
Bevor es Aufführungsrechte-Organisationen gab, spielten Radiosender ständig Musik. Songs bewegten sich durch die Luftwellen, die Zuhörerschaft wuchs, die Werbeeinnahmen folgten. Die Wertschöpfungskette war für jeden, der zuschaute, offensichtlich. Was weniger offensichtlich war, war, wie dieser Wert zu den Leuten zurückfand, die die Musik ursprünglich geschaffen hatten.
Es hat größtenteils nicht funktioniert.
Nicht weil die Branche einzigartig korrupt war. Sondern weil das Mechanismus zur Verfolgung von Beiträgen im großen Stil einfach noch nicht existierte. Ohne ein System, das glaubwürdig sagen konnte, dieser Song wurde so oft gespielt und deshalb steht diesem Künstler dieser Betrag zu, fiel die Wirtschaft auf diejenigen zurück, die die Verteilung kontrollierten. Das blieb bis die Infrastruktur mit dem Problem Schritt hielt, wahr.
KI sitzt in genau diesem Moment.
Jedes große Sprachmodell, das heute in Produktion ist, wurde durch menschliche Beiträge geprägt. Nicht abstrakt. Konkret. Die veröffentlichten Arbeiten eines medizinischen Forschers. Die Dokumentation eines Programmierers im Open Source. Eine Erklärung eines Fachexperten in einem Forum, die um 2 Uhr morgens geschrieben wurde, weil sie die Antwort kannten und helfen wollten. All das ging in die Trainings-Pipelines ein, prägte das Verhalten des Modells und wurde in Ausgaben eingebettet, die jetzt in großem Maßstab kommerziellen Wert generieren.
Das Modell hat aus diesen Beiträgen gelernt.
Die Frage ist, ob es jemals so entworfen wurde, dass es sich daran erinnert.
In fast jedem Fall ist die Antwort nein. Nicht, weil Modellentwickler einzigartig nachlässig sind. Sondern weil die Infrastruktur zur Verfolgung von Beiträgen auf der Ebene individueller Eingaben, über Milliarden von Datenpunkten hinweg, durch komplexe Trainingsprozesse, die Einflüsse auf nicht-lineare Weise verwischen und kombinieren, in einer Form, die wirtschaftlich nützlich gemacht werden könnte, tatsächlich nicht existierte.
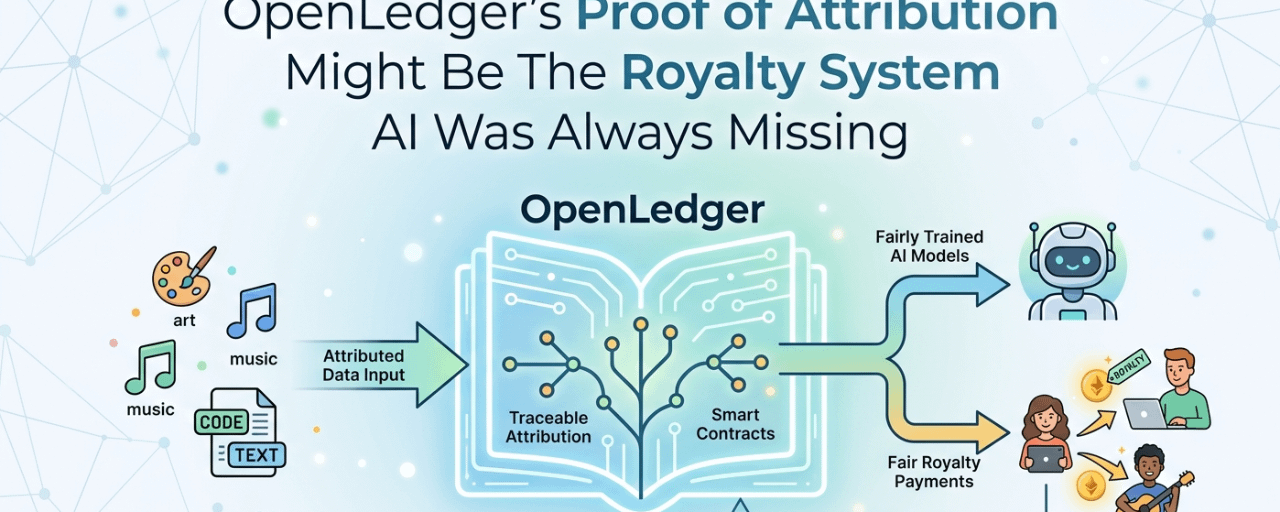
Das ist das spezifische Problem @OpenLedger , um das sich Proof of Attribution dreht.
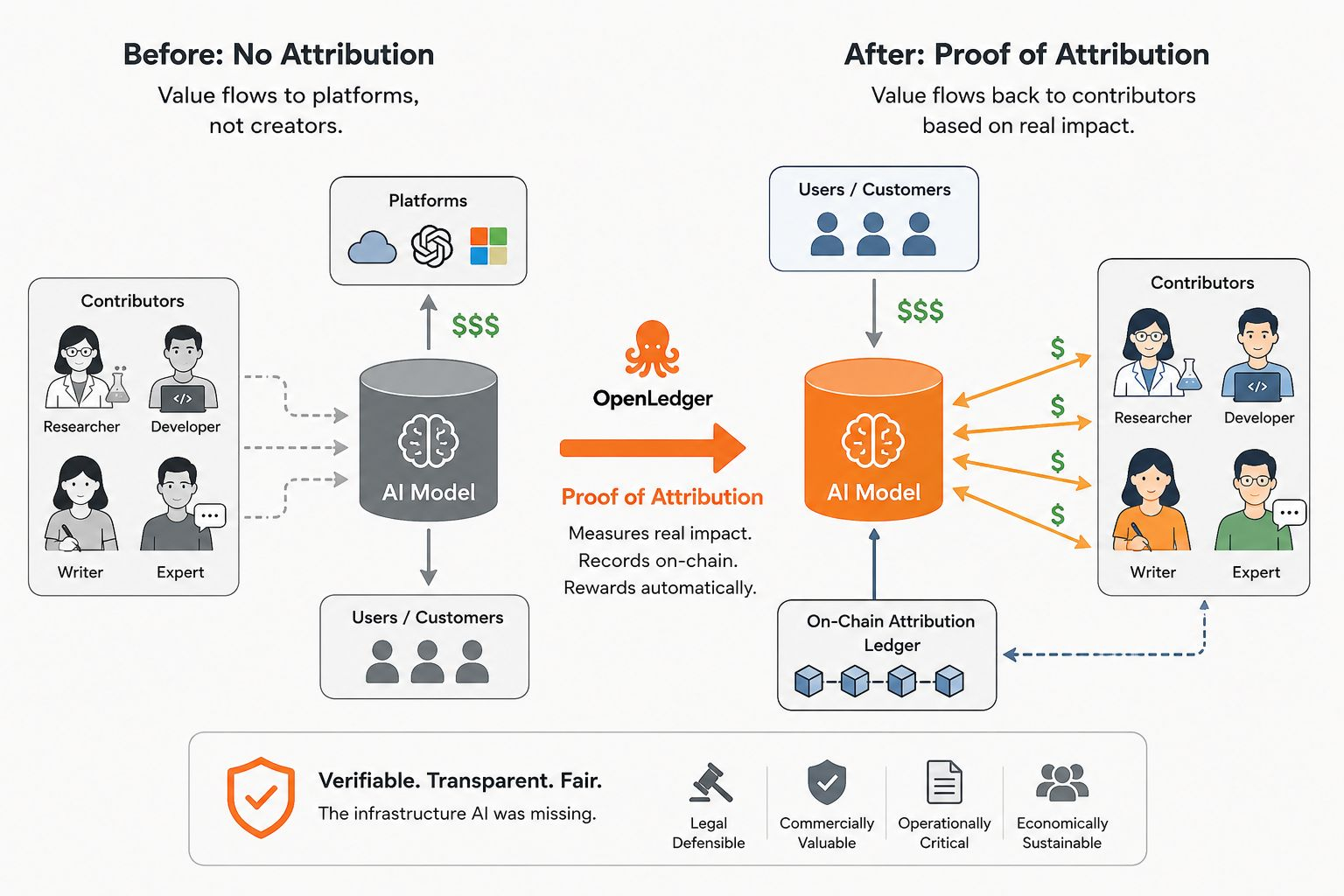
Der Mechanismus funktioniert, indem gemessen wird, wie sehr jeder Datenbeitrag tatsächlich das Verhalten des Modells beeinflusst hat. Nicht symbolisch. Messbar. Wenn das Entfernen eines bestimmten Datensatzes die Leistung des Modells bei echten Aufgaben erheblich verändert, hatte dieser Datensatz echten Wert. Der Beitrag wird on-chain erfasst, an den Beiträger gebunden und wird Teil eines automatisierten Belohnungsverteilungssystems, das aktiviert wird, wenn das Modell wirtschaftlichen Output generiert.
Das klingt technisch, bis man es mit dem vergleicht, was vorher war.
Bevor es eine Infrastruktur für Leistungsschutzrechte in der Musik gab, floss der Wert zu demjenigen, der den Zugang kontrollierte. Nachdem sie existierte, konnte der Wert zu demjenigen fließen, der den Inhalt geschaffen hat — nicht perfekt, nicht ohne Streitigkeiten, aber strukturell. Die Infrastruktur änderte, was wirtschaftlich möglich war.
Proof of Attribution versucht denselben architektonischen Wandel für KI.
Der interessante Teil ist, was sich dadurch über die Belohnungen individueller Beiträger hinaus ändert. Wenn Beiträge zurückverfolgt und wirtschaftlich an Ausgaben gebunden werden, verschiebt sich das gesamte Verhalten des Systems. Beiträger haben einen Grund, qualitativ hochwertigere Daten einzureichen, denn die Qualität beeinflusst, wie sehr ihr Beitrag das Modell beeinflusst und damit, wie viel sie verdienen. Entwickler haben einen Grund, die genaue Attribution aufrechtzuerhalten, denn die wirtschaftliche Abwicklung hängt davon ab. Unternehmen, die Modelle auf verifiziertem, attribuiertem Daten aufbauen, haben etwas, was sie momentan nicht haben: eine verteidigbare Antwort auf die Frage, was die Intelligenz gefüttert hat, die sie einsetzen.
Dieser letzte Teil ist wichtiger, als ihm momentan Anerkennung zukommt.
Der rechtliche Druck bezüglich KI-Trainingsdaten ist nicht mehr theoretisch. Gerichte in mehreren Gerichtsbarkeiten entscheiden aktiv, welche Verpflichtungen in Bezug auf die Herkunft von Daten bestehen. Ein KI-System, das saubere, überprüfbare, attribuierte Trainingsdaten nachweisen kann, ist ein strukturell anderes Asset als eines, das dies nicht kann. Nicht nur ethisch. Kommerziell. Vertraglich. Operativ.
Proof of Attribution löst kein philosophisches Problem über Fairness.
Es wird die Dokumentation aufbauen, die KI-Systeme sowieso benötigen werden.
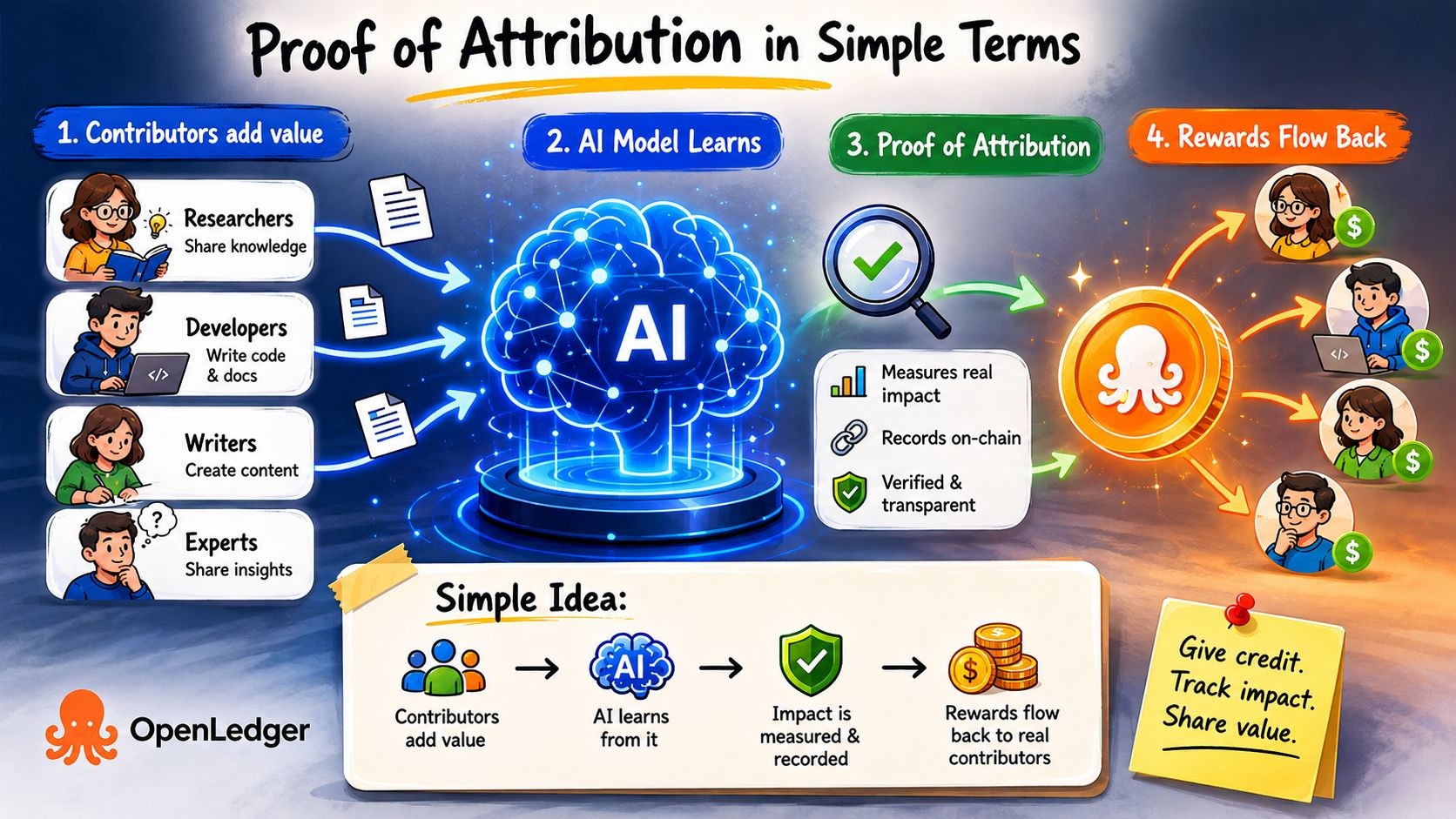
Die schwierigere Frage ist, ob die Infrastruktur im großen Maßstab standhalten kann. Attribution in KI ist wirklich chaotisch. Beiträge überlappen sich. Modellgewichte mischen Einflüsse auf Weise, die eine saubere Trennung erschwert. Die genauen wirtschaftlichen Prozentsätze den einzelnen Eingaben zuzuordnen, erfordert Entscheidungen, die teilweise willkürlich sind. Gaming ist unvermeidlich, sobald wirtschaftliche Belohnungen sichtbar werden — minderwertige Beiträger überschwemmen Systeme, um Zahlungen zu jagen, während echter Wert verwässert wird.
Das macht die Richtung nicht falsch. Es macht es schwierig.
Musikrechte werden immer noch ständig angefochten. Attribution in kreativen Branchen war nie perfekt sauber. Aber die Existenz einer unvollkommenen Attributionsinfrastruktur ist immer noch wirtschaftlich vorzuziehen gegenüber keiner Attributionsinfrastruktur. Märkte benötigen keine philosophische Gewissheit. Sie benötigen Systeme, gegen die Menschen bereit sind, sich zu einigen.
Das könnte die ehrlichste Darstellung dessen sein, was $OPEN tatsächlich bewertet.
Nicht gelöstes Problem. Eine Infrastrukturebene, die das ungelöste Problem wirtschaftlich adressierbar macht, zum ersten Mal. Und in einer Welt, in der KI-Ausgaben zunehmend an Entscheidungen beteiligt sind, die echte Konsequenzen haben, ist der Abstand zwischen "wir können das nicht zurückverfolgen" und "wir können das glaubwürdig zurückverfolgen" keine kleine Lücke.
Es ist der Unterschied zwischen einem System, auf dem das nächste Jahrzehnt aufbauen kann, und einem, das es letztendlich von Grund auf neu aufbauen muss.