
ほとんどの場合、私たちはAIの出力を提案として扱います。
彼らは自信があるように聞こえます。
彼らは構造化されているように見えます。
彼らはしばしば前進するのに十分良いと感じます。
それは良いことです—間違っていることのコストが抽象的でなくなってしまう瞬間までは。
ある時点で、AIに依存するすべてのシステムは同じ壁にぶつかります:「これは有用ですか?」と尋ねるのをやめ、「これが正しいことを証明できますか?」と尋ね始めます。
それがミラが踏み込もうとしている問題の領域です。
パフォーマンスではありません。
スピードでもありません。
モデルサイズでもありません。
信頼。
現代のAIは印象的ですが、それはまた滑りやすいものでもあります。文書を完璧に要約する同じシステムが、5分後に引用を幻覚することがあります。数学の問題を解決する同じモデルが、存在しないステップを自信を持って作り出すことがあります。低リスクのコンテキストでは、それは面倒です。高リスクのもの—財務、法律、インフラ、医療—では、受け入れられません。
ミラが構築しようとしているのは、まったく異なる姿勢です:出力を信頼せず、主張を検証することです。
それは明白に聞こえます。しかし、そうではありません。
今日のほとんどのAIシステムは、回答の見た目の妥当性によって判断されます。ミラはそれを逆転させ、回答が独立したシステムによって分解、確認、合意されることができるかどうかを尋ねます—社会的にではなく、暗号的および経済的に。
それは機械知能について考える非常に異なる方法です。
AIの応答を「知識」の単一のブロックとして扱うのではなく、ミラはそれを主張の束として扱います。各主張は検査可能です。各主張は挑戦可能です。各主張は他のモデルやネットワークの参加者によって検証または拒否されることができます。
そして、重要なのは、これは単なる技術的な演習ではなく、インセンティブ設計の問題です。
ほとんどのシステムでは、自信を持って間違っていることに実際のコストはありません。モデルは何も失いません。プラットフォームもそうです、関与が高い限り。ミラのアプローチは、AIパイプラインから欠けていたものを導入します:正確さに結びついた結果です。
道徳的な意味ではありません。経済的な意味です。
結果が検証可能な主張に対して合意を報酬し、不正確なものに対して罰を与えるネットワークを通じて検証される場合、システムは物語を語る者のように振る舞うのではなく、監査人のように振る舞い始めます。時間が経つにつれて、どのような出力が最初に生み出す価値があるのかが変わります。
ここでブロックチェーン層が重要です。
「ブロックチェーンがそれを分散化する」という抽象的な意味ではなく、それがシステムに、何が主張されたか、どのように評価されたか、ネットワークが何に合意したかの共有された改ざん防止メモリを与えるからです。
それは二つの理由で重要です。
まず、検証が一時的ではないことを意味します。何かが確認されたと信じるだけでなく、それが確認されたこと、そしてどのようなルールの下で確認されたかを見ることができます。
第二に、それは信頼が評判的ではなく手続き的になることを意味します。あなたは一つの会社のモデル、一つのAPI、一つの権威に頼るのではなく、複数の独立した参加者が正直である経済的理由を持つプロセスに頼ります。
ここにはより深い変化が隠れています。
今日のほとんどのAI製品は、便利さを最優先し、修正を後回しにするという考えに基づいて構築されています。あなたは素早く答えを得ます。それが間違っている場合、下流で修正します。人間が検証層になります。
ミラはそれを逆転させようとしています:検証が生産経路の一部になり、清掃ステップではなくなります。
それは場合によっては遅くなります。
より慎重です。
より構造化されています。
しかし、それはまた、人間のレビューが決してできない方法で信頼をスケールします。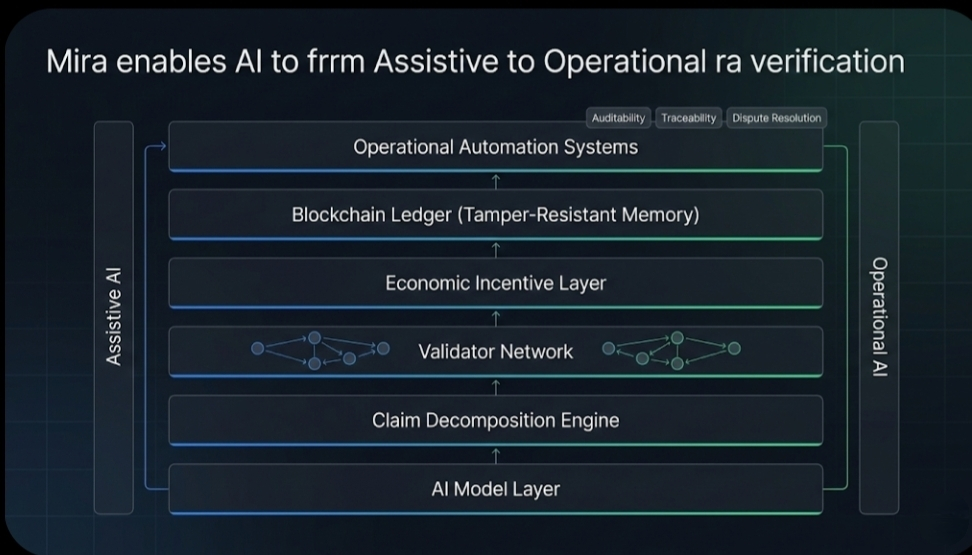
それが可能にすることを考えてください。
より賢く感じるチャットボットではありません。
しかし、出力が生成されるだけでなく、防御されているため、安全に意思決定を自動化できるシステムです。
正しく聞こえる内容ではありません。
しかし、主張に分解でき、部分ごとに証明できる内容です。
判断を置き換えるAIではありません。
しかし、判断がプロトコルによって強制されるフレームワーク内で動作するAIです。
これは、AIが重要なワークフローに近づくにつれて特に関連があります。モデルがコンプライアンス、財務管理、インフラ調整、または法的推論に触れ始めると、「おそらく正しい」は受け入れられなくなります。出力層自体に監査可能性、追跡可能性、および紛争解決が組み込まれている必要があります。
ミラのデザインの方向性は、それを理解していることを示唆しています。
モデルをより説得力のあるものにする方法を尋ねるのではなく、システムをより説明責任のあるものにする方法を尋ねています。
それはより静かな野望です。
しかし、それはより持続的なものです。
ここには文化的な含意もあります。
AIの出力が検証を生き残るべき主張として扱われるなら、エコシステム全体がシフトします。開発者はプロンプトを異なる方法で設計し始めます。アプリケーションはタスクを異なる方法で構成し始めます。ユーザーは単に回答ではなく理由を期待し始めます。
時間が経つにつれて、「良いAI」が何を意味するかが変わります。
滑らかではありません。
流暢さが増すわけではありません。
しかし、より防御的です。
そして、防御性は自動化が「支援的」から「運用的」に移行することを可能にします。
ミラはAIの人気コンテストに勝とうとしているようには感じません。
それは、より退屈でありながら、より重要なものを構築しようとしているように感じます:機械生成の真実のための信頼性層です。
それが機能すれば、影響は派手なデモとして現れません。
それは、組織が各ステップの後に人間のチェックポイントを追加せずにAIの出力を信頼し始めるときに現れます。
そして、それがAIが監督するツールでなくなり、実際に委任できるシステムになるときです。
それがより賢いからではありません。
しかし、最終的には検証可能だからです。
