
Va bene, quindi... continuo a rimanere bloccato sulla parola "qualità" con @OpenLedger .
Non perché sia sbagliato.
Perché suona troppo calma. In realtà...
La qualità sembra calma finché non immagino la scheda di validazione aperta alle 2 di notte, una riga del Datanet di OpenLedger segnalata, e nessuno è sicuro se sia rumore o l'unica cosa brutta e utile nel batch.
La gente dice che un'IA migliore ha bisogno di dati migliori, come se quella frase risolvesse qualcosa. Dati migliori. Dati più puliti. Dati verificati. Dati specifici del dominio. Bene. Meraviglioso. Ora metti quella frase in un Datanet e chiedi a qualcuno di decidere cosa merita davvero di addestrare un modello.
È lì che la versione carina inizia a sudare.
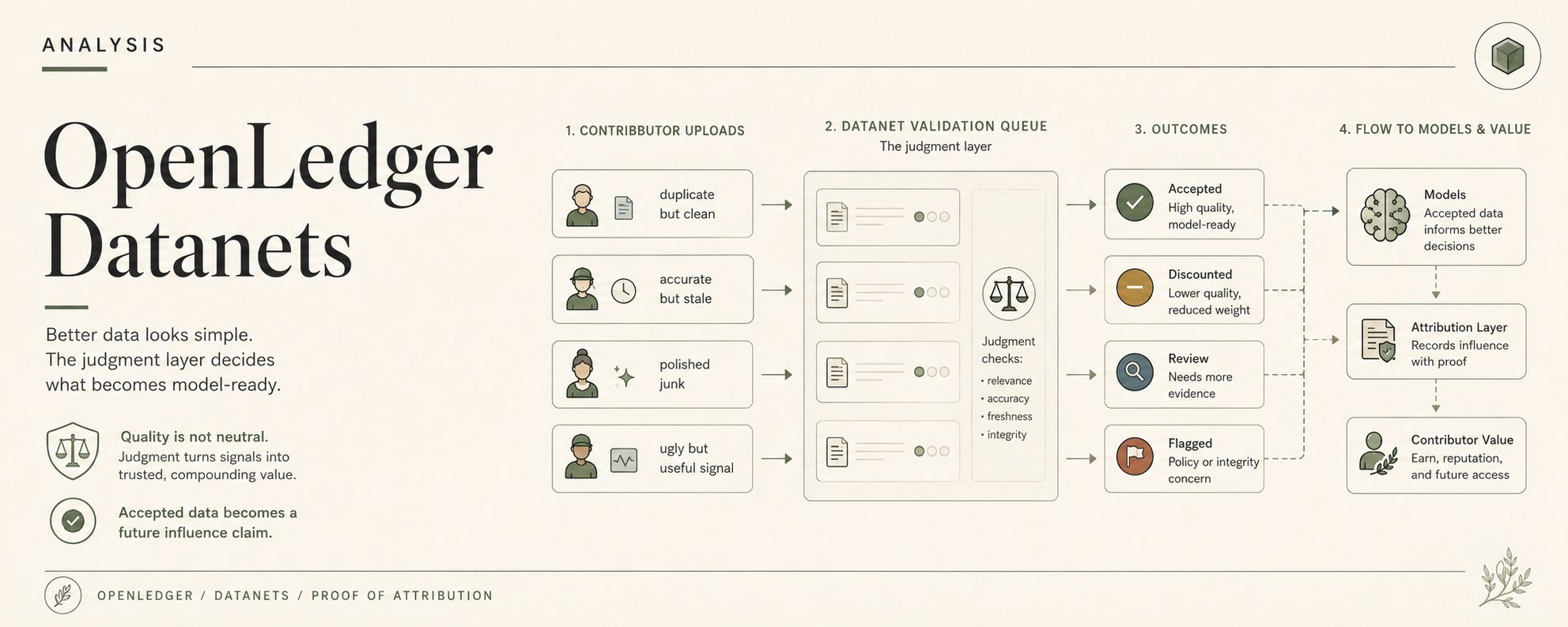
Un Datanet non è solo una cartella con ambizione su OpenLedger. Raccoglie dati di dominio, sì, ma poi iniziano le parti brutte. Validazione. Storia di contribuzione. Reputazione del contribuente. La questione di se questa riga dovrebbe mai arrivare all'addestramento, recupero, fine-tuning o inferenza successiva.
Sembra pratico.
È pratico.
Questo è il problema.
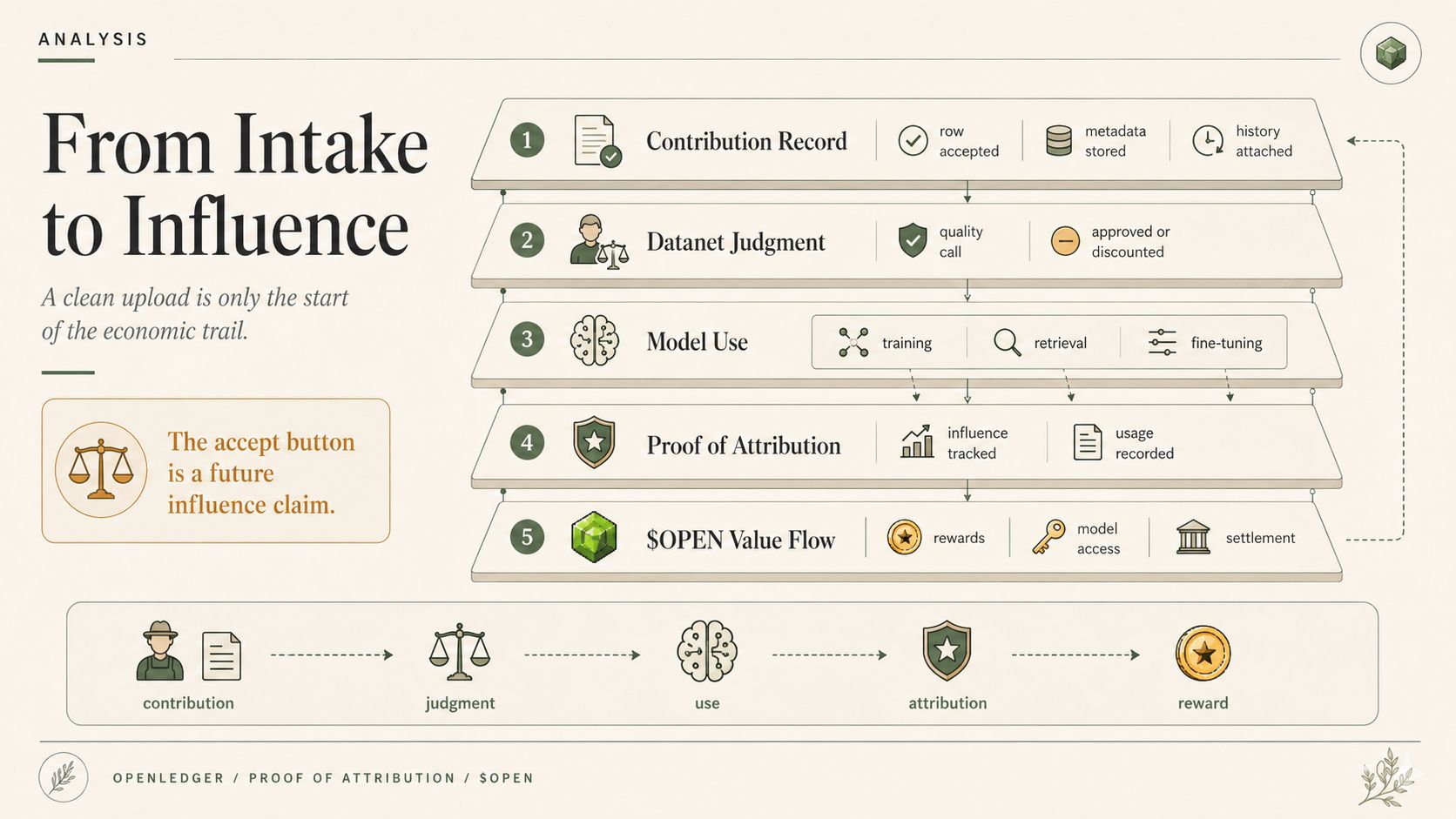
Perché una volta che i dati diventano utilizzabili, OpenLedger deve smettere di trattarli come un file e iniziare a trattarli come una futura rivendicazione di influenza.
Non nel senso carino della comunità.
Nel senso di "questo contributo può plasmare il comportamento del modello e forse guadagnare attraverso la Proof of Attribution in seguito".
Umorismo diverso.
Comunque.
Continuo a immaginare un Datanet costruito per i dati di rischio DeFi. I contribuenti iniziano a inviare note sugli incidenti di protocollo, cronologie di liquidazione, etichette di sfruttamento, casi di debito cattivo, esempi di stress di mercato, registrazioni di fallimento degli oracle, forse annotazioni di rischio di governance se tutti vogliono soffrire per bene. Gli upload sembrano utili. Metadata abbastanza puliti. Categorie riempite. Timestamp presenti. Forse una linea di reputazione del contribuente già seduta accanto alla sottomissione come una minaccia silenziosa.
La coda di validazione fa quello che fanno i dashboard. Campi verdi, controlli in attesa, un avviso che nessuno vuole cliccare perché cliccare significa che la giornata si allunga.
Bene.
Ora ordina.
Non filosoficamente. Nel flusso di contribuzione Datanet di OpenLedger. Accetta, sconta, segnala, penalizza, instrada alla revisione, forse lascia che la reputazione inclini la prima lettura. Tutto molto pulito fino a quando una brutta sottomissione è l'unica che ha effettivamente catturato il vero caso limite.
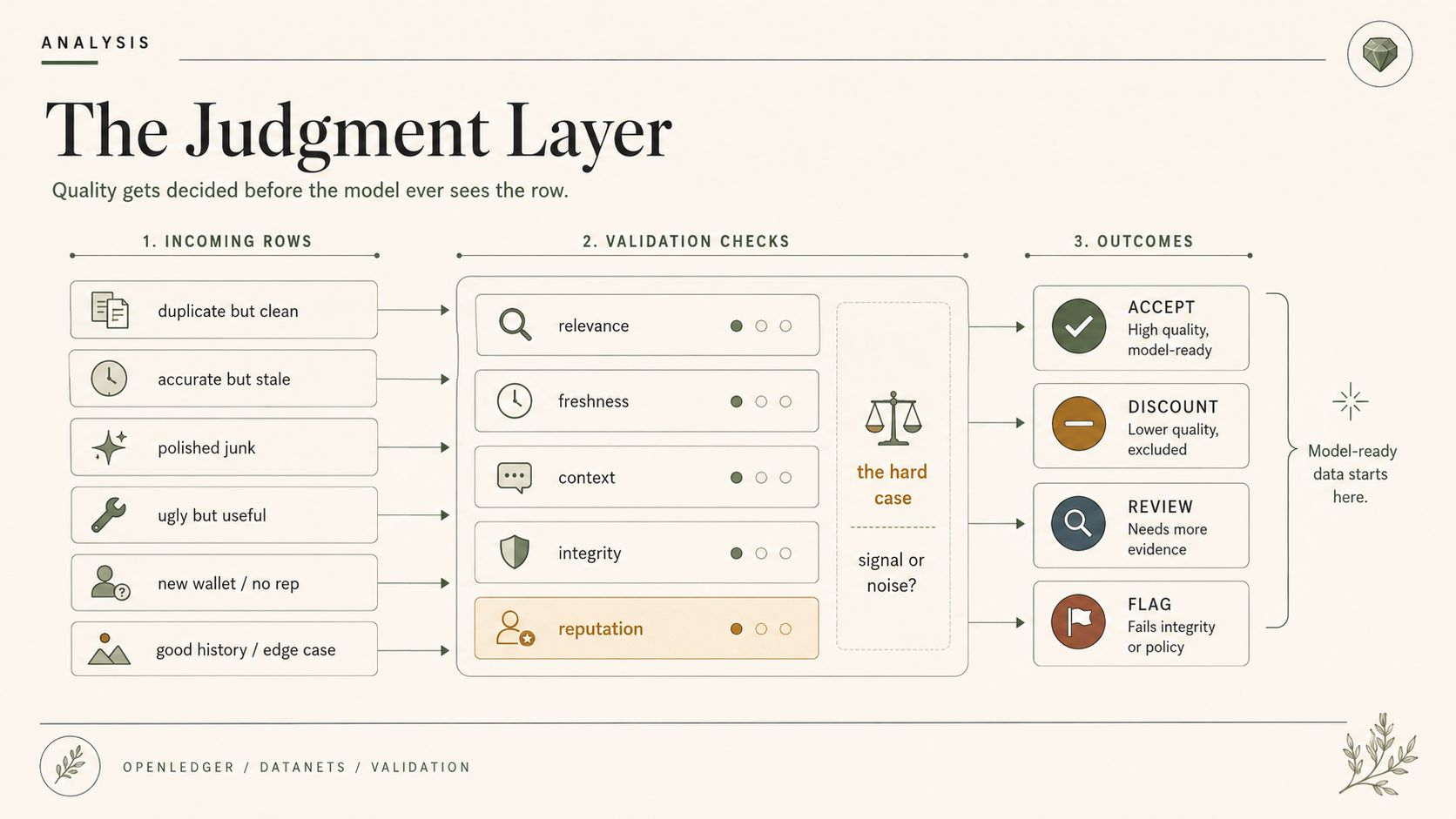
Un'entrata è utile ma duplicata. Una è accurata ma obsoleta. Una è tecnicamente corretta ma manca del contesto di mercato che ha reso l'evento importante. Una sembra lucida ma è fondamentalmente spazzatura con una formattazione migliore. Una ha un segnale reale sepolto sotto note brutte. Una proviene da un contribuente con una buona storia. Un'altra proviene da un nuovo wallet senza storico di reputazione. Bene. Ottimo persino. Dati migliori, apparentemente. Buongiorno.
Questa è la pressione del Datanet su OpenLedger che appiattisce troppo rapidamente.
OpenLedger sta cercando di evitare il solito pasticcio dell'IA dove i modelli mangiano metà di Internet e nessuno sa cosa ci sia dentro. I Datanet spingono nella direzione opposta: dati più ristretti, maggiore provenienza, maggiore responsabilità dei contribuenti, percorsi di utilizzo più puliti. Questo è utile.
Ma dati più ristretti rendono anche il giudizio più preciso.
Perché un'analisi generale può nascondere input scadenti nel pantano. Un Datanet non può nascondere così facilmente. Se il Datanet deve alimentare un modello specializzato, allora ogni contributo accettato inizia a sembrare più responsabile. Non moralmente. Operativamente. Il modello può addestrarsi su di esso. Un workflow di OpenLedger ModelFactory può selezionarlo. Un adattatore OpenLoRA può successivamente specializzarsi attorno agli output plasmati da esso. La Proof of Attribution può eventualmente collegare quei dati al valore.
Ciò significa che il pulsante di accettazione non sta solo dicendo "abbastanza buono per il dataset." Sta silenziosamente creando una possibile rivendicazione futura di influenza.
Va bene.
Qualche costruttore in ModelFactory non vede nemmeno l'intero argomento. Vedono un dataset approvato, forse un'etichetta Datanet, forse abbastanza fiducia per andare avanti. Bellissimo. La lotta per l'ingresso è appena diventata materiale di addestramento.
Quindi il passo di validazione su OpenLedger smette di essere amministrativo.
Inizia a sembrare comportamento del modello prima ancora che il modello venga eseguito.
Quella parte mi infastidisce.
Ho visto questo umore nelle sale dati. Nessuno dice "stiamo plasmando gli errori futuri del modello." Dicono "questa riga è più pulita," e in qualche modo sembra abbastanza responsabile.
Un contribuente pensa di inviare dati. Il Datanet sta in realtà decidendo se quei dati meritano di diventare parte dello spazio delle risposte future. Sembra drammatico. Non lo è. È solo ciò che accade quando i dati non sono più una semplice archiviazione morta.
Se una cattiva sottomissione viene rifiutata, va bene. Facile.
Se una sottomissione malevola viene penalizzata, va bene. Più pulito.
I casi più difficili sono quelli normali. Dati che sono a metà utili. Dati che sono utili solo in un contesto ristretto. Dati che ripetono un modello esistente ma lo confermano bene. Dati che confliggono con un'altra fonte e costringono il Datanet di OpenLedger a scegliere quale versione diventa "pronta per il modello". Non si tratta di raccolta di spazzatura. Si tratta di curatela con conseguenze economiche.
E su OpenLedger, quelle conseguenze non rimangono all'interno dello schermo di upload.
Questa è la parte che fa sembrare il Datanet più pesante.
Un registro di contribuzione può seguire il contributore. La reputazione può plasmare come vengono trattate le future sottomissioni. La Proof of Attribution può poi decidere se quei dati accettati hanno influenzato un'inferenza. $OPEN può poi muoversi attraverso utilizzo, ricompense, accesso al modello, gas e liquidazione come se la decisione di ingresso fosse stata ovvia tutto il tempo. Quindi quando un Datanet accetta o sconta dati, non sta solo pulendo un dataset. Sta silenziosamente plasmando chi viene fidato in seguito, chi viene pagato in seguito e quale versione della realtà il modello è autorizzato a imparare.
Una bella macchinetta per ordinare.
Molto democratico fino a quando la riga rifiutata apparteneva a te.
So già la risposta pulita. Governance della comunità. Flussi di validazione. Reputazione del contribuente. Logica delle penalità. Storia di contribuzione su OpenLedger. Sì. Va bene. Macchinari necessari. Senza di essi, i Datanet diventano fattorie di upload con un marchio IA attaccato alla porta.
Ancora.
Quegli stessi strumenti creano un altro strato di potere.
Perché il controllo della qualità non è neutrale una volta che esistono ricompense. Se i contribuenti sanno che i Datanet premiano un'influenza utile in seguito, iniziano a ottimizzare per l'accettazione. Formattando in modo più pulito. Imitano esempi approvati. Evitano casi limite strani perché i casi limite strani sembrano rischiosi. Presentano dati che sembrano pronti per il modello invece di dati che catturano la brutta verità del dominio.
È lì che la qualità inizia a diventare strana.
Il Datanet potrebbe diventare più pulito e meno onesto allo stesso tempo.
Non sempre. Non automaticamente. Ma abbastanza da farmi fissare il layer di validazione più a lungo del pulsante di upload.
E sì, odio che sia qui che finisco. Non al modello. Non all'agente. Alla riga di ingresso. Un lavoro molto glamour, fissare una riga e chiedersi se diventa la risposta futura di qualcuno.
Un vero dominio è disordinato. Gli incidenti DeFi non arrivano come etichette pulite. I dati sulla salute non arrivano senza caveat. I dati legali non arrivano senza sporcizia giurisdizionale. Il comportamento del mercato non si adatta in modo ordinato perché i mercati sono per lo più umani che creano sciocchezze costose in sequenza. Se il Datanet premia contributi puliti, riutilizzabili e facilmente validati troppo aggressivamente, i dati grezzi ma importanti iniziano a sembrare come un cattivo cittadino.
E così un dataset può diventare di alta qualità in modo tale da rendere il modello leggermente meno preparato per la realtà.
Bellissimo.
Il modello risponde in seguito con fiducia perché il Datanet sottostante è stato curato in modo da avere fiducia.
Quando un adattatore OpenLoRA serve quel comportamento ristretto, la brutta decisione di ingresso non sembra più brutta. Sembra specializzazione.
Questa è la cicatrice.
Non ci sono dati cattivi in entrata. Tutti vedono quel rischio.
La peggiore è la spazzatura utile che viene filtrata perché rende più difficile governare il Datanet, più difficile validare, più difficile premiare, più difficile trasformare in un percorso di attribuzione pulito.
L'architettura di OpenLedger rende questo visibile perché il layer dei dati non è nascosto dietro un black box. Datanets, registri di contribuzione, reputazione, Proof of Attribution, utilizzo del modello, percorsi di ricompensa. Il sistema sta fondamentalmente dicendo: mostra la catena di approvvigionamento. Bene. Finalmente.
Ma una volta che la catena di approvvigionamento è visibile, anche il layer di giudizio diventa visibile.
Chi ha chiamato questo utile?
Chi ha segnato questo come ridondante?
Chi ha penalizzato la fonte strana?... Qualunque cosa.
Chi ha lasciato passare la spazzatura che sembra pulita?
Chi ha deciso che questi dati erano abbastanza pronti per il modello da influenzare un'inferenza futura?
Nessuno può fingere che il modello abbia semplicemente "imparato."
Va bene.
Il Datanet gli ha insegnato cosa era permesso.
E su OpenLedger, questa è la parte scomoda. I Datanet non alimentano solo i modelli. Preconfigurano ciò che la Proof of Attribution può successivamente premiare, ciò che ModelFactory considera materiale di addestramento sicuro, ciò intorno a cui gli adattatori OpenLoRA possono specializzarsi, e ciò che $OPEN alla fine si stabilisce come contributo utile. Quindi il layer di giudizio non è al di fuori dell'economia dell'IA. È seduto prima di essa, decidendo silenziosamente cosa l'economia può contare. Un ottimo posto per nascondere il potere. Proprio all'ingresso.
Ecco perché non compro la versione soft in cui i Datanet risolvono semplicemente il garbage in, garbage out. Non lo risolvono come un filtro per rifiuti. Spostano la lotta prima. Prima dell'addestramento. Prima dell'inferenza. Prima della risposta. Nel posto in cui i contribuenti, i validatori, le regole di reputazione e le aspettative di ricompensa decidono che tipo di dati diventano legittimi.
Forse è meglio così.
Probabilmente è meglio.
Ancora non pulito.
Perché nel momento in cui un Datanet inizia a decidere cosa conta come qualità, sta già curando gli errori futuri del modello.
Non solo la sua futura accuratezza.
Anche i suoi errori.
E più tardi, quando il modello dice qualcosa con fiducia, forse la Proof of Attribution di OpenLedger può mostrare il percorso, magari la logica delle ricompense può mostrare chi ha contribuito, forse la storia del Datanet può mostrare cosa è stato accettato.
Va bene.
Ma da qualche parte prima di tutto ciò, qualcuno ha guardato una brutta contribuzione e ha deciso se il pasticcio fosse segnale o solo rumore con una giacca sporca.
Quella decisione è ancora seduta dentro la risposta.
Output pulito. Decisione sporca del Datanet. Stesso modello.
E se la Proof of Attribution paga il percorso in seguito, il percorso inizia da quella chiamata di ingresso.
Un bel posto per un errore che diventa infrastruttura.