

I checked the attribution dashboard one morning expecting to see settlement activity.
the model had served several hundred requests the previous week.
the attribution balance was still zero.
that's the moment that stuck with me.
not because the model wasn't being used.
it was.
the usage existed.
the contribution trail existed.
the value had been created.
the settlement never arrived.
I spent time assuming I'd misconfigured something.
checked the contribution records.
checked the deployment.
checked whether inference was routing through the attributed version.
everything looked correct.
usage was real.
settlement wasn't there.
for a while I couldn't tell whether the problem was my contribution, the deployment, or the attribution system itself.
everything suggested the model was creating value.
the zero balance suggested that value belonged to nobody.
those two things couldn't both be true.
it took a while to find the actual problem.
the attribution system processed settlement in batches.
there was a minimum volume threshold.
my model's inference volume had fallen below it.
not by much.
but below it.
so the batch ran.
my contributions weren't included.
the balance stayed at zero despite real usage.
I keep thinking of that as the attribution cliff.
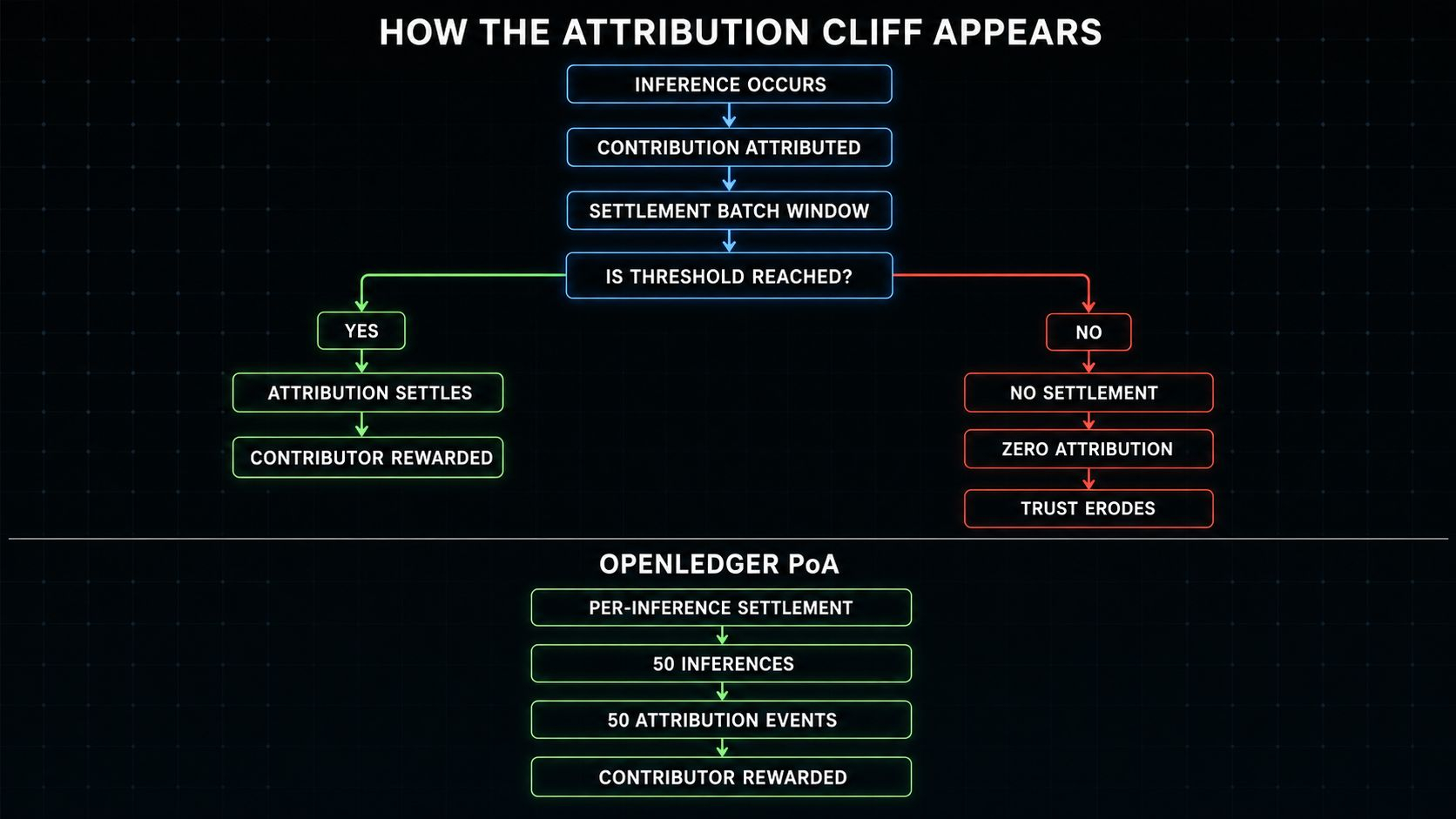
the threshold below which usage stops generating attribution settlement regardless of how much value was actually created.
that's what makes the cliff dangerous.
the intuitive model is proportional.
more usage means more attribution.
less usage means less.
the cliff turns that relationship into a binary outcome.
a contributor with fifty inferences receives nothing.
not less.
nothing.
which means the contributor isn't just missing payment.
they're missing proof that the attribution system worked at all.
from their perspective, usage happened and the reward never appeared.
that's exactly the kind of experience that makes people stop trusting a system long before they stop using it.
high-volume models clear the threshold.
specialized models often don't.
which means the contributors with the deepest expertise are often the least likely to be rewarded.
not because their knowledge isn't valuable.
because their usage is naturally lower volume.
that's the part of OpenLedger's Proof of Attribution direction I keep coming back to.
not whether PoA records contributions.
whether attribution settlement flows at the granularity required for specialized contributors to find it worthwhile.
per-inference settlement is a different architecture than batch settlement.
fifty inferences generate fifty attribution events.
not zero because fifty didn't clear a threshold.
that's where $OPEN becomes mechanically important.
if specialized contributors stop contributing, the network gains breadth and loses depth.
$OPEN only benefits if attribution remains economically viable for contributors who generate expertise rather than volume.
the part I'm still watching is whether per-inference settlement scales efficiently enough to support that model over time.
batch processing exists for a reason.
I don't know where that threshold is.
but I know the attribution cliff is real.
and I know it's selecting against exactly the expertise that's hardest to replace.