The more I look at AI infrastructure, the less simple the value chain feels.Most people still assume the biggest winners in AI will be the companies with the largest models or the most compute. But as systems become more specialized, another dependency keeps becoming harder to ignore: high-quality domain data created by humans who are rarely rewarded once the model goes live.
That may be the more important issue underneath the entire AI economy.A medical assistant does not become useful because it understands language alone. A legal AI system is not valuable simply because it can generate text. These systems improve because experts continuously provide corrections, structured datasets, niche context, and industry-specific knowledge over time.
Yet most contributors remain economically invisible after the training process finishes.That imbalance is part of what OpenLedger appears to be targeting through its Proof of Attribution framework.
At first glance, it is easy to categorize OpenLedger as another “AI + blockchain” project. But I think the more interesting argument is actually about ownership and contribution tracking inside AI systems themselves.
Because current AI markets mostly reward infrastructure concentration.The companies controlling models, compute, and distribution layers capture most of the value, while contributors supplying useful data often operate like temporary labor inputs rather than long-term stakeholders.OpenLedger’s thesis seems to challenge that structure directly.
The idea behind Proof of Attribution is relatively straightforward conceptually, even if the implementation is extremely difficult in practice.
Contributors submit datasets into OpenLedger’s Datanets structured data environments designed around particular domains, industries, or knowledge categories. Instead of treating all datasets equally, the network attempts to measure how much specific contributions improve AI outputs during actual inference activity.
That distinction matters.Most systems can track who uploaded information.Far fewer can track whether the information actually improved results.OpenLedger is attempting to create an attribution layer capable of measuring contribution influence rather than simple participation.
If certain datasets consistently improve output quality, relevance, or reasoning performance, contributors may receive proportional rewards tied to that influence.
That creates the foundation for what OpenLedger describes as a measurable contribution economy.And honestly, this may be one of the more important ideas emerging across crypto-AI infrastructure right now.
Because the internet has always struggled with attribution.Social platforms reward engagement.
Blockchains reward transaction validation.
AI systems reward model ownership.
But there are very few mechanisms that continuously reward knowledge contribution after deployment.OpenLedger is effectively trying to build a system where useful data behaves more like productive capital instead of disposable raw material.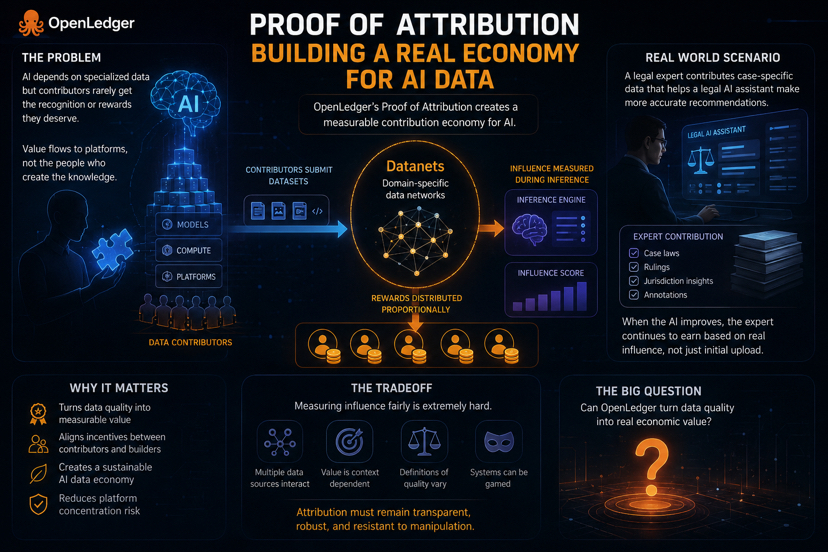
The legal industry is probably one of the clearest examples.Imagine a legal expert contributing highly curated case-law datasets focused on international commercial disputes. Over time, a legal AI assistant trained through that environment starts generating stronger contract analysis and more accurate jurisdiction-specific recommendations.
Under OpenLedger’s model, the contributor’s involvement would not end after the upload phase.Inference-level influence scoring attempts to measure whether that specific dataset materially improved downstream outputs relative to competing sources. If it did, rewards could continue flowing proportionally as the system gets used.
That changes the relationship between contributors and AI infrastructure entirely.Instead of one-time extraction, contributors potentially become long-term economic participants inside the network.This is where OpenLedger’s argument starts becoming compelling.
As AI systems mature, generic internet-scale data may become less valuable than highly specialized, continuously refined expertise. The marginal improvements could increasingly come from domain-specific contributors rather than sheer dataset size alone.
And if that becomes true, then incentive alignment becomes a serious problem.Why would experts continue supplying useful data if all economic upside remains concentrated at the application layer?
OpenLedger’s answer appears to be that sustainable AI ecosystems eventually require persistent attribution systems.Proof of Attribution is essentially an attempt to solve that coordination problem economically.
But the harder I think about it, the more difficult the implementation looks.Because measuring influence fairly inside AI systems is incredibly complex.$OPEN #OpenLedger @OpenLedger
Outputs are rarely generated from one isolated source. Multiple datasets interact simultaneously during inference. Some reinforce each other. Others overlap partially. Some contributions become more useful only under specific contexts or prompts.Even defining “value” becomes subjective.
Does the system reward factual accuracy?
User retention?
Commercial usefulness?
Reasoning quality?
Inference efficiency?
Different definitions could completely change how rewards are distributed across the network.And that creates another problem.
The moment attribution starts carrying real financial value, people will naturally begin optimizing around the scoring system itself. Some contributors may focus more on maximizing measurable influence than on contributing genuinely useful data. We’ve seen similar behavior across social platforms, SEO ecosystems, and even parts of DeFi, where incentives slowly reshape participant behavior over time.
That does not mean the model cannot work.But it does mean attribution economies are probably much harder to maintain than they initially appear on paper.
Especially once large financial incentives begin forming around dominant Datanets.There is also a broader crypto implication here that I think matters.
If Proof of Attribution succeeds even partially, it could reshape how digital ownership works inside AI economies. Data contributors stop behaving like invisible suppliers and start behaving more like infrastructure stakeholders with measurable economic weight.
That would represent a meaningful structural shift away from pure platform concentration.
Whether OpenLedger can actually achieve that remains uncertain.But the project is at least asking a more interesting question than most AI narratives currently focus on.
So the real question is not whether OpenLedger can create attribution metrics.It is whether those metrics can remain credible, manipulation-resistant, and economically fair once real competitive pressure starts building around them.$OPEN #OpenLedger @OpenLedger 
Artikel

Can Proof of Attribution Create a Real Economy for AI Data?
--
Haftungsausschluss: Die hier bereitgestellten Informationen enthalten Meinungen Dritter und/oder gesponserte Inhalte und stellen keine Finanzberatung dar. Siehe AGB.