I'm looking @OpenLedger deeper as I can and read 22 pages of white paper twice for my personal interests or satisfaction and still OpenLedger on my watchlist.
I think everyone's talking about AI like the models are the whole story. Bigger parameters, faster inference, cheaper compute I believe that's where all the attention goes. and sure, that matters. But there's a layer underneath all of it that almost nobody's talking about, and i think it's the one that actually determines who wins long-term.
I feel most of people discussing AI models.
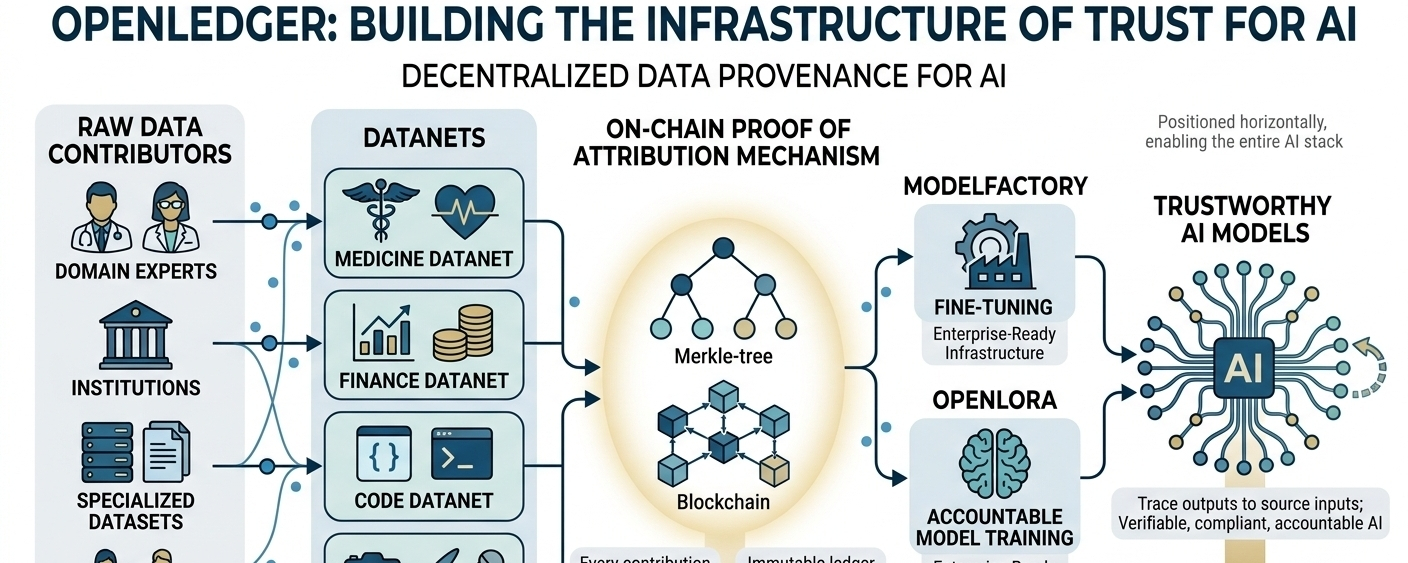
About not just having data — but knowing where it came from, who contributed it, how fresh it is, and whether the model that learned from it can actually be held accountable. right now none of that infrastructure exists in any meaningful way. It's a black box on top of a black box.
Exactly... that's the gap openledger is building into.
Guys... the core idea is simple but genuinely underappreciated — if you treat data as a productive asset rather than a raw input, the whole economics of AI changes. All contributors get attribution. AI models get traceable provenance. And the system as a whole gets something it desperately needs right now: trust.
Which thing caught my attention differently. Because their proof of attribution mechanism is what makes this real rather than theoretical. Almost every data contribution gets verified and recorded on-chain, which means when a model produces an output, you can actually trace what fed it. I think that's not just philosophically interesting — it's legally and commercially important as the regulatory environment around AI tightens globally.
The most important datanets concept, which is essentially specialized data pipelines for specific domains. Instead of one massive undifferentiated training corpus, you get structured, curated flows that reflect actual expertise. Also combined with modelfactory and openlora for fine-tuning, the whole stack starts to look less like an experiment and more like infrastructure that enterprises could actually build on.
Why I feel OpenLedger is unique or different And what keeps me interested is that openledger isn't trying to compete with openai or anthropic on the model side. If we look at stats they're going horizontal — positioning themselves as the layer that all AI development eventually has to plug into if it wants verifiable, compliant, accountable training data. We can understand that's a different kind of bet, and honestly a smarter one. Surely the model wars will produce a few winners. In a result the infrastructure layer tends to produce the winner.
The another important part i'm still watching is adoption velocity. Yesss... the thesis only compounds if datanets actually attract real contributors — domain experts, institutions, specialized datasets. That's the variable. The technology seems credible. The question is whether the incentive design is strong enough to bootstrap meaningful supply before a well-funded competitor figures out the same problem.