Ich habe in letzter Zeit etwas Seltsames im AI-Bereich bemerkt.
Jeder rennt herum, um schlauere Modelle zu bauen, größere Systeme zu entwickeln und schnellere Ergebnisse zu liefern. Aber kaum jemand redet darüber, was mit dem Wert passiert, der um diese Modelle entsteht.
Wer profitiert eigentlich?
Diese Frage hat mich zufällig zurück zu @OpenLedger gezogen.
Zuerst habe ich nicht weiter darauf geachtet. Noch eine AI + Dezentralisierungsgeschichte? Davon haben wir schon Hunderte gesehen.
Aber nachdem ich etwas Zeit damit verbracht habe, zu verstehen, wie das Ökosystem funktioniert, wird mir klar, dass das Projekt auf ein anderes Problem fokussiert scheint.
Anstatt zu fragen, wie wir die größte KI bauen, fühlt sich die größere Frage an:
Wie machen wir die KI-Ökonomien fair?
Denk mal darüber nach.
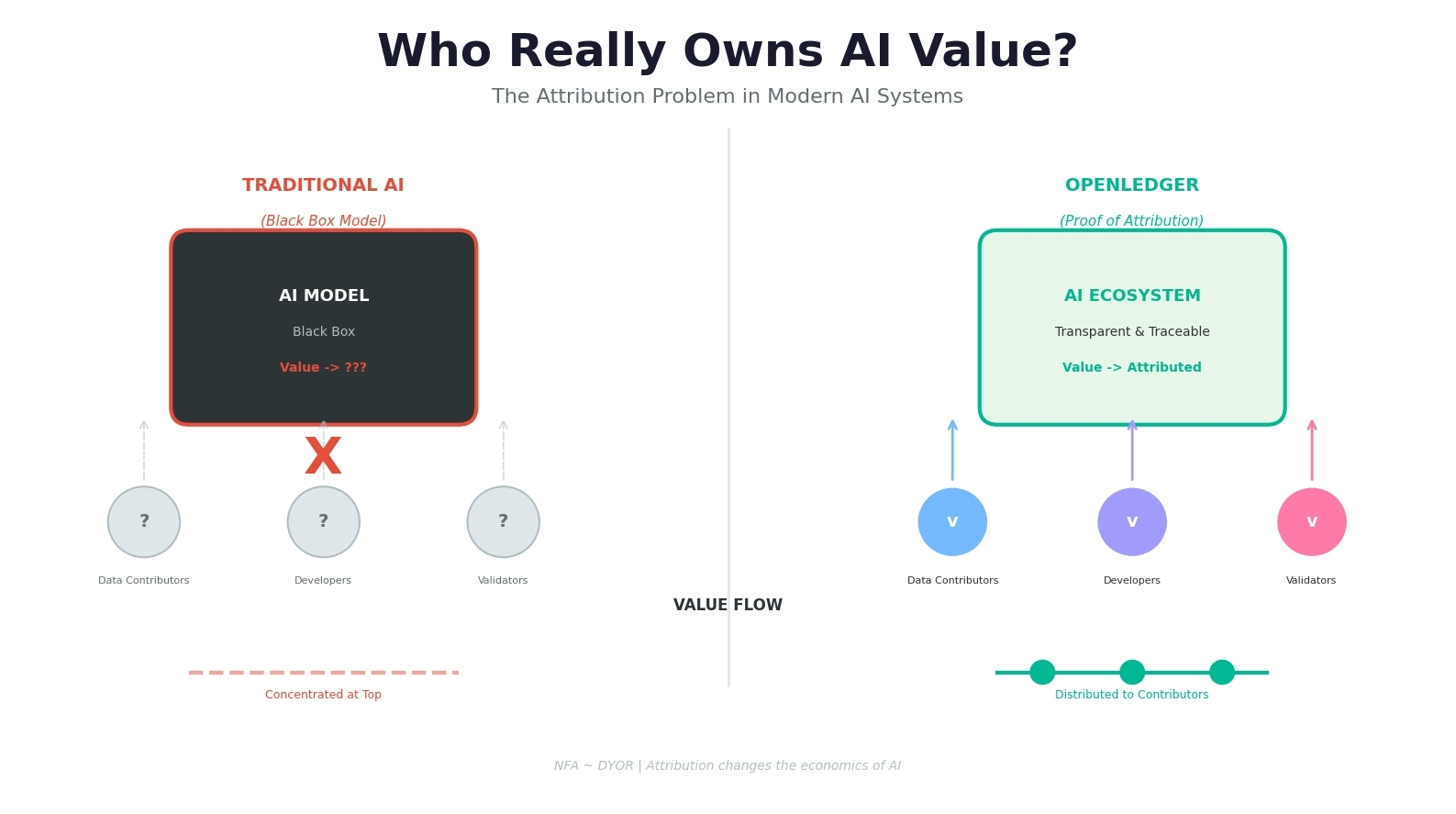
Die meisten KI-Systeme funktionieren wie eine Black Box. Menschen tragen Daten bei, Entwickler bauen Modelle, Benutzer interagieren mit Produkten, aber letztendlich konzentriert sich der Wert irgendwo oben und die Spur der Beiträge verschwindet.
Dieser Teil fühlt sich kaputt an.
Was OpenLedger für mich interessant macht, ist die Aufmerksamkeit, die es auf die Attribution legt. Die Idee, dass Beiträge innerhalb eines KI-Systems nicht einfach nach dem Training verschwinden sollten, klingt einfach, verändert aber tatsächlich die Wirtschaftlichkeit erheblich. Früher dachte ich, dass Proof of Attribution nur ein Branding-Begriff war.
Jetzt bin ich mir nicht mehr so sicher.
Wenn Datensätze die Ausgaben verbessern, Validatoren Netzwerke unterstützen und Modelle sich aufgrund unterschiedlicher Beiträge weiterentwickeln, dann könnte es sein, dass das Verfolgen von Werten in diesem Prozess wichtiger ist, als wir denken.
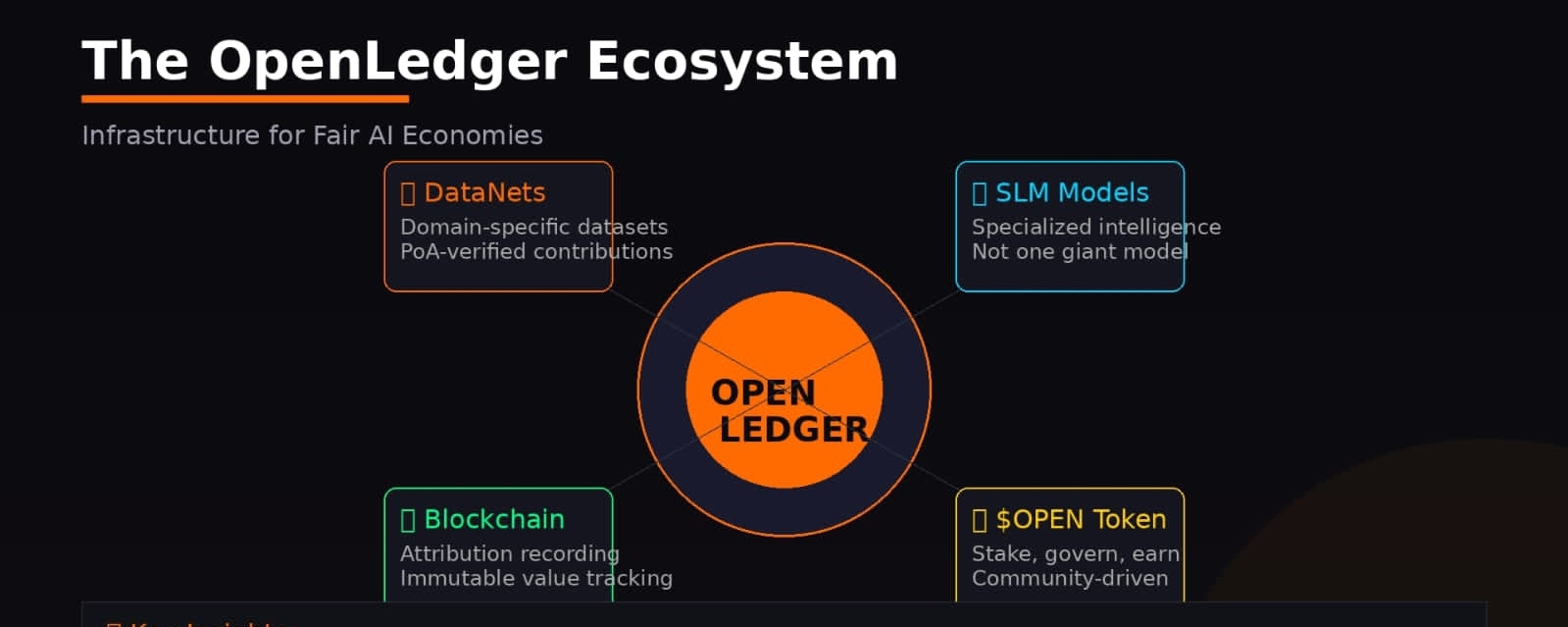
Der interessante Teil ist, dass OpenLedger nicht besessen scheint, ein riesiges KI-Modell zu bauen.
Es fühlt sich mehr wie eine Infrastruktur für spezialisierte Intelligenz an, wo verschiedene Teilnehmer beitragen, sich anpassen und potenziell vom Ökosystem profitieren können, anstatt im Prozess zu verschwinden. Dennoch bin ich nicht blind optimistisch.
Offene Systeme bringen auch echte Probleme mit sich: Daten von geringer Qualität, Spam-Anreize, Ungleichgewicht in der Governance. Diese Risiken sind real.
Aber zumindest scheint das Projekt sich ihrer bewusst zu sein, anstatt vorzugeben, dass Dezentralisierung alles magisch löst.
Vielleicht liege ich falsch. Vielleicht dominieren zentrale KI-Unternehmen weiterhin, weil Skalierung normalerweise gewinnt. Aber ich denke weiterhin, dass der zukünftige KI-Kampf nicht nur um Rechenleistung gehen könnte.
Es könnte stillschweigend zu einem Kampf um Eigentumszuweisung und darum kommen, wer den Wert erfasst, sobald die Intelligenz nützlich wird.
Das ist hauptsächlich der Grund, warum @OpenLedger immer noch auf meiner Watchlist ist.
Was denkst du darüber? Teile gerne deine Erfahrungen und Meinungen.
Hinweis: - NFA~DYOR