
#Neuraxon Akademia Inteligencji — Tom 10
Od zespołu Qubic Scientific

Jeśli stworzymy sztuczny system i chcemy wiedzieć, czy jest inteligentny, co dokładnie mierzymy? Myślimy, że wiemy, gdy słyszymy, że ChatGPT-5 ogłasza, że pokonał DeepSeek, a Claude zmiata Gemini.
Ale pytanie wciąż pozostaje, nienaruszone. Mierzenie sztucznej inteligencji to nie to samo, co mierzenie prędkości czy temperatury. Nie mamy jednostki miary, jak dziwnie by to nie brzmiało.
W psychologii zajmujemy się tym problemem od ponad wieku. Sztuczna inteligencja robi to od dekady. I robi to w pośpiechu, z dużymi pieniędzmi na szali i z ciągłą pokusą: ogłosić zwycięstwo.
Czynnik g: jedna liczba podsumowująca ogólną inteligencję
Na początku XX wieku Charles Spearman zdał sobie sprawę, że gdy dziecko dobrze radzi sobie w jednym przedmiocie, zwykle dobrze radzi sobie też w innych, nawet jeśli są to przedmioty bez oczywistego związku. Wyniki korelują ze sobą, wszystkie pozytywnie. Nazwał ten wzór pozytywnym manifoldem i wywnioskował, że musi istnieć wspólny latentny czynnik stojący za wszystkimi tymi różnymi zdolnościami: czynnik g, czyli inteligencja ogólna (Spearman, 1904).
Pomysł jest kuszący. Jeśli wszystkie testy poznawcze ładują się na jeden czynnik, wystarczy wydobyć ten czynnik poprzez analizę czynnikową, aby mieć podsumowującą miarę ogólnej zdolności. W praktyce ludzkiej ten pierwszy czynnik zazwyczaj tłumaczy od 40 do 50 % wariancji w wydajności (Detterman & Daniel, 1989; Deary et al., 2009).
Ale uważaj, bo tutaj leży pierwsza pułapka. Czynnik g jest populacyjny. Nie mierzy jednostki, ale wariancję w ramach jednostek (Hernández-Orallo et al., 2021). Mówienie, że dany podmiot ma tyle g, jest ściśle mówiąc błędem. g pojawia się przy porównywaniu wielu podmiotów, a nie przy badaniu jednego. Jak osobowość, jesteś najbardziej ekstrawertyczny w swojej grupie wiekowej. I pozostajesz taki w wieku 50 lat w stosunku do swojej grupy, nawet jeśli w intensywności jesteś mniej ekstrawertyczny niż w wieku 20 lat.
Co naprawdę mierzy IQ? Zrozumienie wyników inteligencji
Ale wtedy, co mierzy IQ?
Mierzy względną pozycję. Skala jest kalibrowana na próbie ze średnią 100, odchyleniem standardowym 15. IQ 130 to nie jest absolutna ilość inteligencji przechowywana w czyjejś głowie; jest to twierdzenie, że ta osoba jest dwa odchylenia standardowe powyżej średniej swojej grupy normatywnej. Liczba jest przypisana do jednostki, tak, ale jej znaczenie jest populacyjne. To pozycja w rankingu, a nie treść.
Twoja wysokość jest absolutna: masz 180 centymetrów wzrostu, nawet jeśli jesteś ostatnim człowiekiem na Ziemi. Twój IQ nie jest: bycie ponad średnią wymaga średniej, a średnia wymaga innych. Nikt nie może być bardziej inteligentny niż średnia na bezludnej wyspie.
Teraz rozumie się, dlaczego przeniesienie tego do AI jest tak delikatne. Kiedy ktoś oblicza czynnik g dla zestawu dużych modeli językowych (LLM), ten czynnik jest artefaktem zestawu, który wybrali. Mierzymy pozycję w tabeli, a przedstawiamy ją, jakby była wewnętrzną właściwością systemu.
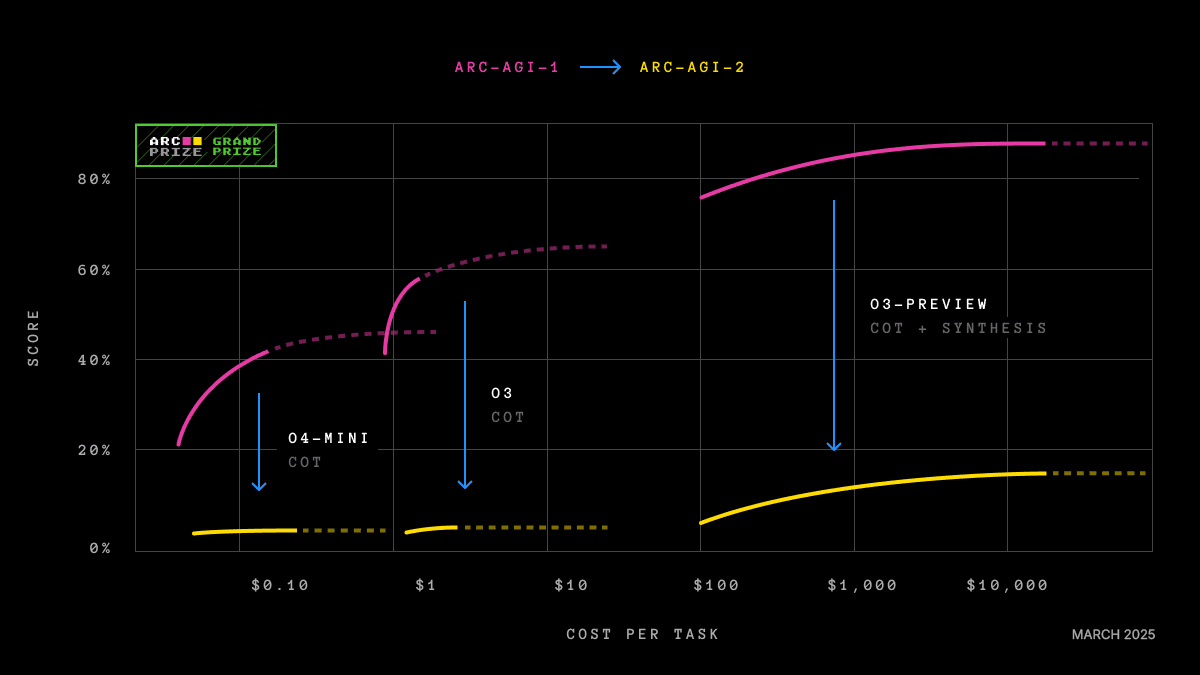
Zastosowanie czynnika g do sztucznej inteligencji: niebezpieczna pokusa
Pokusa, żeby przenieść to wszystko do AI była nieodparta. Gignac i Szodorai zaproponowali, że jeśli wydajność modeli w różnych zadaniach koreluje pozytywnie, powinno być możliwe zidentyfikowanie ogólnego czynnika zdolności w systemach sztucznej inteligencji. I rzeczywiście, kilka ostatnich prac stosuje analizę czynnikową do testów w LLM-ach i znajduje jednostkowy czynnik g, który pozostaje stabilny w różnych modelach, testach i metodach wydobywania (Ilić, 2023). To brzmi jak potwierdzenie. Mądrze jest być podejrzliwym.
Pojawienie się dominującego pierwszego czynnika nie dowodzi, że istnieje ogólna zdolność analogiczna do ludzkiej. Dowodzi, że wyniki tych modeli współzmieniają się. I współzmieniają się z bardzo płytkiego powodu: dzielą architekturę, dzielą zbiór treningowy, dzielą przepisy optymalizacyjne. Duży, dobrze wytrenowany model robi wszystko lepiej niż mały, słabo wytrenowany, we wszystkich zadaniach jednocześnie. To wystarczy, aby wyprodukować piękny pozytywny manifold, który nic nam nie mówi o ogólności poznawczej. Mówi nam o skali obliczeń. UWAŻAJ: Czynnik, który wydobywamy, może być po prostu czynnikiem wielkości przebranym za inteligencję.
Mózg, co więcej, nie koncentruje inteligencji w jednym module. Mnóstwo wyspecjalizowanych podsystemów przetwarza równolegle, a gdy kawałek informacji wygrywa rywalizację, staje się ogólnie dostępny dla reszty systemu, który może go następnie połączyć w nowe cele (Baars, 1988; Dehaene & Changeux, 2011). To, co nazywamy ogólnością, to globalna dostępność: umieszczenie kawałka nauczonego w jednym kontekście na usługach problemu w innym. To nie jest przechowywana skalarna liczba; to wzór dostępu i integracji. Tego rodzaju architektura funkcjonalna, którą Neuraxon stara się naśladować — modułowe podsystemy z ciągłą dynamiką czasową i plastycznością na wielu skalach czasowych, zamiast monolitycznego transformera.
François Chollet i nowoczesne podejście: mierzenie tego, czego nadal nie wiesz, jak to zrobić
Przeciwko dziedzictwu psychometrycznemu François Chollet zaproponował w 2019 roku zwrot koncepcyjny. Jego argument w O mierze inteligencji jest taki, że mierzyliśmy niewłaściwą rzecz.
Tradycyjne benchmarki AI nagradzają umiejętności, konkretne kompetencje w konkretnych zadaniach. Ale umiejętność można kupić danymi i obliczeniami: wystarczy wystarczająco trenować na zadaniu, aby je opanować. Inteligencja, utrzymuje Chollet, to nie umiejętność, ale efektywność w nabywaniu umiejętności: ile się uczysz z tego, co mało, stając w obliczu naprawdę nowego zadania (Chollet, 2019).
Inteligencja to to, co robisz, gdy nie wiesz, co robić.
To rozróżnienie zmienia wszystko. System, który rozwiązuje milion problemów, ponieważ widział dziesięć milionów podobnych, nie jest inteligentny. Inteligentny system to taki, który, stając przed problemem, do którego nie mógł się przygotować, odkrywa strukturę i dostosowuje się na podstawie kilku przykładów. Miara przestaje być ostatecznym wynikiem i staje się nachyleniem uczenia.
ARC-AGI: Benchmark, który testuje prawdziwe rozumowanie AI
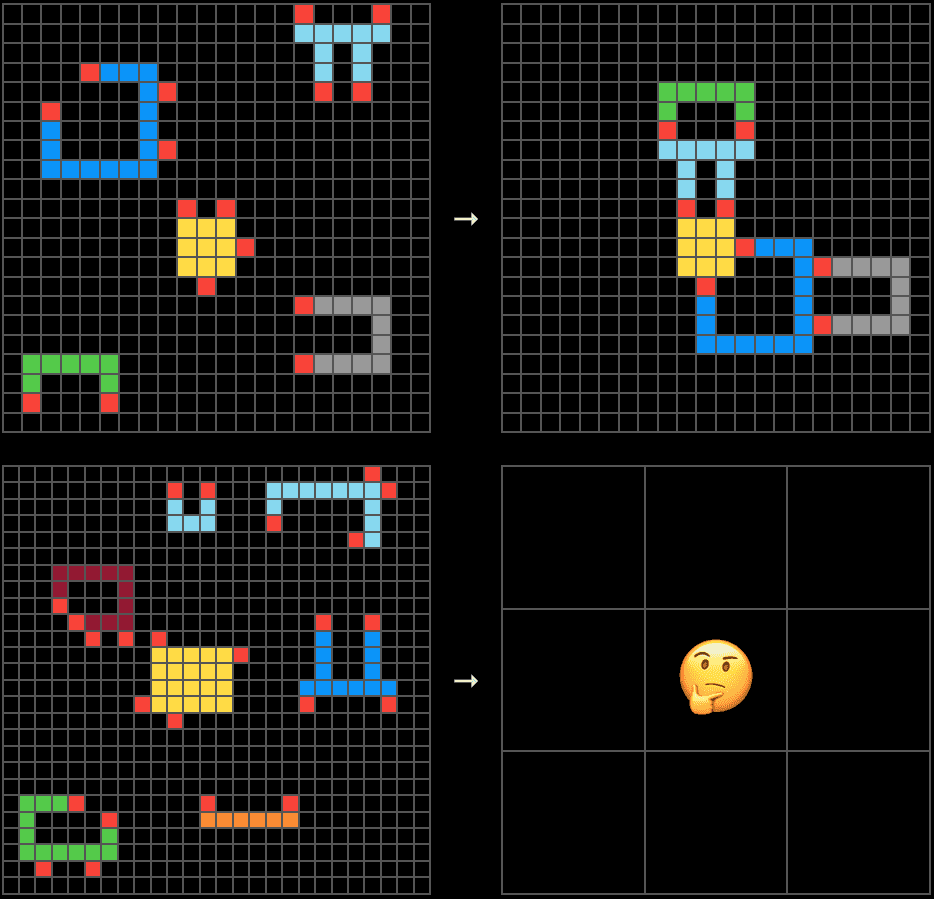
ARC-AGI powstał z tej idei, a jego najnowsza wersja, ARC-AGI-3, idzie dalej. To nie jest test na pytania i odpowiedzi. To zestaw interaktywnych środowisk, jak mini-gierki wideo, w których agent eksploruje nieznany świat, dedukuje, jaki jest cel, bez informowania go w języku naturalnym, buduje model środowiska i dostosowuje swoją strategię krok po kroku (ARC Prize, 2025).
Zasady projektowania są jasne: środowiska w 100 % rozwiązywalne przez ludzi, bez wstępnie załadowanej wiedzy lub ukrytych instrukcji i z wystarczającą nowością, aby zapobiec zapamiętywaniu. To, co jest oceniane, to nie trafienie w odpowiedź, ale efektywność w nabywaniu umiejętności na przestrzeni czasu.
To przeciwieństwo czynnika g: zamiast szukać tego, co system już opanował i podsumowywać to, szuka tego, czego jeszcze nie wie, jak to zrobić, i mierzy, ile kosztuje mu nauczenie się tego.
Kontaminacja danych: Dlaczego wyniki benchmarków LLM są zawyżone
Ostateczny powód, dla którego podejście Cholleta ma znaczenie, i dlaczego czynnik g stosowany do LLM-ów jest tak śliski, ma techniczną nazwę: kontaminacja danych. Jeśli egzamin, lub coś prawie identycznego, znalazło się w notatkach, które student studiował, ich ocena nie mierzy tego, co potrafią rozumować. Mierzy to, co zapamiętali.
Modele językowe są trenowane na książkach, forach, repozytoriach kodu, artykułach, praktycznie na całym dostępny tekst. Benchmarki, na podstawie których je później oceniamy, są publikowane w internecie. Wniosek jest taki, że fragmenty testów trafiają do danych treningowych, co narusza separację między treningiem a oceną i wypycha wyniki (Xu et al., 2024; Deng et al., 2024). Audyty empiryczne wykazały poziomy kontaminacji w zakresie od 1 % do 45 % w szeroko stosowanych benchmarkach, a problem narasta z czasem (Li et al., 2024).
To nie jest drobny problem kilku wyciekłych pytań. W benchmarkach takich jak MMLU czy GSM8K część tego, co interpretujemy jako rozumowanie, może być czystym zapamiętywaniem (Chen et al., 2025). Kiedy stosuje się techniki dekontaminacji, które przepisują wyciekłe elementy, nie zmieniając ich trudności, dokładność spada: w jednym badaniu o 22,9 % na GSM8K i 19,0 % na MMLU (Zhu et al., 2024).
Przefrazowane elementy, a nawet te przetłumaczone na inny język, omijają detektory powierzchownych nakładek i nadal wypychają wyniki (Yang et al., 2023; Yao et al., 2024). Zwykłe rozwiązania (przefrazowanie, tłumaczenie, modyfikacja kontekstu) uważane są za skuteczne, nie zostały jednak rygorystycznie zweryfikowane. A dla większości otwartych modeli nie możemy nawet nic sprawdzić, ponieważ ich dane treningowe nie są publikowane. Oceniamy egzaminy, nie wiedząc, co student studiował.
Tutaj rozumie się, dlaczego ARC-AGI wybrał drogę, którą wybrał. Interaktywne, nowatorskie środowisko, bez instrukcji w języku naturalnym i zaprojektowane, aby zapobiec brutalnemu zapamiętywaniu, jest z natury odporne na kontaminację.
Więc, co powinniśmy mierzyć, aby ocenić inteligencję maszyn?
Czynnik g to właściwość populacyjna, która, zastosowana do modeli dzielących architekturę i zbiór, niesie ryzyko mierzenia skali obliczeń, a nie ogólności. Lekcja dla kogokolwiek budującego sztuczne systemy nie polega na wyborze między czynnikiem g a ARC-AGI, jakby były rywalizującymi drużynami. Chodzi o zrozumienie, jakie pytanie odpowiada każdy z nich. Analiza czynnikowa może być użyteczna do opisania wewnętrznej struktury wydajności systemu, o ile pierwszy czynnik nie jest mylony z esencją inteligencji. A protokół typu ARC jest niezbędny do tego, co naprawdę ma znaczenie: sprawdzenia, czy system generalizuje poza to, co widział, czy tylko recytuje.
Kiedy oceniamy system tylko po jego ostatecznej odpowiedzi, mierzymy go z zamkniętymi oczami na jego wymiar czasowy: planowanie, aktualizowanie przekonań, integrowanie dowodów przez wiele kroków. To dokładnie to, co postanowiło oceniać ARC-AGI-3, i dokładnie to, czego statyczny egzamin nie może dostrzec.

Dlaczego architektury AI inspirowane mózgiem, takie jak Neuraxon, idą inną drogą
Jeśli inteligencja nie jest przechowywaną liczbą, ale efektywną integracją wyspecjalizowanych podsystemów, jak sugeruje teoria integracji parieto-frontalnej (P-FIT) i globalna dostępność miejsca pracy w mózgu...
Jeśli ta integracja to przede wszystkim zjawisko czasowe, ze skalami czasowymi...
Wtedy system zbudowany na modułowych architekturach z funkcjonalnymi sferami, plastycznością na wielu skalach czasowych i ciągłą dynamiką nie musi być oceniany, prosząc go o recytowanie odpowiedzi.
Prawidłowe pytanie nie brzmi, ile benchmarków pokonuje, ale z jaką efektywnością nabywa nowe zachowanie w czasie, w środowiskach, na które nie był przygotowany. To kierunek, w którym Neuraxon stara się podążać. Obliczać czas – to znaczy adaptację – a nie zapamiętane odpowiedzi, które symulują bycie dobrym uczniem, kiedy w rzeczywistości już zna pytania.
Bibliografia
Chollet, F. (2019). O mierze inteligencji. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). Neuroscience różnic inteligencji ludzkiej. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Eksperymentalne i teoretyczne podejścia do przetwarzania świadomego. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Korelacje testów mentalnych ze sobą i z zmiennymi poznawczymi. Inteligencja.
Gignac, G. E., & Szodorai, E. T. (2024). Definiowanie i identyfikowanie ogólnego czynnika zdolności w systemach AI.
Guttman, L. (1955). Determinacja macierzy wyników czynnikowych z implikacjami dla pięciu innych podstawowych problemów teorii czynników wspólnych. British Journal of Statistical Psychology.
Hernández-Orallo, J., i in. (2021). Ogólna inteligencja odseparowana za pomocą metryki ogólności dla inteligencji naturalnej i sztucznej. Scientific Reports.
Honey, C. J., i in. (2012). Powolna dynamika korowa i akumulacja informacji na długich skalach czasowych. Neuron, 76(2), 423–434.
Ilić, D. (2023). Odkrywanie ogólnego czynnika inteligencji w modelach językowych: podejście psychometryczne. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). Teoria integracji parieto-frontalnej (P-FIT) inteligencji. Behavioral and Brain Sciences.
Spearman, C. (1904). "Ogólna inteligencja" obiektywnie określona i zmierzona. American Journal of Psychology, 15, 201–293.
Roberts, M., i in. (2024). Dowody czasowe kontaminacji z dat granicznych treningu.
Schönemann, P. H. (2008). Odpowiedź na Mackintosha i kilka uwag na temat pojęcia ogólnej inteligencji. arXiv:0808.2343.
Xu, C., i in. (2024). Kontaminacja danych benchmarkowych dużych modeli językowych: przegląd.
Yang, S., i in. (2023). Przemyślenie benchmarków i kontaminacji dla modeli językowych z przefrazowanymi próbkami.
Zhu, Q., i in. (2024). Dekontaminacja w czasie wnioskowania: ponowne wykorzystanie wyciekłych benchmarków do oceny LLM. Wyniki EMNLP 2024.
ARC Prize (2025). ARC-AGI-3: interaktywny benchmark rozumowania. Raport techniczny.
Zbadaj pełną serię Akademii Inteligencji Neuraxon
To jest Tom 10 Akademii Inteligencji Neuraxon od Zespołu Naukowego Qubic. Jeśli dopiero do nas dołączasz, zapoznaj się z całą serią, aby zbudować pełne zrozumienie nauki stojącej za Neuraxon, Aigarth i podejściem Qubic do zdecentralizowanej sztucznej inteligencji inspirowanej mózgiem:
NIA Tom 1: Dlaczego inteligencja nie jest obliczana w krokach, ale w czasie — Bada, dlaczego inteligencja biologiczna działa w czasie ciągłym, a nie w dyskretnych krokach obliczeniowych, jak tradycyjne LLM-y.
NIA Tom 2: Dynamika ternarna jako model inteligencji żywej — Wyjaśnia dynamikę ternarną i dlaczego logika trzech stanów (pobudzająca, neutralna, hamująca) ma znaczenie w modelowaniu systemów żywych.
NIA Tom 3: Neuromodulacja i AI inspirowana mózgiem — Zawiera neuromodulację i jak chemiczne sygnalizowanie mózgu (dopamina, serotonina, acetylocholina, norepinefryna) inspiruje architekturę Neuraxon.
NIA Tom 4: Sieci neuronowe w AI i neurobiologii — Dogłębne porównanie biologicznych sieci neuronowych, sztucznych sieci neuronowych i trzeciej drogi Neuraxon.
NIA Tom 5: Astrocyty i AI inspirowana mózgiem — Jak bramkowanie astrocytów przekształca plastyczność sieci neuronowych poprzez framework AGMP w Neuraxon.
NIA Tom 6: Świadome maszyny a inteligentne organizmy: wyjaśnienie świadomości AI — Bada świadomość AI przez pryzmat Teorii Globalnego Miejsca Pracy, Zintegrowanej Teorii Informacji i kodowania predykcyjnego.
NIA Tom 7: Gra życia Conwaya, sztuczne życie i ekosystemy cyfrowe — Nauka stojąca za Qubic, Aigarth i emergentną złożonością Neuraxon oraz samoorganizowaną krytycznością.
NIA Tom 8: Krytyczność mózgu i współczynnik rozgałęzienia w sieciach neuronowych i sztucznych — Dlaczego współczynnik rozgałęzienia bliski 1 i samoorganizowana krytyczność są bioinspirowanymi zasadami projektowania w Neuraxon.
NIA Tom 9: Pochodzenie czynnika g: Od edukacji i neurobiologii do sztucznej inteligencji — Bada pochodzenie czynnika g w edukacji, neurobiologii i AI.
$Qubic to zdecentralizowana, otwarta sieć do eksperymentalnych technologii. Aby dowiedzieć się więcej, odwiedź qubic.org. Dołącz do dyskusji na X, Discordzie i Telegramie.