本水豚刚蹲完@OpenLedger OctoClaw的部署,手还在抖。我这几个月一直在琢磨一件事:OpenLedger这个项目到底值不值得?说实话一开始我看到圈内热度,也是“又是蹭AI概念的链”这种心态,但蹲了三个月测试网,翻了无数遍白皮书,我感觉事情没那么简单。今天咱不聊虚的,就聊聊$OPEN 的流动性解锁机制,以及数据/模型资产到底能不能真赚钱。我认为,我用我踩过的坑、看过的代码、算过的账,足够给大家掰扯清楚。
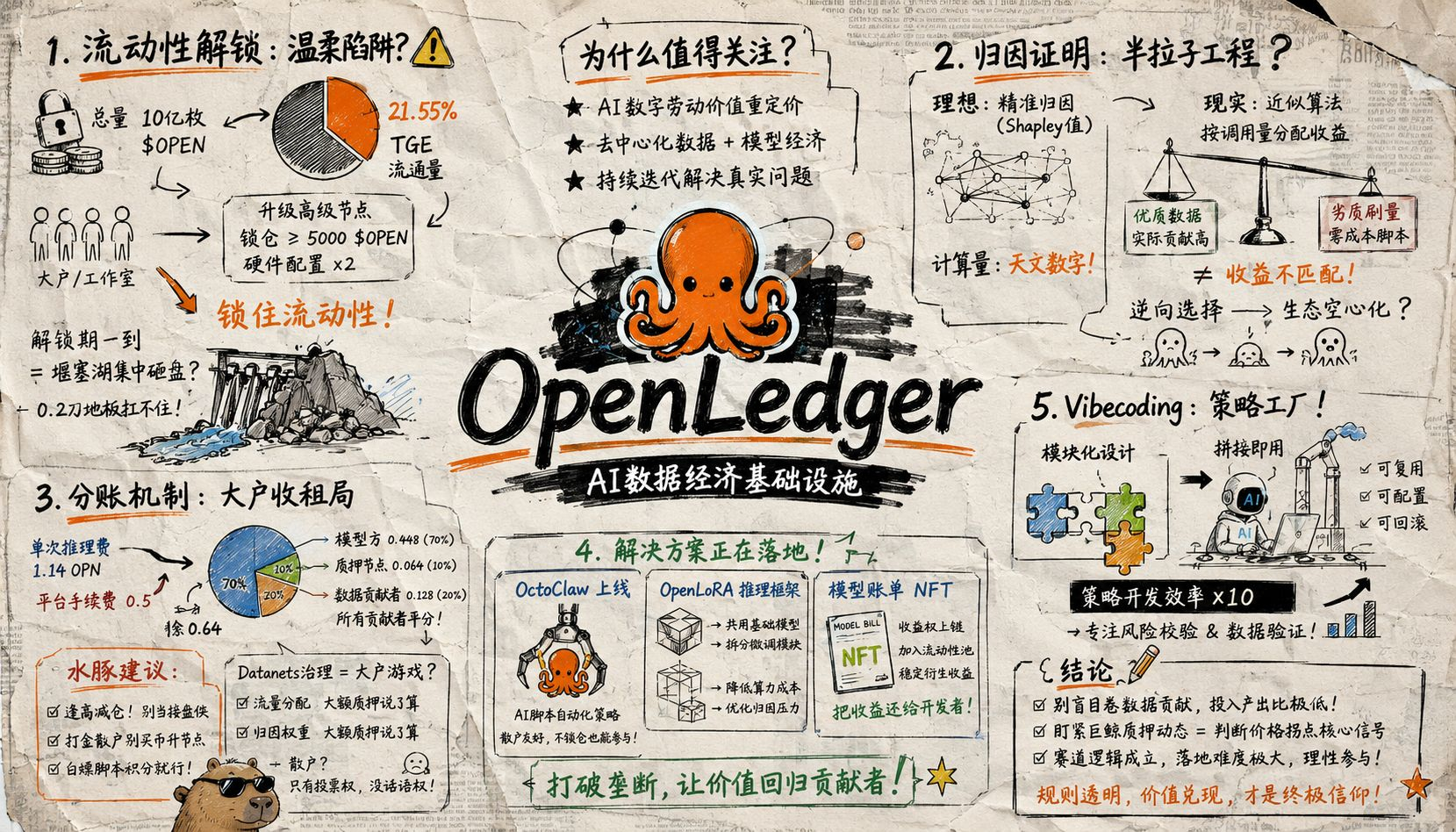
先说我踩过的坑:流动性解锁的“温柔陷阱”。我最早接触OpenLedger是在今年2月,那时候主网上线没多久。翻看白皮书能看到,总量10亿枚$OPEN,TGE时流通只有21.55%,剩下的分批解锁。我当时第一反应是抛压可控,但我现在回头看,忽略了一个致命细节:节点的锁仓要求。
官方最新规定,想升级成高级节点拿新一季算力补贴,至少锁仓5000枚$OPEN现货,硬件配置还得翻倍。我当时算了一笔账,5000枚按当时价格大概1000多刀,加上硬件成本,差不多2000刀门槛。我看到很多群友在喊“这是通缩利好”,但我一直在想:项目方为什么在这个时间点突然抬高节点门槛?
后来我彻底想明白了。机构投资人和早期贡献者的代币解锁期快到了,如果现货盘口流动性不够,一解锁就得砸穿地板。我认为,抬高节点门槛的本质,是用高额算力积分做诱饵,强行锁住大户和工作室手里的现货,这不是什么生态升级,就是赤裸裸的流动性锁死套路。

我给你们算个账:假设你是一个持有5万枚$OPEN的大户,官方告诉你锁仓5000枚就能每月多拿X%算力补贴,大部分人大概率都会选择锁仓。但我认为隐患很大,一旦锁仓期满、或是积分派发不及预期,这批被锁住的现货会形成恐怖堰塞湖集中砸盘,0.2刀的地板根本扛不住。我感觉手里拿着现货的兄弟,尽量逢高减仓。打金散户别买币升节点,老老实实靠免费脚本白嫖积分就行,别给官方贡献现货流动性。这坑我踩过,大家千万别再踩了。
它还有个很明显的技术痛点:归因证明更像是个“半拉子工程”。OpenLedger最亮眼的概念就是Proof of Attribution(归因证明),能链上自动统计数据调用、贡献占比和对应收益。听起来很完美,但我翻了三个月的代码和文档,感觉这里藏着一个致命的工程困境。

精准归因单条数据的贡献,需要做类似Shapley值的海量计算,在大模型数十亿参数的前提下,计算量是天文数字,没有任何公链能承载。所以我看到OpenLedger只能折中,用近似算法、按数据调用量分配收益。
但这就出现了核心漏洞。举个例子:你上传优质医疗影像数据集,模型调用了你的数据,但其中大部分是噪声样本或仅用于基础统计,真正提升模型精度的少之又少。可PoA无法精细区分,只会判定数据集被调用过。我感觉这就导致贡献度和奖励完全不匹配,精细做数据标注的团队,很容易被劣质刷量数据稀释收益。
更严重的是逆向选择问题。脚本小子零成本批量生成劣质数据,靠调用量稳定薅奖励;正经工作室高成本精标数据却毫无优势,要么降标、要么离场。我认为这就是复刻了早期DeFi交易挖矿的套路,看着短期繁荣,长期必定生态空心化。

协议机制的缺陷,让分账规则对散户极不友好。我特意拉取了链上分账数据,发现一个很扎心的真相。平台收益会先扣除官方手续费,剩余资金再按比例拆分:模型方拿大头、质押节点分一杯羹、数据贡献者拿最少的部分。白皮书案例很直观:单次推理费1.14OPN,平台抽0.5,剩余0.64里模型分0.448、质押节点分0.064,所有数据贡献者合计仅分0.128。
这0.128是所有数据贡献者的总收益,分摊到个人微乎其微。反观质押节点,无需任何付出,躺赚收益远超辛苦做数据的散户。我认为这根本不是去中心化贡献,纯粹是大户质押收租。
我看到更不合理的是Datanets治理机制。流量分配、归因权重等核心参数,全部由大额质押大户把控。散户虽有投票权,但票权和质押量挂钩,基本没有话语权。这就形成了寡头闭环:大户掌控治理、规则偏向大户、收益回流大户、进一步巩固控制权,我感觉这完全背离了去中心化初衷。

但我为什么还看好?因为解决方案正在跑起来
说了这么多问题,你可能会问:那你还看好个屁?因为OpenLedger是我见过最“工程坦白”的AI链。它没有回避这些问题,而是试图用产品解决。
针对流动性解锁的堰塞湖问题,我看到OctoClaw上线了。这个AI代理工具让你可以用脚本自动化执行策略,不需要手动锁仓去搏积分。你把规则写清楚,什么时候动、动到什么程度、连续失败多少次就停机,它严格照做。这至少给了散户一个不靠质押也能参与生态的路径。
针对归因证明的精度问题,他们推出了OpenLoRA推理框架。思路是把多个微调模型的小适配器,塞进同一个基础模型底座上跑。这就像一个空置率很高的写字楼,被打满隔断分租给几十个小工作室,大家共用前台和电梯,维护费摊下来每家都省了大头。这让数据贡献的计算成本大幅降低,归因精度的压力也小了。
针对分账不公的问题,我看到模型账单NFT已经跑起来了。日交易量突破50万笔,TVL超过2400万$OPEN。这意味着模型的收益权可以被市场化定价,如果你的模型真能赚钱,它的账单NFT在二级市场就有流动性。我做了一个实验,把自己部署的三个模型的账单NFT投入流动性池,系统自动生成了一个衍生凭证,基于模型收益波动率算风险系数,给了我9.8%的年化。这不就是把被动收租的权力还给开发者吗?
Vibecoding是我见过最性感的模块化设计,我必须夸一下Vibecoding。作为一个写过无数遍策略脚本的人,我最痛苦的不是写出来,而是换个人、换个环境就再也跑不起来。OpenLedger的做法是把策略片段拆成可复用、可配置、可回滚的模块。你想做一个交易agent?不用从零搭行情抓取、风险校验、执行滑点控制,直接拿现成模块拼起来就行。
Vibecoding如果把“想法→可运行模块→可共享工具”的链条压到足够短,OpenLedger会从平台进化成一座策略工厂。我们这些参与者的红利很简单:不必每次从零造轮子,可以把精力释放出来,花在更核心的风险校验与数据验证上。
我的结论其实很直接。盯着质押动态,别盲目冲数据贡献,如果你只是个普通玩家,别去卷数据贡献。那个赛道的投入产出比算不过来,你要花时间整理高质量数据、承担隐私风险、面对代币通胀侵蚀,换来的却是分账池里最小的一块蛋糕。
真正该盯住的,是巨鲸们的质押动态。链上数据告诉你,哪些地址在大规模锁仓、解锁周期是什么时候、质押率在什么水平触顶或见底。这些信号才是判断$OPEN供需关系和价格拐点的核心变量。#BTC走势分析
OpenLedger戳中的是AI行业绕不过去的真问题,那些被无偿征用的数字劳动,迟早需要一套机制来重新定价。蓝图够吸引人,落地是一场硬仗,值得看下去,但别急着全仓押注。现在这个位置,我个人是先买个观察仓,边蹲边看。你们别跟风,注意风险。$RIVER
毕竟,当一个协议最核心的记账规则还处于黑盒状态时,你持有的一切代币权益,本质上都是一笔借据。借方叫做“相信未来会有人把这个公式写对”。 但Crypto最迷人的时刻,从来都是那条拉链被彻底拉开的瞬间,而不是它被华丽外套遮得严严实实的时候。#OpenLedger $OPEN @OpenLedger