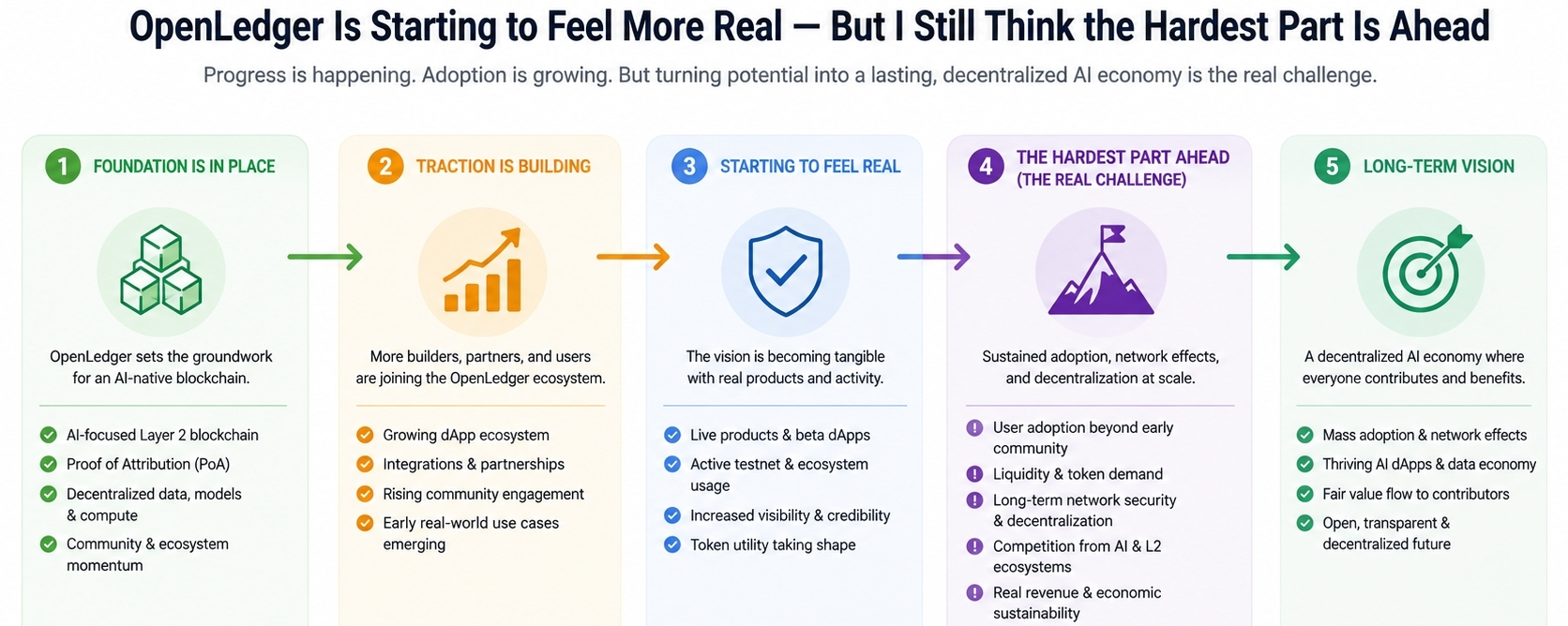
Vor ein paar Monaten konnte ich ehrlich gesagt immer noch nicht sagen, ob OpenLedger etwas Dauerhaftes aufbaut oder einfach von dem perfekten Timing zwischen KI und Krypto profitiert.
Ich habe viele Projekte gesehen, die eine Zukunft beschreiben, in der Daten wertvoll werden, KI-Agenten autonom interagieren und Mitwirkende automatisch belohnt werden. Auf dem Papier klingt das immer beeindruckend. Der schwierige Teil ist, ein System zu bauen, das auch dann noch funktioniert, wenn echte Nutzer ankommen, die Anreize kompliziert werden und der Druck steigt.
Deshalb hat mich das aktuelle Update von OpenLedger etwas umdenken lassen.
Nicht weil plötzlich alles bewiesen aussieht, sondern weil das Projekt endlich so wirkt, als würde es über Ideen hinaus in eine tatsächliche Infrastruktur übergehen, die in der realen Welt getestet werden kann.
Der Launch des Mainnets war für mich wichtiger als die meisten Ankündigungen darum herum. Davor fühlte sich OpenLedger noch wie ein interessantes Konzept mit starken Narrativen dahinter an. Sobald die Mechanismen für Attribution und Abwicklung on-chain zu arbeiten begannen, wurde das Gespräch weniger theoretisch.
Jetzt kann das System tatsächlich nach Leistung und nicht nach Versprechen beurteilt werden.
Das bedeutet nicht, dass die Akzeptanz garantiert ist. Aber zumindest gibt es jetzt endlich etwas Greifbares zu bewerten.
Was meine Aufmerksamkeit noch mehr erregte, war der Fokus auf Lizenzierung und Attribution. Die Integration des Story Protocols fühlt sich viel bedeutungsvoller an als die durchschnittliche Partnerschaft im Ökosystem, weil sie eines der größten ungelösten Probleme in der KI derzeit berührt: nachzuweisen, woher Daten kommen und wer Anspruch auf Vergütung hat.
Die meisten KI-Systeme operieren immer noch in einem grauen Bereich, wo Eigentum, Attribution und Nutzungsrechte unklar sind. OpenLedger versucht, Attribution direkt mit programmierbaren Zahlungen zu verbinden, was eines der ersten Updates ist, das tatsächlich wirtschaftlich nützlich erscheint, anstatt nur "KI-nativ" zu klingen.
Wenn dieses Modell in der Skalierung funktioniert, könnte es völlig verändern, wie Kreatoren, Datensätze und Unternehmen mit KI-Systemen interagieren.
Aber hier steigt auch mein Skeptizismus.
Es ist eine Sache, Attribution unter kontrollierten Bedingungen zu demonstrieren. Es ist etwas ganz anderes, dies zuverlässig zu machen, wenn Datensätze sich überschneiden, KI-Agenten miteinander interagieren und Unternehmensnutzer rechtliche Sicherheit anstelle von Experimenten verlangen.
Das ist meiner Meinung nach immer noch die größte Lücke.
Ein großer Teil der Vision rund um verantwortungsvolle KI und maschinengesteuerte Wirtschaften fühlt sich immer noch früh an. Ambitioniert, ja. Bewiesen, noch nicht.
Ich achte auch auf das Verhalten der Tokens, denn die Märkte decken Schwächen meist schneller auf als das Marketing.
OPEN folgte einem Muster, das ich bei Infrastrukturprojekten schon oft gesehen habe: riesige frühe Aufregung, aggressive Volatilität danach und wachsende Bedenken hinsichtlich Spekulation und Druck auf Freigaben.
Das ist wichtig, denn letztendlich muss das Netzwerk selbst nachhaltige Nachfrage schaffen.
Wenn die meiste Aktivität weiterhin aus Spekulation statt aus tatsächlicher Nutzung kommt, dann wird die langfristige Stärke des Ökosystems fraglich, egal wie gut die Technologie klingt.
Die Diskussionen über Unternehmensumsatz und Rückkäufe waren aus diesem Grund interessant für mich. Nicht weil Rückkäufe die Token-Ökonomie magisch beheben, sondern weil sie zeigen, dass das Team zumindest über Emissionen und kurzfristigen Hype hinaus denkt.
Das ist eine gesündere Richtung.
Gleichzeitig denke ich, dass die Leute bei einigen der Schlagzeilen-Metriken vorsichtig bleiben sollten.
Große Knotenanzahlen, hohe Transaktionszahlen und schnelles Ökosystemwachstum klingen in frühen Phasen immer beeindruckend. Aber Krypto hat mich gelehrt, dass incentivierte Teilnahme und echte Nützlichkeit zwei sehr verschiedene Dinge sind.
Der echte Test beginnt später.
Bauen Entwickler weiter, wenn die Belohnungen nachlassen?
Nutzen Unternehmen die Attributionsebene weiterhin, wenn die Compliance-Standards strenger werden?
Tolerieren Nutzer zusätzliche Komplexität, wenn zentralisierte KI-Plattformen einfacher und schneller bleiben?
Das sind die Fragen, die entscheiden werden, ob OpenLedger echte Infrastruktur wird oder nur ein weiteres temporäres KI-Zyklus-Narrativ.
Was sich in meinem Denken geändert hat, ist dies:
Ich sehe OpenLedger nicht mehr nur als Idee, die nach Relevanz sucht. Das Projekt fügt langsam echte operationale Teile zusammen — Attribution, Lizenzierung, Monetarisierung, Abwicklung und KI-Koordination — zu etwas, das tatsächlich wie ein funktionierendes System aussieht.
Das allein ist Fortschritt.
Aber ich denke auch, dass die schwierigste Phase noch nicht begonnen hat.
Die nächste Phase dreht sich nicht um Ankündigungen oder Partnerschaften. Es geht darum, das System unter Druck zuverlässig zu halten, richtig zu skalieren und eine Nachfrage zu schaffen, die über Spekulation hinausgeht.
Das ist der Teil, den ich jetzt beobachte.
Im Moment fühlt sich OpenLedger weniger wie ein narrativer Versuch und mehr wie ein ernsthafter Infrastrukturtest an. Mein Vertrauen hat sich verbessert, aber ich denke immer noch, dass der wichtigste Beweis noch bevorsteht, nicht hinter uns.

