Der Markt fühlte sich heute ungewöhnlich flach an. Nicht das schlechte flach — einfach... warten. Ich hatte einen Tab mit den Velas offen, die ich nicht wirklich beobachtet habe, und irgendwie bin ich tief in die OpenLedger-Dokumentation geraten. Das war nicht geplant. Ich habe tatsächlich versucht, etwas anderes zu finden.
Also, ich habe angefangen zu lesen, wie $OPEN mit Datenattribution umgeht, und irgendwo auf der dritten Seite hat sich meine Denkweise verändert.
Hier ist das, worauf ich immer wieder zurückkomme: Wir haben das KI-Datenproblem falsch formuliert. Das Gespräch dreht sich immer um den Zugang — wer Daten hat, wer sie nutzen kann, wer blockiert wird. Aber OpenLedger, @OpenLedger , #OpenLedger , weist leise auf ein anderes Problem hin. Nicht der Zugang. Herkunft.
Die meisten Menschen, die derzeit Daten zu KI-Systemen beitragen, haben keine Ahnung, dass ihr Beitrag überhaupt stattgefunden hat. Ein Dataset wird gesammelt, gebündelt, verkauft, darauf trainiert — und die Person, die diesen Inhalt ursprünglich erstellt hat, erhält genau gar nichts. Nicht nur kein Geld. Keine Aufzeichnung. Keine Spur. Es ist nicht so, dass das System unfair ist. Es ist, dass das System kein Gedächtnis hat.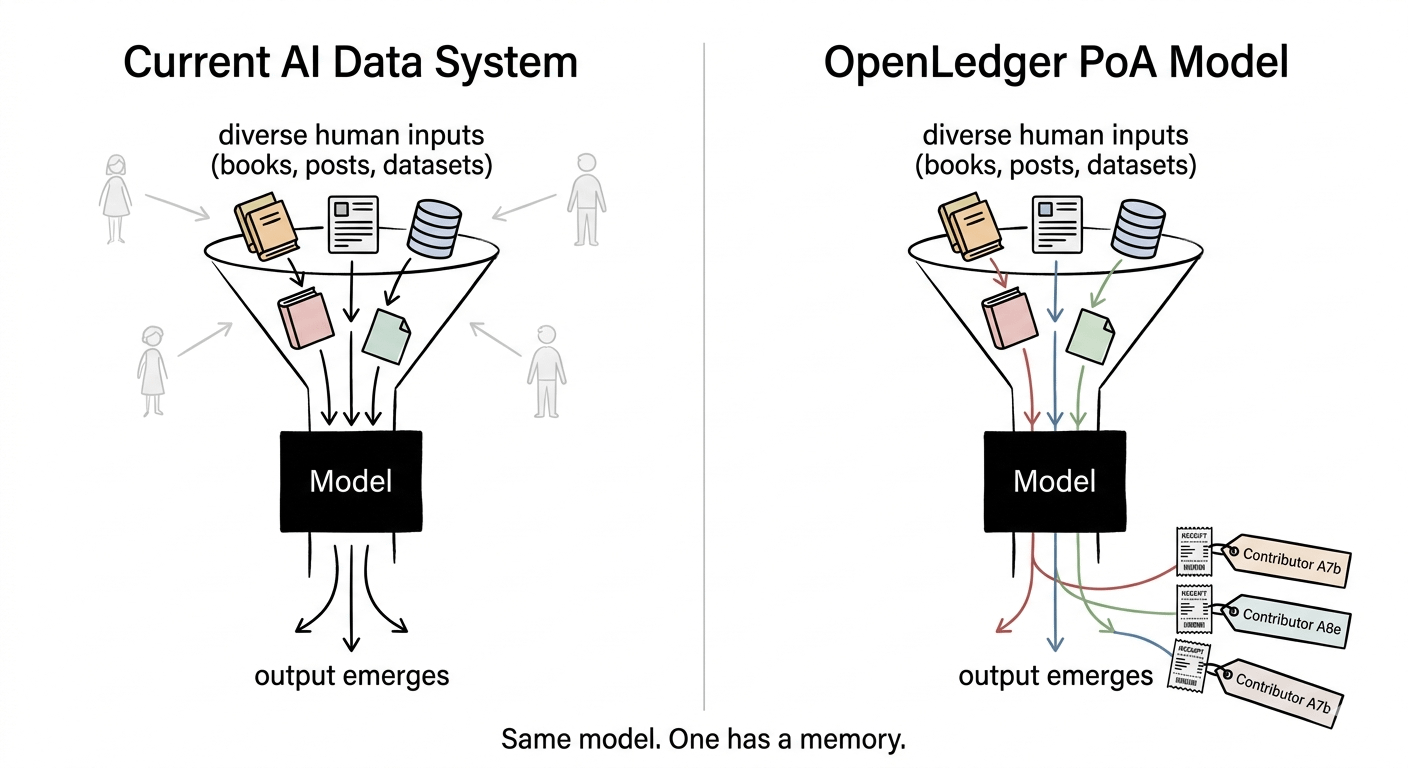
Was OpenLedger tatsächlich aufbaut — und das ist der Teil, der für mich klickte — ist weniger wie ein Marktplatz und mehr wie ein Ledger für kognitive Arbeit. Jedes Dataset, jeder Schritt im Modelltraining, wird on-chain über das, was sie Proof of Attribution nennen, verfolgt. Die Idee ist: Wenn KI-Ausgaben auf die Eingaben zurückverfolgt werden können, die sie geprägt haben, kann die Vergütung diesem Pfad automatisch folgen.
Ich dachte, das wäre nur eine schönere Art, Datenlizenzen zu verwalten. Aber es ist tatsächlich seltsamer und interessanter als das. Die Einheit des Wertes ist nicht das Dataset selbst. Es ist der Einfluss, den die Daten auf die Modellausgabe hatten. Das ist ein grundlegend anderes Buchhaltungssystem als alles, was wir zuvor verwendet haben.
Aber hier ist der Teil, der mich stört.
Einfluss ist wirklich schwer zu messen. Das PoA-Whitepaper beschreibt zwei Ansätze — Einflussfunktions-Approximationen für kleinere Modelle und suffix-array-basierte Token-Zuschreibung für LLMs. Ich habe diesen Absatz dreimal gelesen. Die Methodologie ist real, die Mathematik existiert, aber in großem Maßstab? Über Milliarden von Trainingstoken? Zuzuordnen, welches Stück Daten welchen Output beeinflusst hat, beginnt sich weniger wie Buchhaltung und mehr wie Archäologie anzufühlen.
Und ich bin mir nicht ganz sicher, ob das dem Druck standhält. Wenn ein Modell etwas Wertvolles produziert, setzt das saubere Zurückverfolgen zu einem Datenbeiträger eine Art saubere Kausalität voraus, die vielleicht nicht existiert. Training ist chaotisch. Einfluss blutet. Zwei Mitwirkende könnten nahezu identische Daten eingereicht haben — wer erhält die Anerkennung? Wie teilt man es auf? Das Whitepaper deutet darauf hin, löst es aber nicht vollständig.
Das bedeutet, dass das System, das endlich menschliche Wissensarbeiter belohnen soll, am Ende vielleicht eher diejenigen belohnt, die Daten eingereicht haben, die am einfachsten zuzuschreiben sind, anstatt die wertvollsten. Das ist ein subtiler, aber wichtiger Unterschied.
Im Moment ist die aktivste Engagement-Ebene im OpenLedger-Ökosystem die Yapper Arena — ein Preisgeld von 2 Millionen OPEN-Token für die Top 200 sozialen Mitwirkenden auf der Kaito-Rangliste. Das ist keine Kritik, eine Community aufzubauen, bevor die Infrastruktur ausgereift ist, ist einfach Teil des Prozesses. Aber das bedeutet auch, dass die Leute, die derzeit $OPEN verdienen, größtenteils über OpenLedger reden, anstatt es mit Daten zu füttern.
Die aktuellen Datanets, die ModelFactory, das Attribution-System — das sind die langfristigen Ziele. Die Frage ist, ob die Community, die gerade aufgebaut wird, die Community sein wird, die sich für die härtere, weniger glamouröse Arbeit einsetzt, tatsächlich hochwertige Trainingsdaten beizusteuern, wenn die Infrastruktur bereit ist.
Diese Lücke — zwischen wer zuerst belohnt wird und für wen das System theoretisch gebaut ist — ist das, worüber ich ständig nachdenke.
Denn wenn der Proof of Attribution funktioniert, ist es tatsächlich eine der interessanteren strukturellen Veränderungen, wie KI entwickelt wird. Das Modell hört auf, eine Black Box zu sein, die stillschweigend menschliches Wissen konsumiert, und wird zu etwas, das einen Beleg trägt. Jede Ausgabe mit einer nachverfolgbaren Herkunft. Jeder Mitwirkende mit einem verifizierbaren Anspruch.
Das ist keine kleine Idee. Das ist eine ganz andere Beziehung zwischen menschlichem Wissen und maschineller Ausgabe.
Ich werde wahrscheinlich einfach beobachten, wie sich die Datanet-Aktivität in den nächsten Monaten entwickelt. Sehen, ob die on-chain Attribution-Pfade echte Tiefe zeigen oder ob es hauptsächlich auf der sozialen Ebene bleibt. Die Freischaltungen für das Team und die Investoren treten ohnehin erst im September in Kraft, also gibt es Spielraum.
Der Markt sieht immer noch so aus, als ob er etwas entscheidet. Bin mir noch nicht sicher, was.