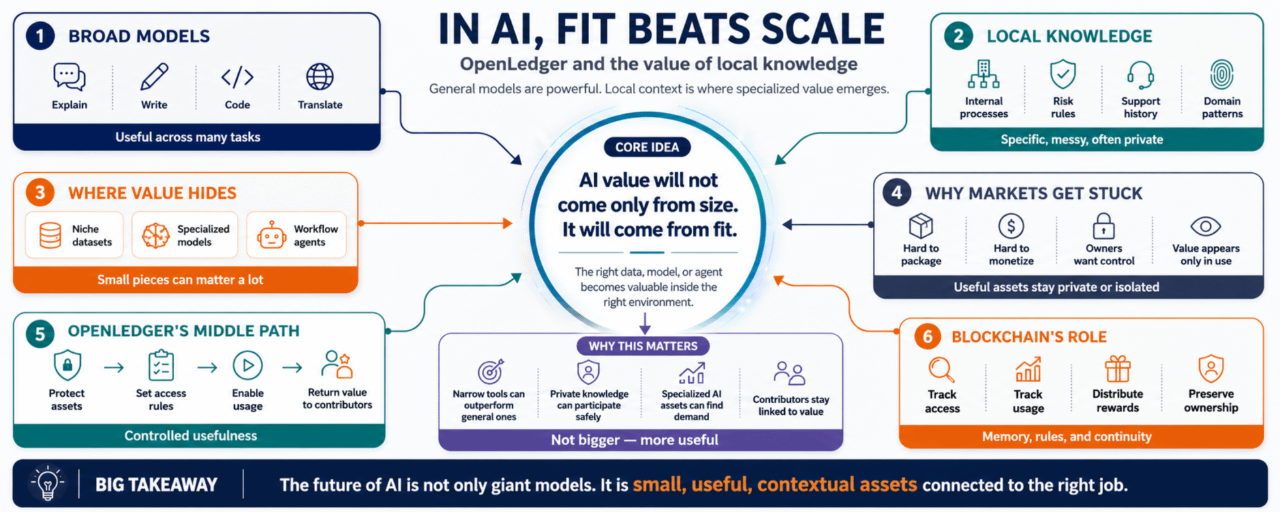
Sincer, inteligența generală e utilă, dar cunoștințele locale sunt acolo unde se ascunde mult din valoarea reală.
Asta sună puțin banal, dar contează.
Un model mare poate răspunde la multe lucruri. Poate explica, rezuma, scrie, traduce, codifica și raționa pe subiecte variate. E impresionant. Dar când munca devine specifică, modelul adesea are nevoie de altceva.
Are nevoie de context.
Nu orice fel de context.
Contextul potrivit.
Procesul intern al unei companii.
Fluxul de pacienți al unui spital.
Regulile de risc ale unui trader.
Un istoric al cererilor echipei de suport.
Întârzieri mici în rețeaua de logistică.
Tiparele documentelor echipei legale.
Obiceiurile de codare ale echipei de dezvoltare.
Acestea nu sunt întotdeauna lucruri pe care internetul deschis le poate învăța bine.
Sunt locale.
Specifice.
Dizolvate.
Adesea private.
Și aici devine AI-ul mai interesant.
Pentru că viitorul s-ar putea să nu fie doar despre cine are cel mai mare model. S-ar putea să fie și despre cine poate conecta modele utile la cele mai relevante cunoștințe locale fără a pierde controlul asupra lor.
@OpenLedger se încadrează în acest gând.
Nu ca o promisiune zgomotoasă despre AI și blockchain. Mai degrabă ca un sistem care încearcă să ofere activelor AI locale o modalitate de a exista într-o piață mai largă.
Datele, modelele și agenții nu sunt toți aceiași. Dar au un lucru în comun: devin mai valoroși când sunt conectați la cazul de utilizare corect.
Un set de date dintr-o afacere poate părea plictisitor din exterior.
Un model mic antrenat pe o sarcină îngustă poate să nu pară important.
Un agent construit pentru un flux de lucru poate să nu simtă ca un produs mare.$PORTAL
Dar în interiorul mediului corect, aceste lucruri pot conta foarte mult.
De obicei, poți spune asta după ce ai observat AI-ul în muncă reală. Răspunsul generic este adesea doar începutul. Răspunsul util vine după ce sistemul înțelege contextul. Termenii pe care îi folosește lumea. Scurtăturile pe care le iau. Riscurile pe care le evită. Modelele care se repetă liniștit în timp.
Acest tip de cunoștințe este greu de ambalat.
Și chiar mai greu de monetizat.
Dacă o companie are date locale utile, s-ar putea să nu vrea să le vândă. Dacă un dezvoltator are un model ajustat pentru o industrie, s-ar putea să nu vrea să fie absorbit într-o platformă mai mare. Dacă un agent funcționează bine într-un flux de lucru specific, valoarea sa s-ar putea să nu fie evidentă până când cineva îl folosește efectiv.
Așa că piața rămâne blocată.
Cunoștințele utile rămân private.
Modelele utile rămân izolate.
Agenții utili rămân mici.
#OpenLedger pare să încerce să creeze o cale de mijloc pentru asta.
O modalitate ca activele AI să fie utilizabile fără a deveni complet detașate de sursa lor. O modalitate ca cunoștințele locale să călătorească sub reguli. O modalitate ca valoarea să revină dacă acea cunoaștere ajută pe cineva să construiască ceva util.
Aceasta este o idee subtilă.
Nu este același lucru cu a face totul deschis. Unele cunoștințe nu ar trebui să fie deschise. Unele date necesită limite. Unii agenți ar trebui să opereze doar în anumite condiții.
Dar cunoștințele închise au, de asemenea, o problemă. Dacă nu se conectează niciodată la nimic, valoarea lor rămâne prinsă.
Așa că poate întrebarea reală nu este deschis versus închis.
Este utilitatea controlată.
Poate un activ să rămână protejat și totuși să participe?
Poate un model să fie specializat și totuși să găsească cerere?
Poate un agent să fie îngust și totuși să câștige din muncă reală?
Poate cunoașterea locală să devină parte din AI fără a fi complet înghițită?
Aici blockchain-ul poate avea un rol, dacă este folosit cu atenție.
Un registru poate ajuta la urmărirea accesului, utilizării și recompenselor. Poate oferi activelor AI o continuitate. Poate face relația dintre contributor și utilizator mai puțin dependentă de încrederea privată. Nu perfect, desigur. Dar poate suficient pentru a face posibile noi tipuri de partajare.$PLAY
Și acest lucru contează pentru că AI devine mai contextual.
Modelul broad este doar un strat. În jurul lui, vor fi seturi de date mai mici, amintiri private, modele specializate, fluxuri de lucru și agenți care înțeleg un domeniu mai bine decât un sistem general.
Asta nu îi face mai mari.
Îi face utili.
Există o diferență.
Un agent mic care gestionează bine un proces de afaceri poate crea mai multă valoare reală decât un instrument general care face multe lucruri pe jumătate. Un set de date dintr-un domeniu de nișă poate conta mai mult decât un set de date public gigant atunci când sarcina este îngustă. Un model antrenat pentru un flux de lucru poate deveni valoros pentru că reduce greșelile în acel loc.#StrategyHintsNewBTCBuy
După un timp, devine evident că valoarea AI nu va veni doar din scală.
Va veni din potrivire.
Focalizarea OpenLedger pe date, modele și agenți pare să se așeze în jurul acelei schimbări. Oferă un cadru pentru piesele care fac AI-ul să se potrivească unui mediu specific. Aceste piese au nevoie de proprietate, reguli de acces și o cale de monetizare.
Fără asta, cunoștințele locale rămân închise, sau sunt absorbite de platforme mai mari fără prea multă vizibilitate.
Niciun rezultat nu se simte complet.
Calea mai echilibrată este mai greu de parcurs. Înseamnă să lași activele AI utile să se miște, dar cu memorie. Cu reguli. Cu o modalitate ca contributorii să rămână conectați la valoarea pe care au ajutat să o creeze.
OpenLedger încearcă să lucreze undeva în acel spațiu.
Nu în jurul celei mai zgomotoase versiuni de AI.
Ci în jurul celei mai liniștite.
Cea în care o mică bucată de cunoștințe, în locul potrivit, poate conta mai mult decât un model foarte mare care încearcă să știe tot.
@OpenLedger #OpenLedger $OPEN
Articol
Pe măsură ce AI-ul crește, un lucru devine din ce în ce mai clar.
Declinarea răspunderii: include opinii ale terților. Nu constituie recomandări. Binance AI poate fi utilizat fără garanție. Consultați Termenii și condițiile