
Cele mai multe echipe din crypto care adaugă AI pe aplicațiile lor se confruntă cu aceeași problemă. Modelul dă răspunsuri, UI-ul arată bine, iar utilizatorii ar putea să-l găsească chiar util. Dar în momentul în care începi să întrebi de unde a venit acel răspuns, care date au mișcat cu adevărat acțiunile, sau cine a contribuit cu informațiile bune, totul devine rapid o cutie neagră. $OPEN #OpenLedger @OpenLedger
Asta e exact motivul pentru care OpenLedger merită să fie urmărit. $Pentru constructori, a adăuga un alt LLM nu mai e partea grea. Provocarea reală este să construiești produse AI unde stratul de date nu e complet opac, unde contributorii nu sunt invizibili și unde poți urmări efectiv cum s-a realizat output-ul final. În crypto, asta contează mai mult decât în aplicațiile obișnuite pentru consumatori. Traderii, cercetătorii și instituțiile nu vor doar răspunsuri rapide — vor să știe că sursele sunt solide, că sistemul poate fi auditabil și că există o adevărată responsabilitate când lucrurile iau o întorsătură proastă.
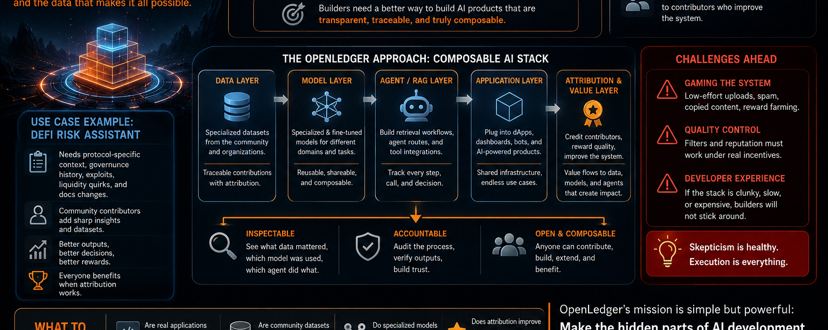
Ceea ce îmi place la abordarea OpenLedger este că tratează datele, modelele și agenții ca piese compozabile ale unui stack în loc de un produs sigilat. Ca dezvoltator, ar trebui să poți să aduci seturi de date specializate, să le conectezi la modelele potrivite, să construiești fluxuri de recuperare sau rute pentru agenți și să vezi ce adaugă valoare. Asta atinge una dintre cele mai mari slăbiciuni ale AI-ului acum: atribuirea. Gândește-te la un asistent de risc DeFi. Un model generic poate explica lichidările sau stablecoin-urile în termeni generali. Dar utilizatorii serioși au nevoie de context specific protocolului, dezbateri vechi de guvernare, ciudățenii de lichiditate, istoria exploatărilor și modificările documentației care nu apar în titluri. Dacă cineva contribuie cu note clare despre un protocol sau un set de date îmbunătățește semnificativ rezultatele, vrei să știi asta — și ideal ar fi să fie recompensat.
Fără acea trasabilitate, construiești doar o altă interfață strălucitoare pe un ingredient misterios. Aceeași logică se aplică la setările RAG și aplicațiile bazate pe agenți. Tot mai multe echipe construiesc sisteme care nu doar răspund la întrebări, ci recuperează context, apelează la instrumente și dirijează sarcini. În crypto, păstrarea unui istoric al acelui proces este valoros pentru cercetare, conformitate, gestionarea trezoreriei și instrumente de trading.
OpenLedger încearcă să se îndepărteze de modelul vechi în care o echipă strânge datele, le optimizează în tăcere și trimite un produs închis. În schimb, seturile de date pot deveni active comune, modelele pot fi specializate și reutilizabile, iar agenții pot fi conectați la diferite aplicații. Dacă atribuirea funcționează cu adevărat, valoarea poate curge mai bine către persoanele și datele care îmbunătățesc sistemul. Desigur, scepticismul este sănătos aici. Atribuirea sună grozav până introduci stimulente reale. Apoi, devii ținta jocurilor — încărcări cu efort redus, seturi de date spam, conținut copiat și oameni care cultivă recompense. Asta nu este un risc minor; este ceea ce se întâmplă de obicei. OpenLedger trebuie să dovedească că filtrele lor de calitate și mecanismele de reputație pot supraviețui activității economice reale, nu doar demo-urilor frumoase.
Experiența dezvoltatorilor va face sau va distruge totul. Indiferent cât de elegantă este viziunea, dacă stack-ul este greoi, lent, slab documentat sau scump, constructorii vor pleca. Crypto se mișcă repede, iar oamenii nu rămân doar pentru ideologie. Semnalele pe care le urmăresc sunt clare:
• Se construiesc aplicații reale sau doar demo-uri de tip campanie?
• Seturile de date ale comunității sunt de fapt utile încât alte echipe să vrea să le folosească?
• Modelele și agenții specializați îmbunătățesc semnificativ fluxurile de lucru?
• Cel mai important, layer-ul de atribuție îmbunătățește calitatea datelor sau doar pompează volumul contribuției?
Șansa reală a OpenLedger este să facă părțile ascunse ale dezvoltării AI inspectabile: ce date au contat cu adevărat, cine le-a adus, ce agent a efectuat munca și cum a circulat valoarea. Nu este vorba despre a face AI-ul să sune mai interesant. Este vorba despre construirea unei infrastructuri care să fie mai utilizabilă, mai responsabilă și cu adevărat deschisă contribuției.
Întrebarea cea mare este dacă poate transforma datele urmărite și piesele AI compozabile în ceva de care dezvoltatorii se bazează cu adevărat zi de zi sau dacă rămâne o idee captivantă așteptând o potrivire reală între produs și piață.$OPEN #OpenLedger  @OpenLedger
@OpenLedger