
Die meisten KI-Projekte reden darüber, was Intelligenz tun kann.
@OpenLedger scheint mehr darauf fokussiert zu sein, wo die Intelligenz herkommt.
Diese Unterscheidung ist wichtig.
Ich habe genug Marktzyklen beobachtet, um skeptisch zu werden, wann immer ein Sektor zum Narrativ des Monats wird. Das Muster ändert sich selten. Ein neues Thema taucht auf, Kapital strömt rein, jeder fängt an, die gleichen Talking Points zu wiederholen, und schließlich erkennt der Markt, dass viele Projekte eine Geschichte verkauft haben, anstatt ein Problem zu lösen.
KI ist das dominante Narrativ heute.
Genau deshalb gehe ich mit Vorsicht an Projekte wie OpenLedger heran, anstatt begeistert zu sein.
Die KI-Präsentation ist einfach. Jedes Projekt erwähnt Modelle, Agenten, Daten, Automatisierung und maschinelle Intelligenz. Diese Worte alleine bedeuten nicht mehr viel.
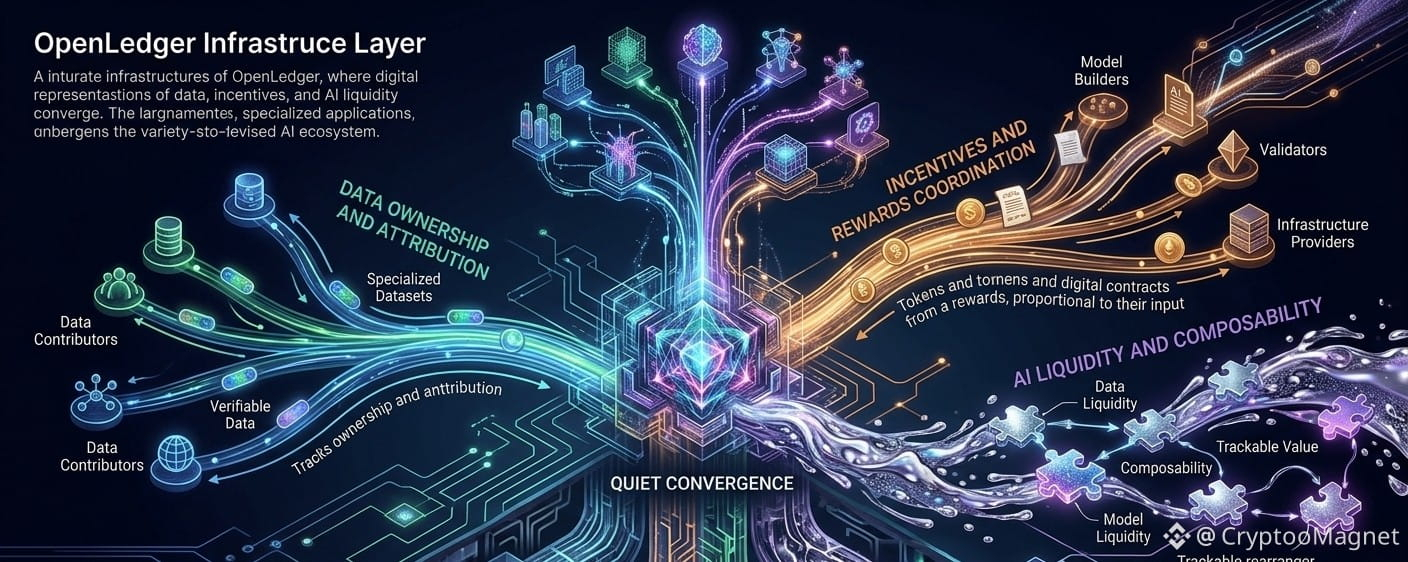
Was meine Aufmerksamkeit bei OpenLedger erregt hat, ist, dass es sich auf ein Problem konzentriert, das die meisten Menschen lieber ignorieren würden.
Die Beitragsschicht.
Moderne KI fühlt sich von außen einfach an. Man stellt eine Frage, erhält eine Antwort und macht weiter. Doch unter dieser Erfahrung liegt ein riesiges Netz von Datensätzen, Modelltraining, Feineinstellung, Abrufsystemen, Eingabeaufforderungen, Feedback-Schleifen und unzähligen Mitwirkenden, deren Rolle oft im Moment der Ausgabe verschwindet.
Hier beginnt die Reibung.
Wenn KI einen größeren Teil von Geschäft, Forschung, Finanzen, Software und Automatisierung einnimmt, werden Fragen zu Eigentum und Zuschreibung schwieriger zu vermeiden.
Wer hat die Daten bereitgestellt?
Wie wurde es verwendet?
Welche Inputs haben tatsächlich das Ergebnis beeinflusst?
Wer verdient eine Entschädigung, wenn Wert geschaffen wird?
Heute sind die meisten dieser Antworten in Black Boxes verborgen.
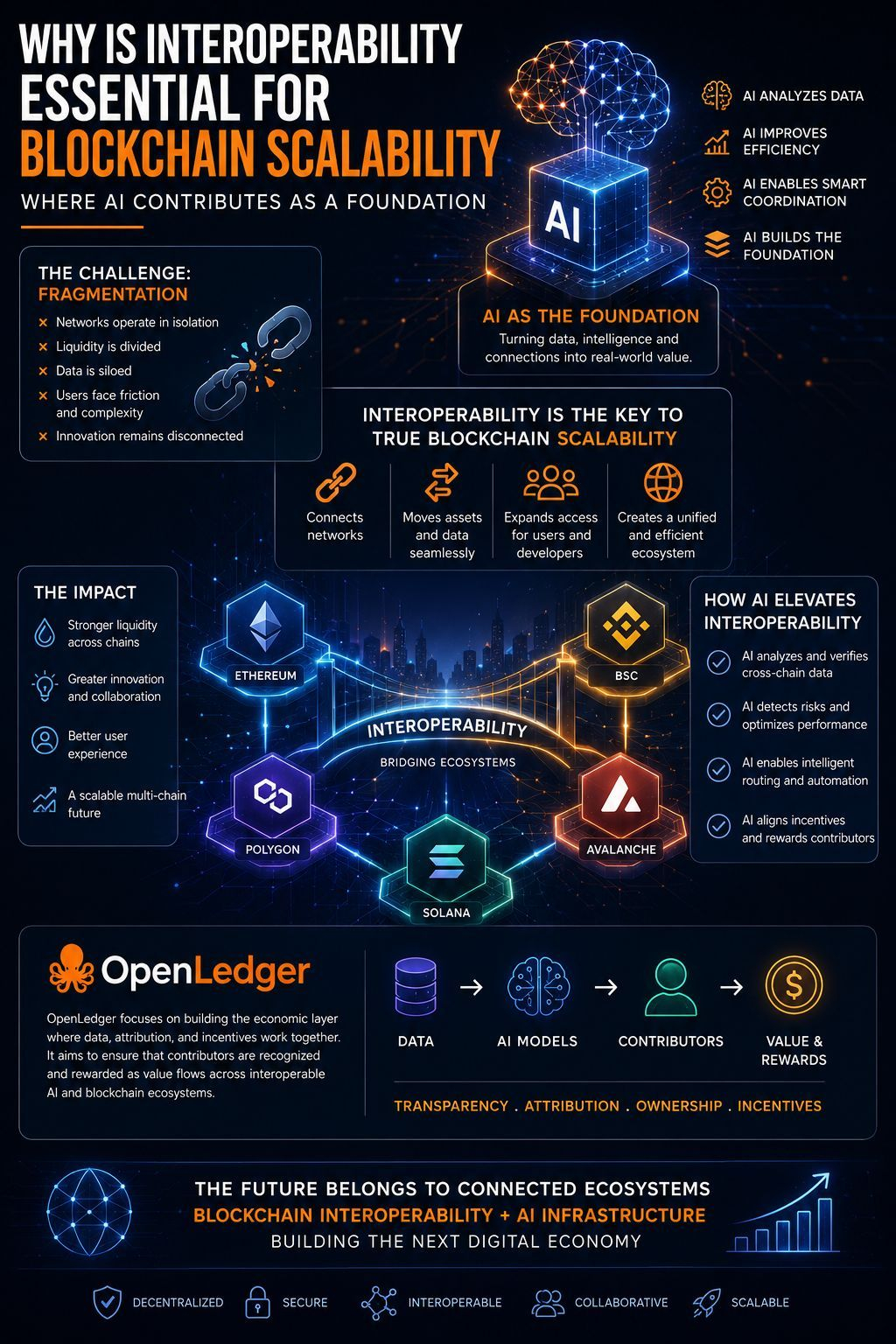
OpenLedger versucht, diesen Prozess transparenter zu gestalten.
Nicht durch Marketing-Slogans, sondern durch den Bau von Systemen, die darauf ausgelegt sind, Beiträge über den KI-Stack hinweg zu verfolgen.
Das ist ein ehrgeiziges Ziel.
Und ehrlich gesagt, es ist viel schwieriger, als viele Menschen realisieren.
Zuschreibung klingt einfach, bis man versucht, sie in die Praxis umzusetzen.
Eine einzelne KI-Ausgabe kann von Trainingsdaten, Abrufsystemen, Modellarchitektur, Feineinstellungen, Benutzerinteraktionen, Agentenentscheidungen und unzähligen anderen Variablen beeinflusst werden.
Zu bestimmen, wer Wert beigetragen hat – und wie viel – ist kein einfaches Buchhaltungsproblem.
Es ist ein komplexes Koordinationsproblem.
Deshalb bin ich weniger an der Erzählung interessiert und mehr an den Grenzfällen.
Wie geht das System mit Spam-Einreichungen um?
Wie verhindert es Reward Farming?
Wie trennt es wertvolle Informationen von Rauschen?
Wie balanciert es Transparenz mit Privatsphäre?
Wie stellt es sicher, dass Anreize nützliche Mitwirkende anziehen und nicht Opportunisten?
Das sind die Fragen, die letztendlich bestimmen, ob ein System überlebt.
Was OpenLedger interessant macht, ist, dass es scheinbar um diese Herausforderungen herum aufbaut, anstatt so zu tun, als ob sie nicht existieren.
Das Datanets-Konzept ist ein gutes Beispiel.
Nicht alle Daten haben den gleichen Wert.
Finanzdatensätze haben andere Anforderungen als Gesundheitsakten.
Rechtliche Informationen verhalten sich anders als Forschungsarchive.
Code-Repositories sind grundsätzlich anders als von Erstellern generierte Inhalte.
Alle Daten als einen riesigen Pool zu behandeln, schafft Ineffizienzen.
Spezialisierte Umgebungen zu schaffen, in denen Daten unabhängig beschafft, verifiziert und zugeordnet werden können, fühlt sich viel praktischer an.
Denn die Zukunft der KI dreht sich wahrscheinlich nicht darum, die meisten Daten zu sammeln.
Es geht darum, die nützlichsten Daten zu identifizieren.
Qualität, Herkunft und Verantwortlichkeit könnten wichtiger werden als schiere Menge.
Hier wird die These von OpenLedger interessant.
Das Projekt fragt nicht einfach, wie KI intelligenter werden kann.
Es fragt sich, ob KI nachvollziehbarer werden kann.
Ob Mitwirkende sichtbar bleiben können.
Ob Wert zu den Quellen zurückfließen kann, statt in einem geschlossenen System zu verschwinden.
Ob Zuschreibung wirtschaftlich statt symbolisch werden kann.
Das sind keine einfachen Probleme.
In der Tat könnten das einige der schwierigsten Infrastrukturprobleme in der KI sein.
Aber das sind reale Probleme.
Und ich sehe lieber ein Projekt, das schwierige, ungelöste Probleme angeht, als ein weiteres KI-Narrativ, das vollständig um Schlagworte herum aufgebaut ist.
Der Markt wird letztendlich entscheiden, ob OpenLedger erfolgreich ist.
Der echte Test wird nicht das soziale Engagement, die Token-Spekulation oder die Erzählstärke sein.
Es wird um die Adoption gehen.
Nutzen die Builder es, wenn Anreize verschwinden?
Setzen Mitwirkende weiterhin wertvolle Daten bereit?
Profitieren Modelle und Agenten von nachvollziehbaren Inputs?
Bleibt Zuschreibung nützlich, wenn das System skaliert?
Denn wenn die Antworten nein sind, dann ist es nur eine weitere Theorie.
Wenn diese Antworten ja werden, könnte OpenLedger etwas viel Wichtigeres bauen als eine weitere KI-Anwendung.
Es könnte Teil der Infrastruktur-Schicht werden, die die KI-Wirtschaft verantwortungsbewusster, transparenter und nachhaltiger macht.
Und das ist der Teil, den man im Auge behalten sollte.
#OpenLedger @OpenLedger $OPEN $XLM
