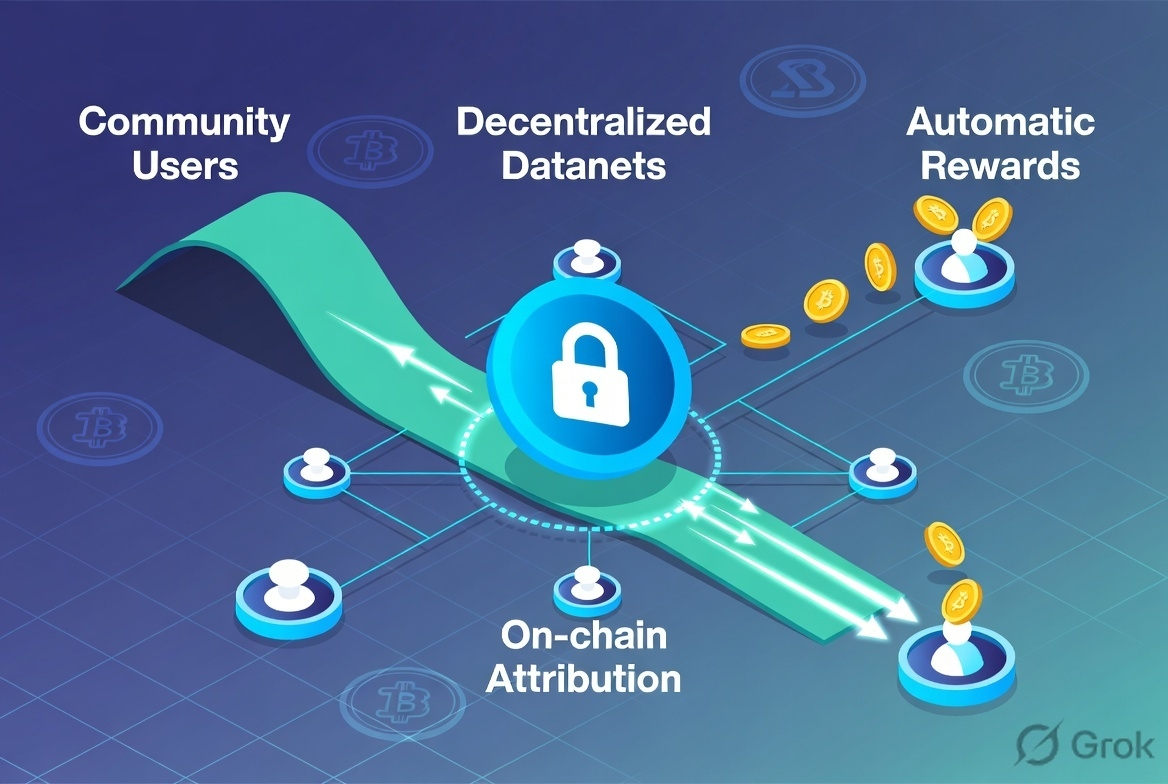
I added a bit more to my position today after spending time mapping out how a simple Datanet actually flows from contribution to payout. Still watching closely though — if the attribution and reward mechanics deliver in practice, this could compound nicely. If it stays mostly theoretical, the token will keep grinding.
What’s actually stopping you from contributing data or starting your own Datanet right now? Have you looked at the contributor flow yet, or does it still feel too early/complicated? Drop your honest thoughts — I’m curious what others are seeing.