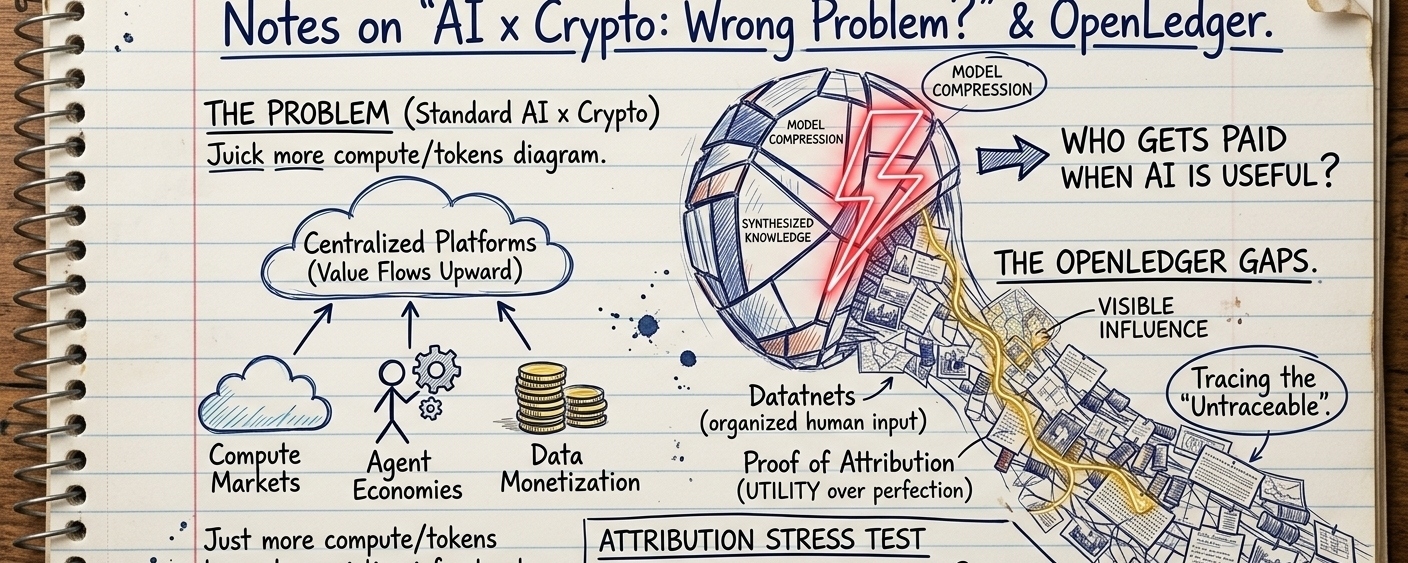
Das meiste, was ich über KI x Krypto lese, scheint immer die gleichen Ideen mit unterschiedlichem Branding zu umkreisen.
Berechnungsmärkte. Agentenökonomien. Datenmonetarisierung. Token-Anreize, die auf einer Infrastruktur aufbauen, die, ehrlich gesagt, für die meisten Anwendungsfälle bereits gut genug funktioniert.
Aber es gibt eine Sache, die mir immer wieder auffällt, die kaum ernsthafte Aufmerksamkeit erhält.
Nicht wie KI aufgebaut ist.
Nicht wie KI verwendet wird.
Aber wie KI die Anerkennung dafür zuweist, was sie produziert.
Und ich meine nicht Anerkennung im abstrakten, akademischen Sinne. Ich meine etwas Unangenehmeres: Wer verdient tatsächlich das Geld, wenn ein KI-Output nützlich ist?
Diese Frage wird ignoriert, weil sie nicht sauber in die aktuellen Systeme passt. Es ist einfacher zu sagen "das Modell hat es gemacht" oder "die Plattform hat es ermöglicht", als die unordentliche Realität darunter zu entwirren – Datensätze, die aus Tausenden von Quellen zusammengenäht sind, menschliche Beiträge, die über die Zeit verstreut sind, alles komprimiert in Gewichte, die vergessen, woher etwas kam.
Das ist genau die Lücke, in die OpenLedger zu drängen versucht.
Und um ehrlich zu sein — meine erste Reaktion war nicht Aufregung. Es war Zögern.
Denn Attribution in KI klingt wie eine dieser Ideen, die in Whitepapers wunderschön funktioniert und zusammenbricht, sobald man auf die Komplexität der realen Welt trifft. Neuronale Netzwerke speichern keine ordentlichen Quittungen. Sie verteilen das Lernen über Parameter auf eine Weise, die ein sauberes Nachverfolgen erschwert. Daher fühlt sich die Idee der "Verfolgung des Beitrags" zunächst leicht optimistisch an.
Aber OpenLedger argumentiert nicht wirklich für perfekte Nachverfolgbarkeit.
Es tut etwas Praktischeres – und Interessanteres.
Es sagt: Was wäre, wenn wir aufhören, auf perfekte Klarheit zu warten, und stattdessen ein System aufbauen, in dem nützliche Approximationen ausreichen, um Anreize zu schaffen?
Da kommen Datanets ins Spiel. Anstatt alle Daten als eine undifferenzierte Masse zu behandeln, werden Beiträge in strukturierte, domänenspezifische Pools organisiert. Es klingt einfach, fast offensichtlich, aber es verändert die Psychologie der Teilnahme. Daten werden nicht mehr "in das Training gekippt", sondern beginnen, Teil einer sichtbaren ökonomischen Oberfläche zu werden.
Dann gibt es den Proof of Attribution – und hier wird es auf eine Art und Weise kompliziert, die wirklich wichtig ist.
Die Idee ist nicht, Kausalität innerhalb eines neuronalen Netzwerks perfekt rückgängig zu machen. Das wäre unrealistisch. Stattdessen versucht es, den Einfluss so zu schätzen, dass es "gut genug" ist, um Belohnungen zuzuweisen.
Nicht Wahrheit.
Nicht Reinheit.
Nützlichkeit.
Und diese Unterscheidung ist es, zu der mein Denken immer wieder zurückdriftet.
Denn im Krypto haben wir gesehen, was passiert, wenn Anreizsysteme nur leicht falsch ausgerichtet sind. Die Leute optimieren sie sofort. Das tun sie immer. Wenn es ein Belohnungssignal gibt, wird es jemand ausnutzen. Wenn es Attribution gibt, wird jemand versuchen, die Attribution zu manipulieren.
Ja, der Skeptizismus ist real. Das sollte er sein.
Aber es gibt auch eine andere Seite, die ich nicht ignorieren kann.
Gerade jetzt hat KI eine ziemlich gebrochene Wirtschaftsstruktur darunter. Der Wert fließt nach oben – zu Modellanbietern, Plattformen, Aggregatoren – während die tatsächlichen Beiträger von Rohdaten wirtschaftlich unsichtbar sind. Nicht moralisch unsichtbar. Nur strukturell nicht berücksichtigt.
Und diese Unsichtbarkeit verstärkt sich im Laufe der Zeit. Je leistungsfähiger die Modelle werden, desto mehr hängen sie von zunehmend komplexen Datenpipelines ab, die niemand wirklich motiviert ist, sorgfältig zu pflegen.
Das ist der Engpass, über den die meisten Leute nicht sprechen.
Nicht berechnen.
Keine Modelle.
Aber Anreize rund um die Beitragsqualität.
Und hier fühlt sich OpenLedger weniger wie eine "neue Erzählung" an und mehr wie ein Stresstest für das aktuelle System. Selbst wenn sein Attributionsmodell unvollkommen ist – selbst wenn es nie vollständig robust im großen Maßstab wird – zwingt es eine Frage auf, der sich der KI-Stack stillschweigend entzogen hat:
Was passiert, wenn der Beitrag sichtbar genug wird, um wirtschaftlich relevant zu sein?
Ich glaube nicht, dass jemand eine saubere Antwort hat. Ich bin mir nicht einmal sicher, ob das System selbst eine hat.
Aber ich komme immer wieder auf diese Idee zurück: Jedes große Tech-Shift erreicht irgendwann einen Punkt, an dem die Abstraktion bricht und Kredit formalisiert werden muss. KI fühlt sich an, als käme sie diesem Punkt näher, und die meisten in der Branche tun immer noch so, als wäre es nicht so.
OpenLedger könnte in der Ausführung falsch sein. Das ist sehr möglich.
Aber das Problem, auf das es hinweist, scheint nicht zu verschwinden.
