Ich hatte gestern ein seltsames paar Stunden, in denen ich ständig über dezentrale KI gelesen habe und das Gefühl hatte, dass etwas nicht stimmte, aber ich konnte nicht genau sagen, was. Jeder beschrieb die gleiche allgemeine Vision – KI, die nicht auf den Servern eines Unternehmens lebt, Berechnungen verteilt über Netzwerke, kein einzelner Ausfallpunkt. Ich hatte so oft zu diesem Rahmen genickt, dass ich aufgehört hatte, es wirklich zu hinterfragen. Dann verbrachte ich Zeit mit OpenLedger und irgendwann klickte es endlich, nicht ganz angenehm.
Das, was ich immer wieder bemerkte, während ich durchging, wie $OPEN tatsächlich seinen Ansatz strukturiert — speziell die Schicht, in der Daten zugeordnet, bezogen und validiert werden, bevor sie in ein Modell eingespeist werden — ist, dass OpenLedger nicht primär um verteiltes Rechnen herum baut. Es baut um verteiltes Urteil herum. Und mir wurde klar, dass ich diese beiden Dinge lange Zeit ohne es zu merken vermischt hatte.
Hier ist, was ich meine, und warum es mehr bedeutet, als es klingt.
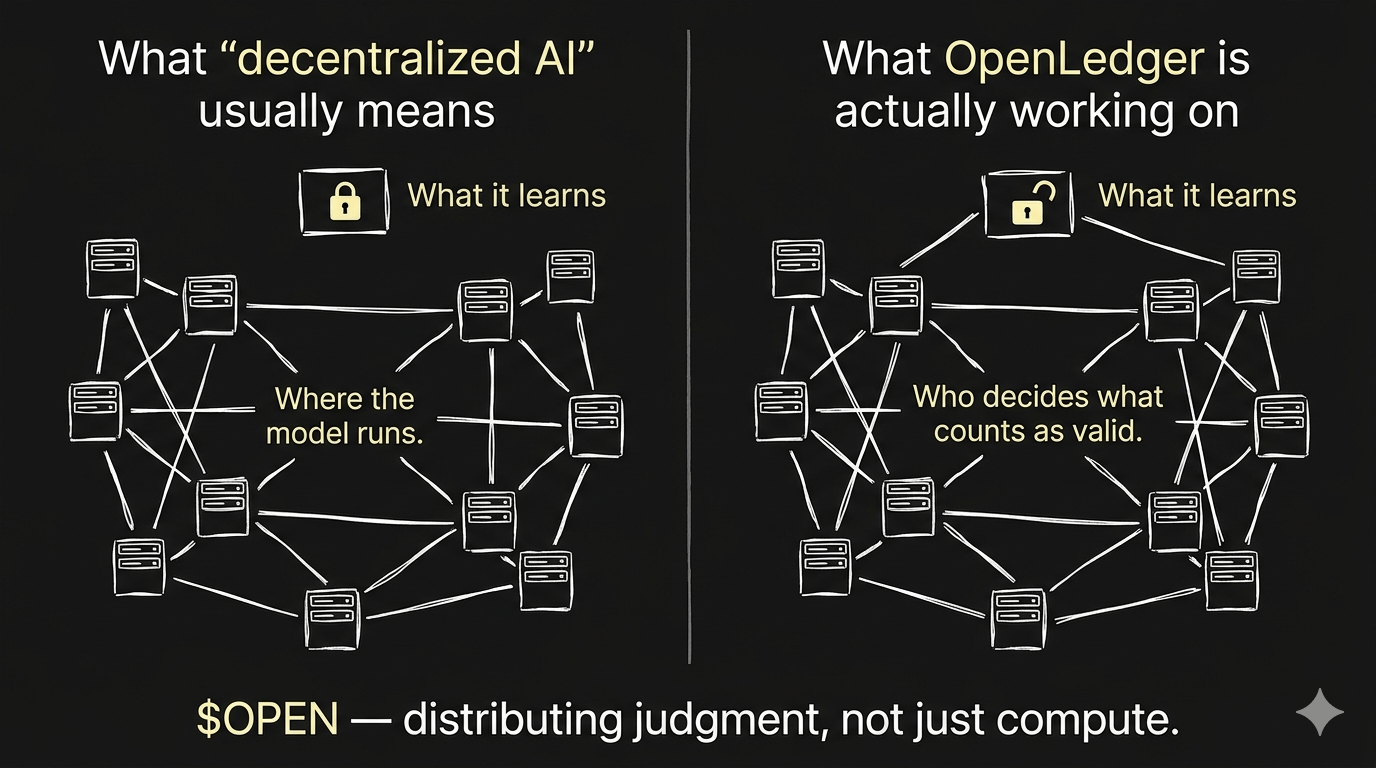
Verteiltes Rechnen bedeutet, dass die KI an vielen Orten statt an einem einzigen läuft. Das ist real und hat reale Vorteile — Resilienz, Kostenstruktur, Zensurresistenz auf der Infrastrukturebene. Aber die Intelligenz — was das Modell weiß, was es als gültig betrachtet, wofür es trainiert wurde zu optimieren — kann immer noch völlig zentralisiert sein, selbst wenn die Server über tausend Knoten verteilt sind. Man kann die Hardware perfekt dezentralisieren und trotzdem hat eine Einheit die Entscheidung darüber, was als gute Information zählt, was in die Trainingsdaten aufgenommen wird, wessen Wissen gültig ist und wessen herausgefiltert wird. Die Verarbeitung ist verteilt. Das Urteil nicht.
Was #OpenLedger zu funktionieren scheint, ist die schwierigere Version dieses Problems. Nicht wo die KI läuft, sondern wer entscheidet, was die KI lernt. Die Attributions- und Beschaffungs-Schicht, die ich immer wieder betrachtete, ist nicht nur eine Datenpipeline — es ist ein Versuch, den Akt der Entscheidung darüber zu verteilen, was glaubwürdig ist, was wertvoll ist, was Teil der Grundlage eines KI-Systems sein sollte. Das ist etwas ganz anderes als verteilte Inferenz.
Und ich dachte, das ist offensichtlich gut. Dann habe ich weiter nachgedacht.
Aber hier ist der Teil, der mich wirklich stört.
Verteilte Urteile klingen besser als konzentrierte, bis man fragt, was verteiltes Urteil tatsächlich im großen Maßstab produziert. Märkte verteilen Preisurteile über Millionen von Teilnehmern, und Märkte machen trotzdem über längere Zeiträume hinweg gravierende Fehler. Demokratien verteilen politische Urteile, und demokratische Mehrheiten haben im Laufe der Geschichte konstant schreckliche Entscheidungen getroffen. Ein kognitiver Prozess wird durch Verteilung nicht automatisch besser. Es ändert, wer die Macht darüber hat, was wichtig ist, garantiert aber nicht, dass das Ergebnis genauer oder gerechter ist.
@OpenLedger baut Infrastruktur für etwas wirklich Neues auf, aber die Annahme, dass dezentrales Urteil bessere KI produziert, bleibt eine Annahme. Es wurde nirgendwo in bedeutendem Maßstab getestet. Die Hoffnung ist, dass viele unabhängige Beiträge mit unterschiedlichen Perspektiven eine reichhaltigere, ausgewogenere KI-Grundlage erzeugen als ein kleines Team in einem Unternehmen. Das ist eine vernünftige Hypothese. Ich bin nur nicht überzeugt, dass es bereits bewiesen wurde, und ich bemerke, dass der Großteil der Begeisterung für dezentrale Intelligenz sie als offensichtlich behandelt, anstatt als etwas, das noch bewiesen werden muss.
Es gibt auch die Frage, was passiert, wenn verteiltes Urteil ein Ergebnis produziert, das sicher falsch ist. Zentrale Systeme scheitern auf sichtbare, nachvollziehbare Weise — man kann auf die Organisation zeigen, die die schlechte Entscheidung getroffen hat. Verteilte Systeme können Konsensfehler produzieren, die schwerer zuzuordnen und schwerer zu korrigieren sind, weil es keinen einzelnen Akteur gibt, gegen den man sich wehren kann. Ich habe von niemandem in diesem Bereich eine klare Antwort darauf gesehen.
Nichts davon bedeutet, dass die Richtung falsch ist. Ich denke tatsächlich, dass das Problem, auf das OpenLedger hinweist — zentriertes Urteil, das in KI-Systemen eingebettet ist, die neutral erscheinen — eines der folgenreichsten ungelösten Probleme in der Entwicklung von KI ist. Die Tatsache, dass es schwer zu lösen ist, bedeutet nicht, dass es nicht versucht werden sollte. Und $OPEN ist eines der wenigen Projekte, auf die ich gestoßen bin, die anscheinend an der Verteilung von Urteilen arbeiten, anstatt nur an der Verteilung von Rechenleistung, was mindestens die richtige Diagnose ist.
Ich denke nur, dass die Leute, die in diesem Bereich aufbauen, und die Leute, die ihn beobachten, besser bedient wären, wenn sie es als ein offenes Experiment behandeln würden, anstatt als eine gelöste Architektur.
Wie auch immer. Die Charts sind seitwärts, nichts bewegt sich, und ich habe das jetzt zwei Tage lang überdacht. Ich werde wahrscheinlich eine Weile vom Bildschirm weggehen.