Most discussions around AI focus on the output. People talk about smarter models, better responses, faster inference, and more capable agents. The conversation almost always starts at the end of the process—the moment an AI generates something useful. OpenLedger approaches AI from a different direction. Instead of asking how to make models more powerful, it asks a much simpler question: who should benefit when AI creates value?
That question becomes surprisingly difficult once you start unpacking how modern AI systems actually work. A single AI response may depend on thousands of contributors spread across multiple layers. Data providers collect and organize information. Developers build and fine-tune models. Researchers create adapters and specialized improvements. Infrastructure providers handle deployment and inference. Yet when value is generated, most of these contributors disappear from the economic picture. The final product receives attention while the supply chain behind it remains largely invisible.
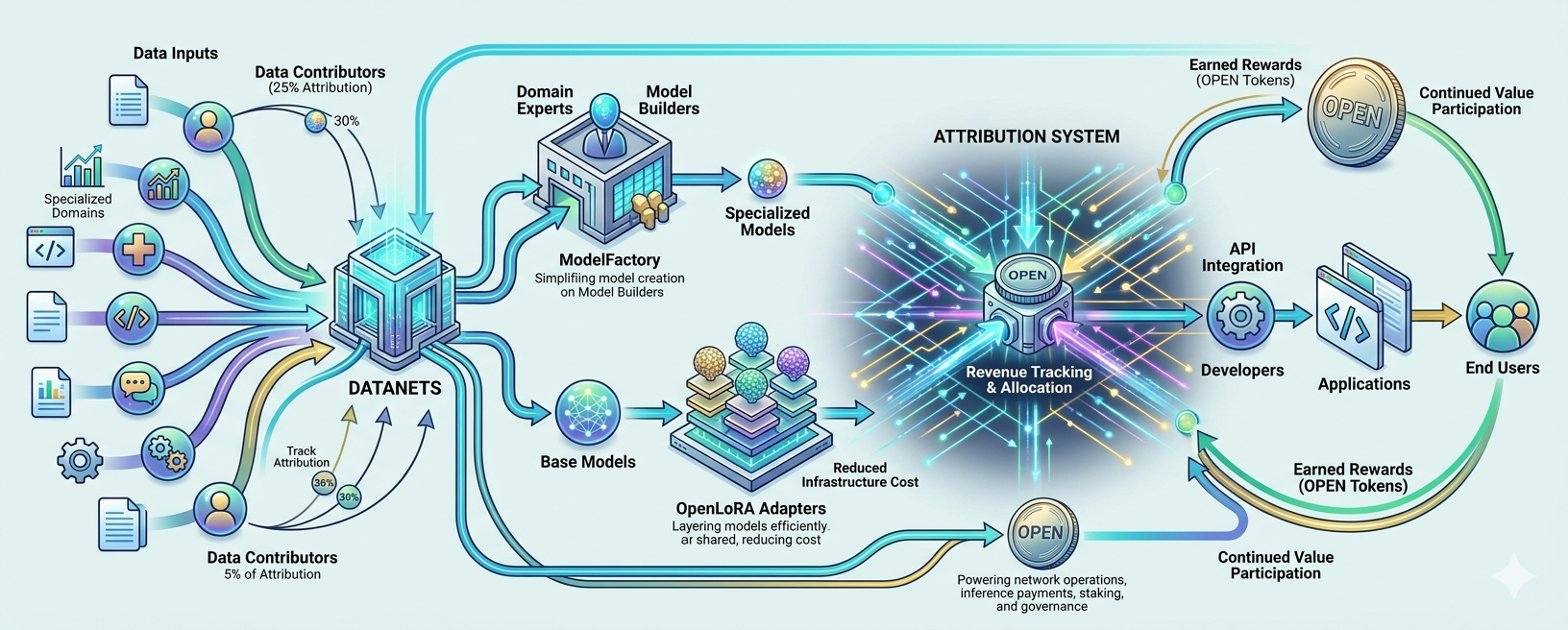
OpenLedger is attempting to change that. The project is built around the idea that AI should function more like an economy than a black box. Every meaningful contribution, whether it comes from data, models, adapters, or infrastructure, should remain connected to the value it helps create.
That vision begins with Datanets. Rather than treating datasets as static files uploaded once and forgotten, OpenLedger introduces Datanets as living networks of contributions. The goal is not only to store information but also to preserve a record of who supplied it and how it participates in future AI systems.
This distinction matters because data is becoming one of the most important resources in AI. General-purpose models already have access to enormous amounts of public information. What increasingly creates differentiation is specialized knowledge. Industries such as finance, healthcare, gaming, customer support, compliance, and research often require highly specific datasets that cannot simply be scraped from the internet.
The challenge is that contributors rarely capture long-term value from providing that information. A company may train a model using valuable domain expertise, but once the training process is complete, the connection between the contributor and future revenue often disappears. OpenLedger is attempting to keep that connection alive. The project's attribution system is designed to ensure that contributions remain visible even after they become part of a larger AI system.
If data helps improve a model and that model generates economic activity later, the original contributor may continue participating in the rewards. At least in theory, this creates stronger incentives for producing valuable information rather than simply uploading data and walking away.
The concept is attractive because it addresses a real problem. The difficulty is implementation. Attribution in AI is one of the hardest challenges in the industry. Models learn from enormous collections of information, and outputs are usually influenced by many different components simultaneously. Determining whether a dataset was present during training is relatively easy. Determining how much that dataset contributed to a specific outcome is much harder.
This challenge sits at the center of OpenLedger's vision. If attribution can be measured accurately, contributors gain a reason to keep improving the quality of the ecosystem. If attribution becomes unreliable, the reward system risks losing credibility. The success of the project depends heavily on how effectively it can solve this problem.
Another important piece of the ecosystem is ModelFactory. This component allows users to transform data into working AI models without navigating every technical step involved in training and deployment. The idea is to make model creation more accessible to domain experts who understand valuable information but may not have extensive machine learning experience.
The appeal of this approach is clear. Many industries possess specialized knowledge but lack the technical resources required to build AI systems around it. By lowering the barriers to entry, OpenLedger hopes to bring more contributors into the AI economy. However, simplicity always comes with trade-offs. Advanced builders often want deeper control over training configurations, evaluations, deployment settings, and performance monitoring. Balancing accessibility with flexibility will be an ongoing challenge.
OpenLoRA adds another practical layer to the ecosystem. Rather than deploying entirely separate models for every specialization, OpenLoRA allows multiple adapters to operate efficiently on top of shared base models. This reduces infrastructure costs while making it easier to support a large number of specialized AI applications.
This infrastructure focus is important because OpenLedger is not only discussing ownership and rewards. It is also addressing the practical realities of serving AI systems at scale. Specialized models become more useful when they can be deployed efficiently, and OpenLoRA is designed to support exactly that goal.
The project's API strategy also reflects an understanding of developer behavior. Instead of forcing developers to learn entirely new workflows, OpenLedger aims to provide familiar interfaces that make experimentation easier. Adoption often depends less on technical capability and more on reducing friction, and this approach increases the likelihood that developers will actually test the platform.
The token, OPEN, serves as the economic layer connecting the ecosystem together. It is used for network operations, inference payments, model registration, staking, governance, and rewards. Unlike many tokens that exist separately from product usage, OPEN is designed to move through the system as activity occurs.
However, token utility alone does not guarantee long-term value. The health of the ecosystem ultimately depends on real participation. Data contributors need to provide useful information. Builders need to create valuable models. Developers need to integrate those models into applications. End users need to generate meaningful demand. Without those activities, the economic loop becomes difficult to sustain.
What makes OpenLedger interesting is that it focuses on contribution rather than consumption. Many AI platforms concentrate exclusively on delivering outputs. OpenLedger focuses on everything that happened before the output appeared. It asks who provided the data, who improved the model, who contributed infrastructure, and how those contributions should be rewarded.
This gives the project a distinct identity. It is not attempting to compete with major AI labs by building the largest model. Instead, it is trying to create an economic framework around specialized data, model development, and attribution. That is a more focused and arguably more realistic objective.
The project still faces significant challenges. Attribution remains the largest. Data quality is another. Privacy concerns will also become increasingly important as more organizations consider contributing proprietary information. Product complexity is equally important because users ultimately care about workflows, not architectures.
For OpenLedger to succeed, the experience must remain simple. Contribute data. Build a model. Deploy it. Track usage. Earn rewards. The easier that process becomes, the easier it will be for users to understand the value proposition.
At its core, OpenLedger is attempting to give AI systems an economic memory. It wants contributions to remain visible even after they become part of larger models and applications. Whether that vision succeeds remains to be seen, but the problem it is addressing is real. As AI becomes more integrated into everyday business and digital infrastructure, the question of who deserves credit and compensation will only become more important.
OpenLedger's strongest idea is not its token or its blockchain. It is the belief that AI value has a supply chain, and that supply chain should not disappear once the final output is produced.This version is already formatted into readable paragraphs and is ready for publication.
