
An operator activity log I reviewed last week showed fourteen active robots and zero operator interactions for eleven days.
Tasks were queued.
Robots were available.
From the outside the deployment looked healthy.
But nobody was actually running it.
At first I assumed the operator had switched to automated management.
Set the parameters. Walked away. Let the system handle itself.
Then I checked the bond status.
Active. Current. No expiry flagged.
Then I checked the dispute queue.
Three unresolved disputes. No responses. Eleven days old.
The operator hadn't automated the deployment.
The operator had stopped showing up.
I started thinking of this as operator drift.
The gap between when an operator becomes inactive and when the network realizes the deployment is effectively abandoned.
ROBO tracks robot activity.
It tracks task completion.
It tracks bond status and verification receipts.
What it doesn't track cleanly is operator presence.
An operator can stop responding and the deployment continues.
Tasks queue.
Robots attempt work.
Receipts record completion.
Everything looks functional from the outside until a decision requires the operator who isn't there.
A dispute needs a response.
A bond approaches renewal.
A task falls outside the original spec.
That's when the drift becomes visible.
But by then days or weeks of work may have accumulated under a deployment nobody is actively managing.
I checked a few other operator logs after that.
The pattern appeared more often than I expected.
Not sudden abandonment.
Gradual disengagement.
Operators active daily become active weekly.
Then intermittently.
Then not at all while the deployment keeps running.
When I compared operator activity to dispute timelines, the pattern became clearer.
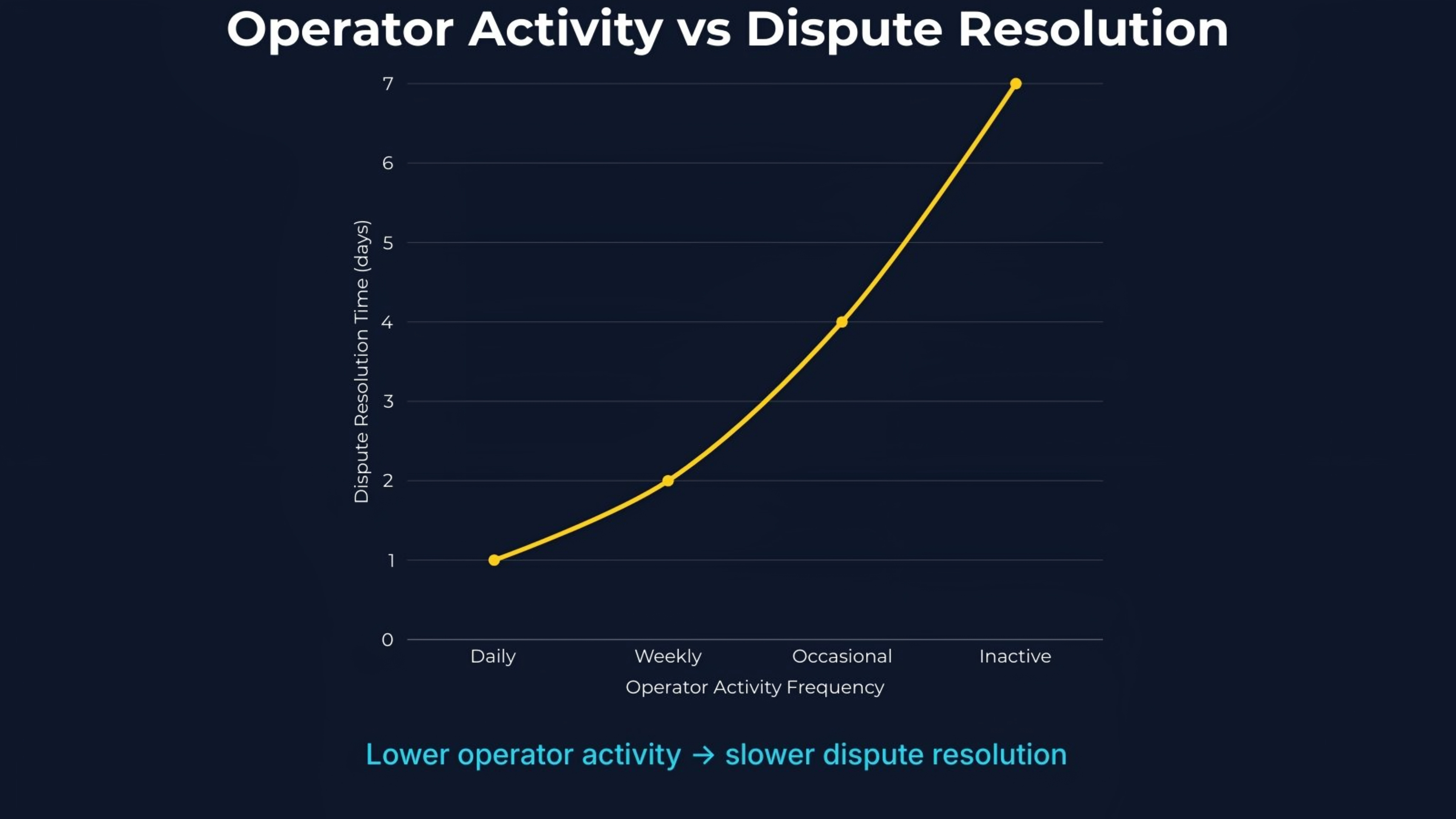
The cost shows up in three places.
First, dispute exposure.
Unanswered disputes age. Clients escalate. Resolution timelines stretch while robots continue working.
Second, bond risk.
Bonds approaching expiry without renewal create gaps the protocol has no clean way to resolve mid-deployment.
Third, task quality drift.
Without active oversight, edge cases accumulate and parameters stop adapting to new conditions.
Completion rates hold.
Dispute rates slowly rise.
I'm not certain this is a protocol failure.
Operator engagement is partly an economic signal.
If running a ROBO deployment remains profitable, operators stay present.
If margins compress or complexity rises, disengagement becomes rational.
But the direction concerns me.
The protocol assumes operators are present.
Real deployments don't always behave that way.
Fabric's operator infrastructure becomes important here.
The design determines whether drift becomes recoverable or catastrophic.
A network that detects drift early can reassign work and preserve the deployment.
A network that discovers it only after disputes age past response windows loses the deployment and the data it produced.
$ROBO only matters here if operator presence becomes something the network can observe and respond to.
Otherwise active operators and drifting operators look identical until something breaks.
The test is already available.
Pull operator interaction frequency across active ROBO deployments.
Sort by days since last operator action.
Then compare dispute age and resolution time.
If inactivity predicts slower dispute resolution and rising edge cases, operator presence is already a variable the protocol isn't measuring.
Still watching how the network reacts the first time a large deployment drifts past the point of recovery.
