
Je mehr ich über die Infrastruktur von KI nachdenke, desto weniger überzeugt bin ich, dass der größte Engpass beim Aufbau von Intelligenz liegen wird.
Lange Zeit schien das offensichtlich. Bessere Modelle würden gewinnen. Bessere Datensätze würden gewinnen. Mehr Rechenleistung würde gewinnen.
Jetzt bin ich mir da nicht mehr so sicher.
Nützliche KI zu erstellen wird von Jahr zu Jahr einfacher. Open-Source-Modelle verbessern sich ständig. Die Kosten für Feineinstellungen sinken. Spezialisierte Agenten tauchen überall auf. Die Fähigkeit, intelligente Ausgaben zu generieren, verbreitet sich viel schneller, als die meisten Leute erwartet haben.
Was immer noch schwierig erscheint, ist zu entscheiden, welche Ausgaben vertrauenswürdig sind.
Deshalb habe ich OpenLedger (OPEN) in letzter Zeit aus einer anderen Perspektive betrachtet.
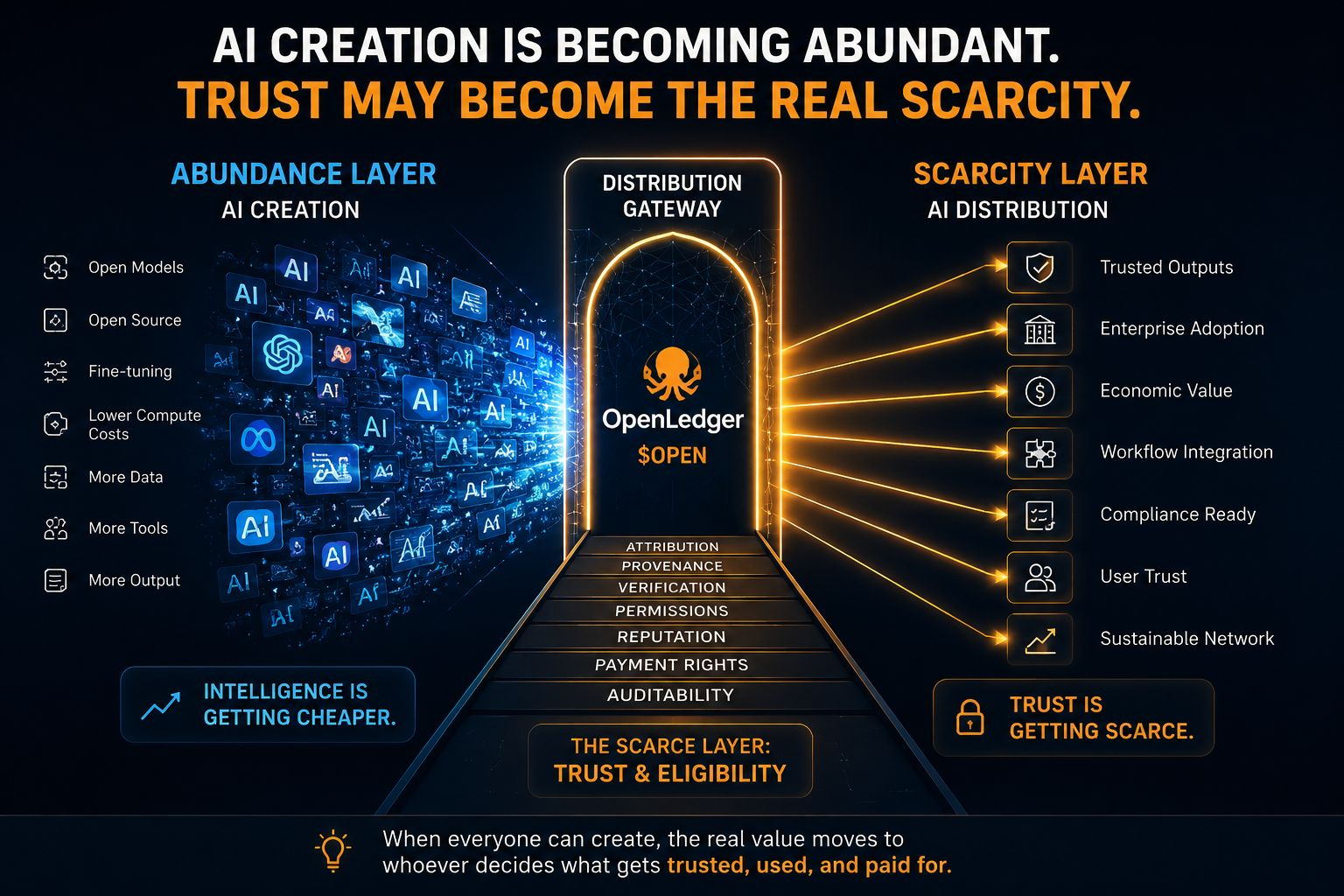
Die meisten Diskussionen konzentrieren sich auf die KI-Erstellung, aber ich denke, die interessantere Frage ist die Verteilung.
Wenn Tausende von Modellen ähnliche Ergebnisse produzieren können, was bestimmt dann, welches tatsächlich in einem Unternehmen eingesetzt wird? Welches erhält die Bezahlung? Welches wird in einen Workflow integriert? Welches ist vertrauenswürdig genug, um Entscheidungen zu treffen?
An diesem Punkt reicht Intelligenz allein nicht aus.
Was zählt, ist der Beweis.
Beweis dafür, woher die Ausgabe stammt. Beweis, wer beigetragen hat. Beweis, dass die Geschichte, Zuordnung und Berechtigungen des Modells überprüft werden können.
Mit anderen Worten, die knappe Ressource könnte nicht mehr die KI-Generierung sein. Es könnte die Glaubwürdigkeit der KI sein.
Märkte funktionieren bereits so.
Eine Idee zu haben, ist nicht rar. Eine Idee zu haben, der die Leute vertrauen, ist es. Inhalte zu erstellen, ist nicht rar. Ein Publikum zu erreichen, ist es.
Zugang zu Kapital ist nicht rar. Sich dafür zu qualifizieren, ist es. Das gleiche Muster könnte sich in der KI zeigen.
Wenn die Ausgabe von KI überhandnimmt, werden die Systeme stärkere Filter benötigen, um zu bestimmen, was akzeptiert wird und was ignoriert wird. Unternehmen werden nicht nur fragen, ob ein Modell smart ist. Sie werden fragen, ob seine Entscheidungen überprüfbar, zuordenbar und vertrauenswürdig sind.
Hier beginnt OpenLedger weniger wie ein KI-Netzwerk und mehr wie eine Vertrauensinfrastruktur-Schicht auszusehen.
Vielleicht liegt der zukünftige Wert nicht darin, Intelligenz zu produzieren.
Vielleicht liegt es darin, Intelligenz nutzbar zu machen.
Denn wenn jeder kreieren kann, verschiebt sich der echte Vorteil oft zu dem, der die Verifizierung, den Ruf und den Zugang kontrolliert.
Und wenn die KI weiterhin in Richtung Überfluss geht, könnten diese Schichten wichtiger werden als die Modelle selbst.