
The payout view looked fine.
That's what kept bothering me on @OpenLedger .
Not broken. Worse. Clean.
Too clean for what it was pretending to explain.
Because once contribution gets priced cleanly enough on OpenLedger, builders stop needing to cheat loudly. They can package quietly. Much nicer look.
That’s the version that sticks.
Because the polite OpenLedger story is clean. Datanets there. Retrieval there. Inference there. Proof of Attribution there. Contributor lineage there. Reward rows there. $OPEN settling around whatever PoA could still isolate cleanly enough to reward. Fine. AI with receipts. AI with memory. Everybody gets to feel slightly less robbed by the internet for ten minutes.
Good.
Then somebody bundles the thing.
Of course they do.
Thats where it starts smelling wrong.
Not some loud rug-pull version either. Worse. The respectable one. Payout view still valid. Attribution tab still opens. Money still lands where it was allowed to land. Nice. Very clean. A little too blended once you keep staring.
I keep coming back to that stupid little detail.
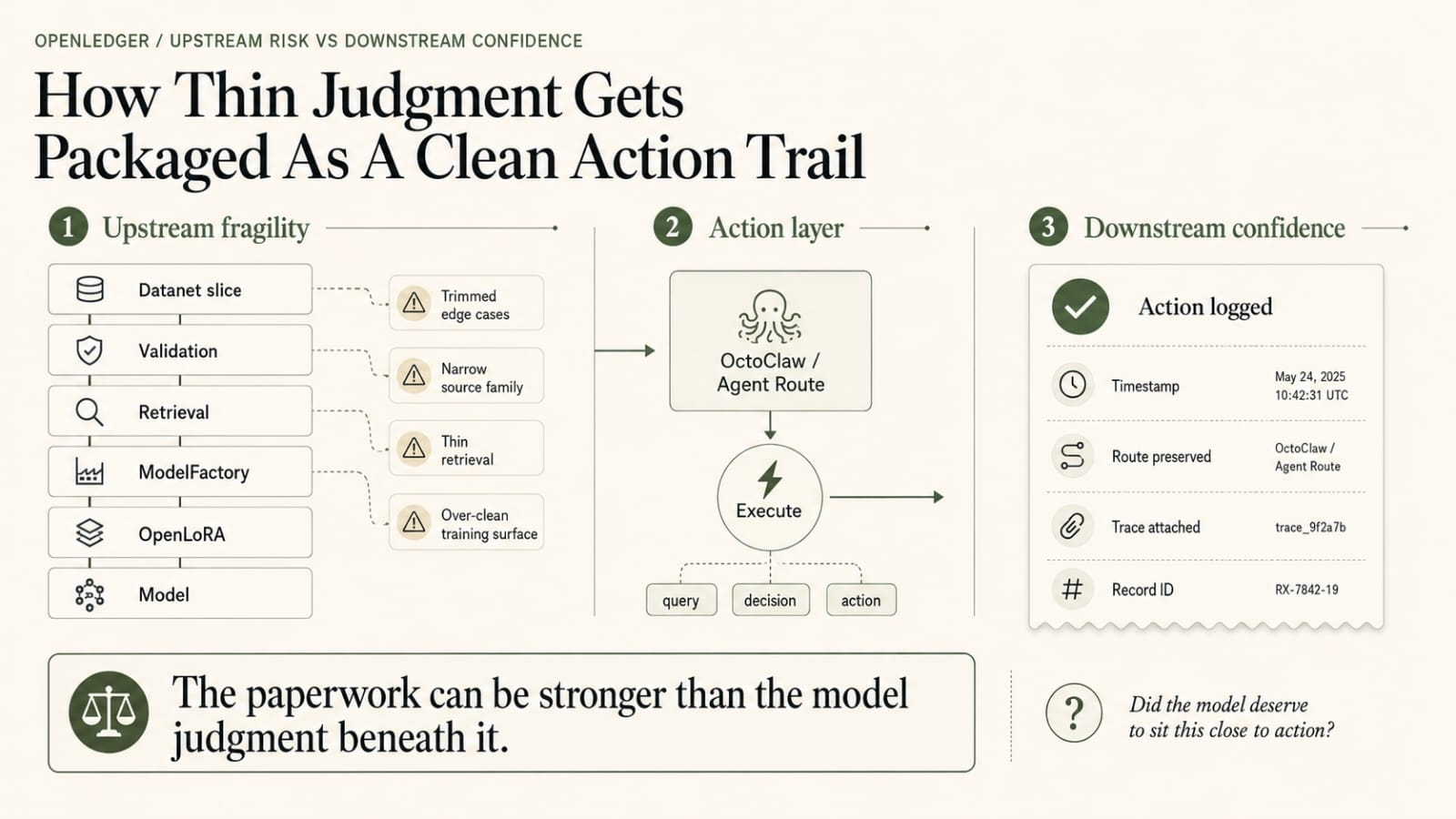
once OpenLedger makes contribution legible enough to price, the next instinct isn’t always to cheat loudly. Nobody with a functioning brain cheats loudly if they can package quietly. They bundle the clean contributors with the messy ones. Bundle the reusable retrieval logic with the model. Bundle one Datanet slice that was doing real expensive work with three other things that make the whole path look broader, safer, more collaborative, more respectable.
Same old instinct. Better paperwork.
And the same contributor IDs still keep bunching underneath the blended rows anyway.
Same cluster. Different wrapper. Cleaner story on top.
I don’t like how quickly that starts looking normal.
This isn’t generic metrics-gaming noise. The rows are tied to Datanets, retrieval, PoA, contributor lineage, and OPEN settlement. That’s why it gets uglier here. Datanets feed the build. Retrieval decides what actually shows up live. Inference generates the visible behavior. PoA traces what the machine can still see clearly enough. Then OPEN settlement turns that legibility into money. Once that stack is live, bundling stops being just packaging.
It becomes its own distortion layer.
Nice little one.
Say a builder has one model path doing most of the real work. Fine. Or most of the expensive work. Same thing here, really. Say one narrow retrieval pattern keeps carrying more of the useful answer load than the cleaner public story would like to admit. Fine. Imagine one contributor cluster inside a OpenLedger Datanet keeps surviving into the inference trace again and again. Also fine. Then instead of leaving the path ugly, specific, and economically obvious, the builder starts wrapping more around it. Another contributor set here. Another retrieval layer there. Another model wrapper or retrieval layer that’s technically real enough to include but not nearly as causally central as the expensive core underneath.
Now the payout still works.
That’s the annoying part. Nothing breaks loudly.
That’s what makes it rotten.
The money can still move. OpenLedger's PoA still points at things. Contributor lineage still exists. Reward rows still fill in. Nice little machine. Nothing necessarily breaks. The package is just cleaner than the actual retrieval load and contributor carry probably deserved.
I can already see the dumb little screen. Payout rows on one side. Attribution tab on the other. A bunch of contributors all technically present. A bunch of paths all technically involved. Everybody looks valid. Everybody looks included. Everybody gets their little share. Nice.
Flat little split too. Almost tasteful.
And the same retrieval path is still sitting under most of the value like nobody will notice.
Then you keep staring and one question starts needling through the whole thing. Bad sign usually.
I know that feeling too well at this point.
Which part was actually carrying this thing, and which parts got bundled in because OpenLedger pays cleaner when the contribution story looks broader than the expensive truth.
Which part was carrying it. Which part was decorative. Which part was there mostly so the payout geometry looked less embarrassing.
That’s the bit that keeps scraping at me.
Because OpenLedger doesn’t have to be wrong for this to happen. That’s the nastier version. The builder isn’t necessarily fabricating contribution. That would be easier. The extra pieces may really be there. The retrieval wrapper may really exist. The model stack may really include those additional paths. The contributor groups may really touch the output somewhere in the inference trace. Fine.
The problem isn’t that the package is fake.
That would be easier.
The problem is that bundling makes the expensive part harder for humans to point at?...while the OpenLedger's payout engine still has enough structure to make the rows look rigorous.
Useful little trick.
Rotten one too.
Say a builder knows one Datanet slice retrieves cleanly, survives into inference consistently, and keeps anchoring the answers people actually come back for. Good. That should probably get paid. But instead of leaving that core naked, they package it with adjacent contributors, cleaner metadata, broader retrieval framing in the live inference path, maybe a more reusable model story, maybe some extra path that keeps the output chain looking more diversified than the real economic center of gravity.
Now the payout split still looks civilized. The attribution tab still looks broad. The expensive spine gets harder to point at.
No screaming outlier. That’s the trick.
Different thing.
Worse thing, really.
Should bother more people than it seems to.
Because once contribution gets priced, people stop asking only “what helped.”
They start asking, quietly, “what can be grouped.”
Or hidden in plain sight.
Same basic move.
That’s where the system starts bending.
Not at the payout event exactly. Earlier. During design. During packaging. During the point where the builder already knows what kinds of contribution stories will look cleaner once Proof of Attribution and settlement come back around later. So they shape for that. Bundle for that. Smooth for that. The same way people always smooth for the later screen.
A messy core gets wrapped in cleaner edges.
A narrow retrieval dependency gets dressed up as a broader contribution surface.
A contributor set that was genuinely decisive gets economically diluted just enough that the package looks healthier than the causal spine really was.
And then everybody gets to point at the payout view and pretend the story was naturally this blended all along.
Even when the same contributor IDs are still doing most of the heavy lifting under the row view.
You can almost see the real spine trying to push through the blend.
Almost.
I don’t buy that.
I keep picturing one stupid practical version. Model goes live on OpenLedger. Inference starts stacking. Same answer family keeps showing up. Same retrieval path keeps carrying. Same contributor IDs keep appearing more than they probably should if the broader package were really doing equal work. Then somebody opens the payout rows and the package still looks decent because technically lots of things touched the path. Maybe they did. But “touched” isn’t the same as “carried,” and OpenLedger makes that difference more annoying because the system is close enough to real pricing that the dilution starts feeling deliberate even when it stays technically compliant.
That’s the rotten little sentence hiding in the machine.
Touched.
Not carried.
Everybody hides inside that difference.
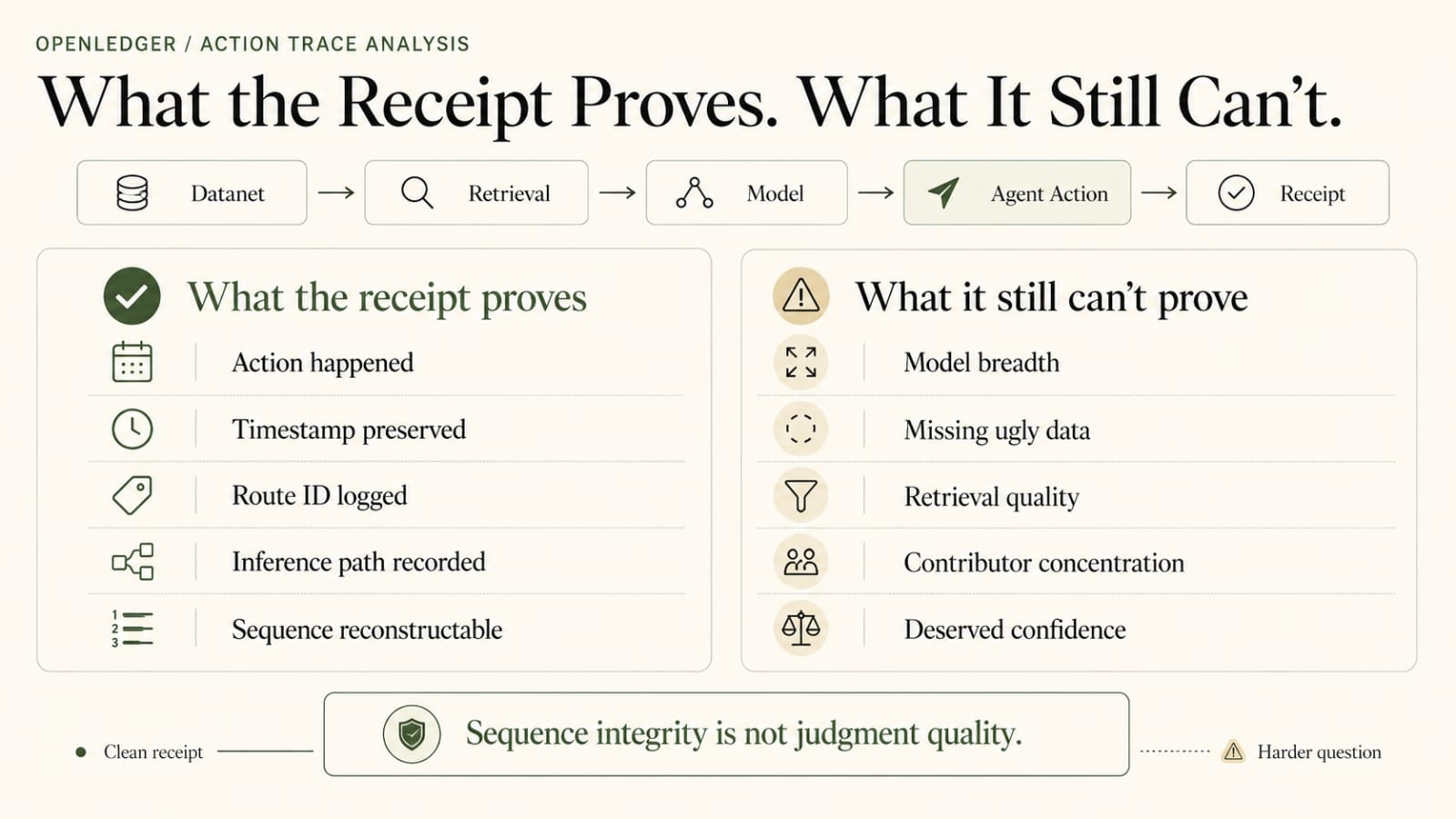
And once enough value starts moving through these bundled paths, the packaging starts teaching builders how to structure the next one. Of course it does. Keep the expensive spine. Wrap it in enough legitimate extras that the PoA story stays broad, the payout rows stay smooth, and nobody has to stare too hard at which Datanet slice, retrieval path, or contributor cluster was actually doing the heavy lifting. Nice design pattern. Very civil. Convenient too. Also a very good way to price contribution while slowly making the most important contribution harder to name.
That’s not theory.
That’s a row problem.
A payout-view problem.
An attribution-tab problem.
You can feel it in the interface before you can prove it cleanly.
I don’t like how often that’s enough.
And OpenLedger is exactly the kind of system where that discomfort matters. Because the whole point is that contribution should be traceable... and payable instead of disappearing into black-box sludge.
Good.
Then the uglier part starts. The system gets good enough at pricing value that builders start packaging the value path in ways that keep the money clean... while making the real contribution story harder to separate.
Because then OpenLedger is not just revealing who helped.
It’s teaching people how to package help into something cleaner than the expensive truth doing the real carrying underneath.
And once that starts happening, what exactly is Proof of Attribution proving.
Who contributed most.
Or who got packaged into the cleanest contribution story the payout rows could still settle without arguing.