Der Markt fühlte sich heute irgendwie flach an. Weder bearish noch bullish — einfach dieses komische, statische Dazwischen, wo man die Dinge aktualisiert, ohne wirklich zu erwarten, dass etwas passiert.
Also bin ich in ein Rabbit Hole über OpenLedger geraten. Nicht, weil mir jemand gesagt hat, ich solle das machen. Einfach weil $OPEN ständig aufgetaucht ist und ich verstehen wollte, was der tatsächliche Unterschied sein soll.
Und ich hätte den Tab fast nach fünf Minuten geschlossen.
Denn auf den ersten Blick liest es sich wie jede andere "dezentralisierte KI"-Präsentation. Verteilte Berechnung, Token-Anreize, offener Zugang. Ich habe dieses Deck schon hundertmal gesehen. Also begann ich zu überfliegen — und dann hat mich etwas zum Stoppen gebracht.
Hier ist das, was mir aufgefallen ist, und ich bin mir immer noch nicht ganz sicher, ob ich es richtig formuliere:
Die meisten KI-Plattformen — selbst die, die sich "offen" nennen — sind immer noch um den Zugriff auf Modelle gebaut. Du zahlst, um das Modell zu nutzen. Vielleicht feinstimmst du es. Vielleicht setzt du es ein. Aber das Modell selbst? Das ist das Asset. Es sitzt hinter einem Tor. Die Plattform besitzt die Beziehung zwischen dir und der Intelligenz.
OpenLedger macht das nicht.
Was es tatsächlich aufbaut, ist näher an einem Ledger für KI-Beiträge — nicht nur Ausgaben. Das bedeutet: Die Daten, die du mitbringst, die Rechenleistung, die du bereitstellst, das Feedback, das du generierst — all das wird on-chain verfolgt. Attributionsschicht. Nicht nur "du hast die KI genutzt." Sondern "du hast die KI verbessert, und hier ist der Beweis."
Ich dachte, das sei nur ein anderes Monetarisierungsmodell. Aber tatsächlich — es ist ein anderes Eigentumsmodell.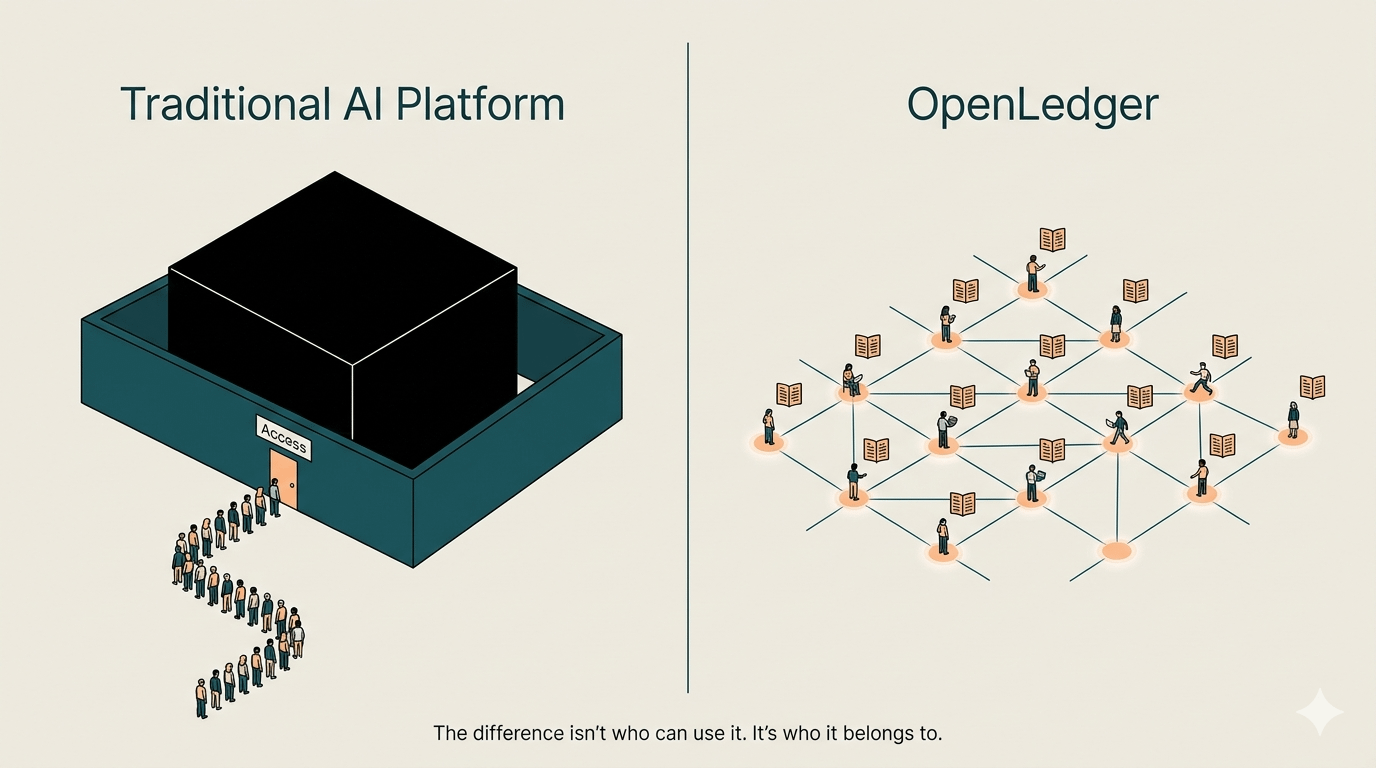
Und das ist der Teil, den die Leute falsch betrachten.
Alle diskutieren, ob dezentrale KI mit OpenAI in Bezug auf Fähigkeiten konkurrieren kann. Das ist nicht der Punkt. Die Frage ist, ob du ein KI-Ökosystem aufbauen kannst, in dem die Menschen, die zur Intelligenz beitragen — nicht nur konsumieren — tatsächlich den Wert erfassen, den sie schaffen.
Traditionelle Plattformen extrahieren. Mitwirkende kumulieren nicht.
Wenn die Attributionsschicht von OpenLedger so funktioniert, wie sie beschrieben wird, sammeln Mitwirkende verifizierbaren Beweis für ihre Rolle beim Training und Verbessern von Modellen. Das verändert die Anreizstruktur auf einer ziemlich grundlegenden Ebene. Es geht nicht darum, "nutze unsere KI." Es geht darum, "die KI gehört teilweise dem, der sie gebaut hat."
Aber das ist der Teil, der mich stört.
Attribution in der KI ist wirklich schwierig. Nicht politisch schwierig — technisch schwierig. Wie isolierst du den Beitrag eines Datensatzes, eines Labelers, eines Feedbacks, innerhalb eines Modells, das mit Milliarden von Signalen trainiert wurde? Die Mathematik wird schnell unübersichtlich. Und wenn die Attributionsschicht nicht präzise ist, wird sie zu etwas Schlimmerem als nutzlos — sie wird zu einer Erzählung. Eine Token-Geschichte ohne echten Mechanismus dahinter.
Ich sage nicht, dass das passiert. Ich sage, ich habe nicht genug gesehen, um sicher zu sein, dass es nicht so ist.
Es gibt auch die übliche Dezentralisierungsspannung: Je mehr du ein System verteilst, desto schwieriger ist es, die Qualität aufrechtzuerhalten. Zentralisierte KI-Labore können schnell iterieren, weil sie alles kontrollieren. Das Modell von OpenLedger erfordert eine Koordination zwischen Mitwirkenden, die unterschiedliche Anreize, unterschiedliche Datenqualitäten und unterschiedliche Teilnahmelevels haben. Das ist nicht unmöglich zu managen. Aber es ist Reibung, mit der OpenAI nicht umgehen muss.
Also schwanke ich ständig hin und her.
Die Version davon, die tatsächlich funktioniert, ist überzeugend. Wenn du Attribution in großem Maßstab nachweisen kannst, hast du im Wesentlichen eine neue wirtschaftliche Schicht für die KI-Entwicklung geschaffen. Eine, in der die Menschen, die am nächsten an den Daten sind — Nischen-Communities, Fachleute, kleinere Betreiber — nicht nur Nutzer sind, sondern auch Stakeholder. Das verändert, wer KI baut und was gebaut wird.
Das ist für $OPEN in spezifischer Weise wichtig. Wenn der Attributionsmechanismus echt und verifizierbar ist, ist der Token nicht nur Spekulation auf einer Plattform — es ist ein Anspruch auf ein System, in dem Beitrag und Eigentum dasselbe sind. Das ist eine andere Erzählung, als die meisten DeFi/AI-Hybriden laufen.
Aber wenn die Attribution weich ist — wenn sie ungefähre, manipulierte oder nur theoretische ist — dann hast du eigentlich einen regulären Rechenmarkt mit zusätzlichen Schritten.
Ich habe das nicht gelöst. Ich habe einfach darüber nachgedacht.
Wie auch immer, der Markt macht immer noch das gleiche Geräusch wie heute Morgen. Nichts hat sich wirklich bewegt. Ich werde wahrscheinlich einfach weiter beobachten, wie das $OPEN launch läuft und sehen, ob der Mechanismus auf die Probe gestellt wird oder komfortabel bleibt.
Einige Dinge machen nur in der Produktion Sinn.