Ich denke, eine der größten Fragen in der KI ist nicht nur „Wer hat das Modell gebaut?“, sondern „Wessen Daten haben dem Modell geholfen, nützlich zu werden?“
Diese Frage blieb in meinem Kopf, als ich auf @OpenLedger schaute.
Die meisten KI-Modelle werden nicht durch Zauberei nützlich. Sie brauchen Daten. Sie brauchen Beispiele. Sie brauchen Signale von echten Menschen, echten Gemeinschaften und echten Anwendungsfällen. Aber das Merkwürdige ist, dass der Datenbeitragsleister oft in den Hintergrund gedrängt wird, sobald das Modell beginnt, Wert zu schaffen.
Ich denke, das ist eine ernsthafte Lücke.
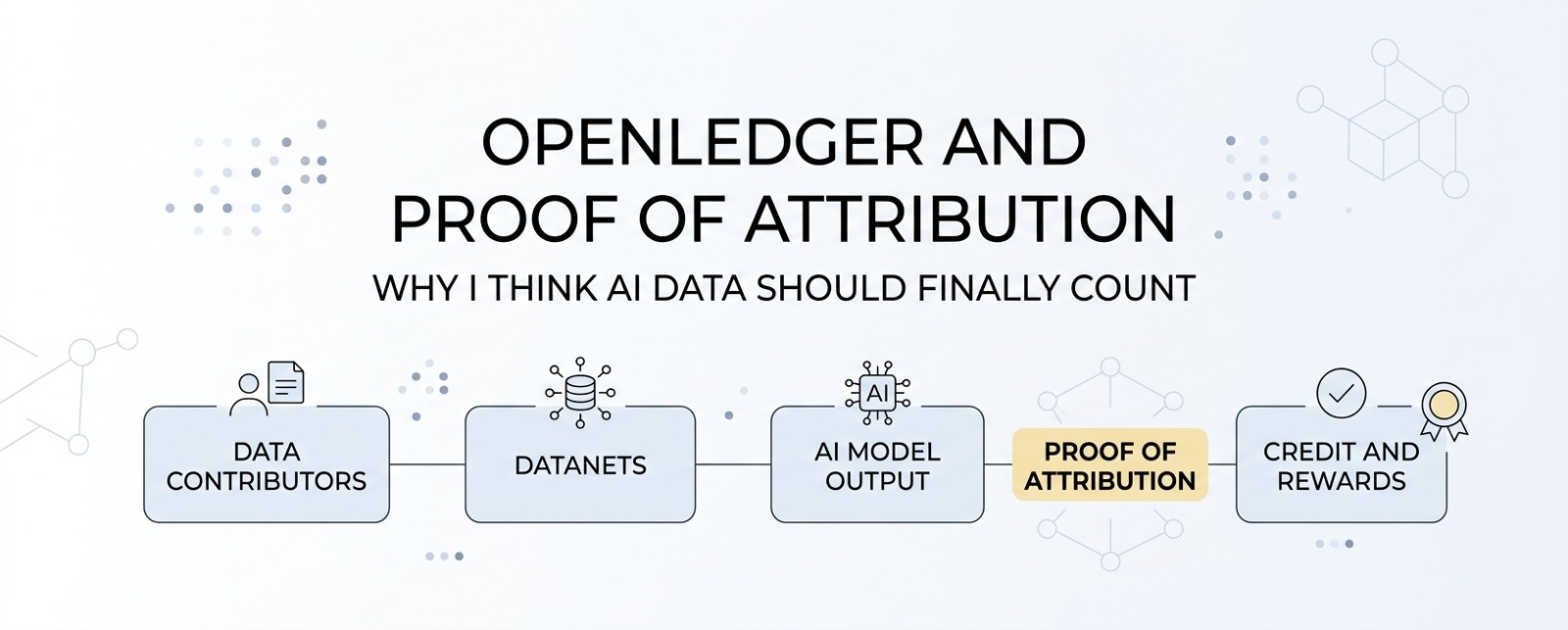
Openledger versucht, diese Lücke mit einem KI-Blockchain-System zu schließen, das um gemeinschaftlich besessene Datensätze, die Datanets genannt werden, aufgebaut ist. Ich sehe Datanets als fokussierte Datenpools, in die Menschen nützliche Informationen für spezialisierte KI-Modelle einbringen können. Das ist wichtig, weil allgemeine Daten nicht immer ausreichen. Einige KI-Anwendungsfälle benötigen sauberere, tiefere und spezifischere Daten.
Hier wird der Nachweis der Attribution wichtig.
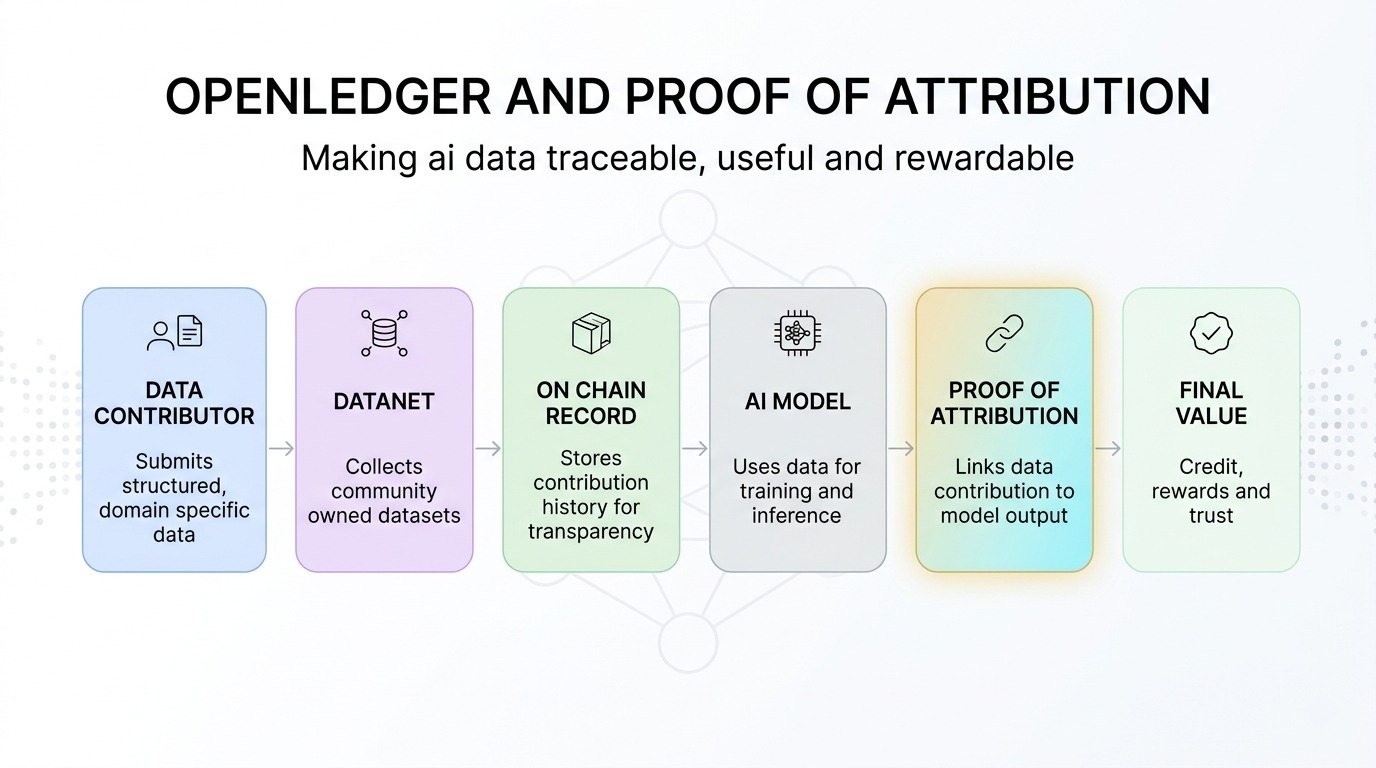
Für mich fühlt sich der Nachweis der Attribution wie ein Belegesystem für KI-Daten an. Es ist darauf ausgelegt, Datenbeiträge mit den Ausgaben des KI-Modells zu verbinden. Einfach gesagt, wenn eine Person nützliche Daten hinzufügt und diese Daten dem Modell helfen, besser zu arbeiten, zielt das System darauf ab, diesen Beitrag nachverfolgbar zu machen.
Ich mag diese Idee, weil sie unsere Sichtweise auf den Wert von KI verändert.
Heute reden viele Leute über Modelle, Token und Apps. Aber weniger Menschen sprechen über die Datenebene dahinter. Ich finde, die Herangehensweise von #OpenLedger ist interessant, weil sie den Mitwirkenden näher an die Wertschöpfungskette bringt. Sie behandelt Daten nicht als versteckte Ressource. Sie betrachtet Daten als etwas, das verifiziert, verfolgt und belohnt werden kann.
Das könnte auch die Datenqualität verbessern. Wenn Mitwirkende wissen, dass ihre Arbeit anerkannt werden kann, haben sie mehr Gründe, nützliche Daten anstelle von zufälligen Informationen bereitzustellen.
Trotzdem würde ich das nicht als einfaches Problem bezeichnen. Echte Datenbeeinflussung in KI nachzuvollziehen, ist schwierig. Die Idee klingt stark, aber der echte Test ist, ob Openledger die Attribution in großem Maßstab genau machen kann.
Für mich ist der Schlüsselpunkt einfach. Die Zukunft der KI sollte nicht nur den Modellbesitzer belohnen. Sie sollte auch die Menschen hinter den Daten anerkennen.