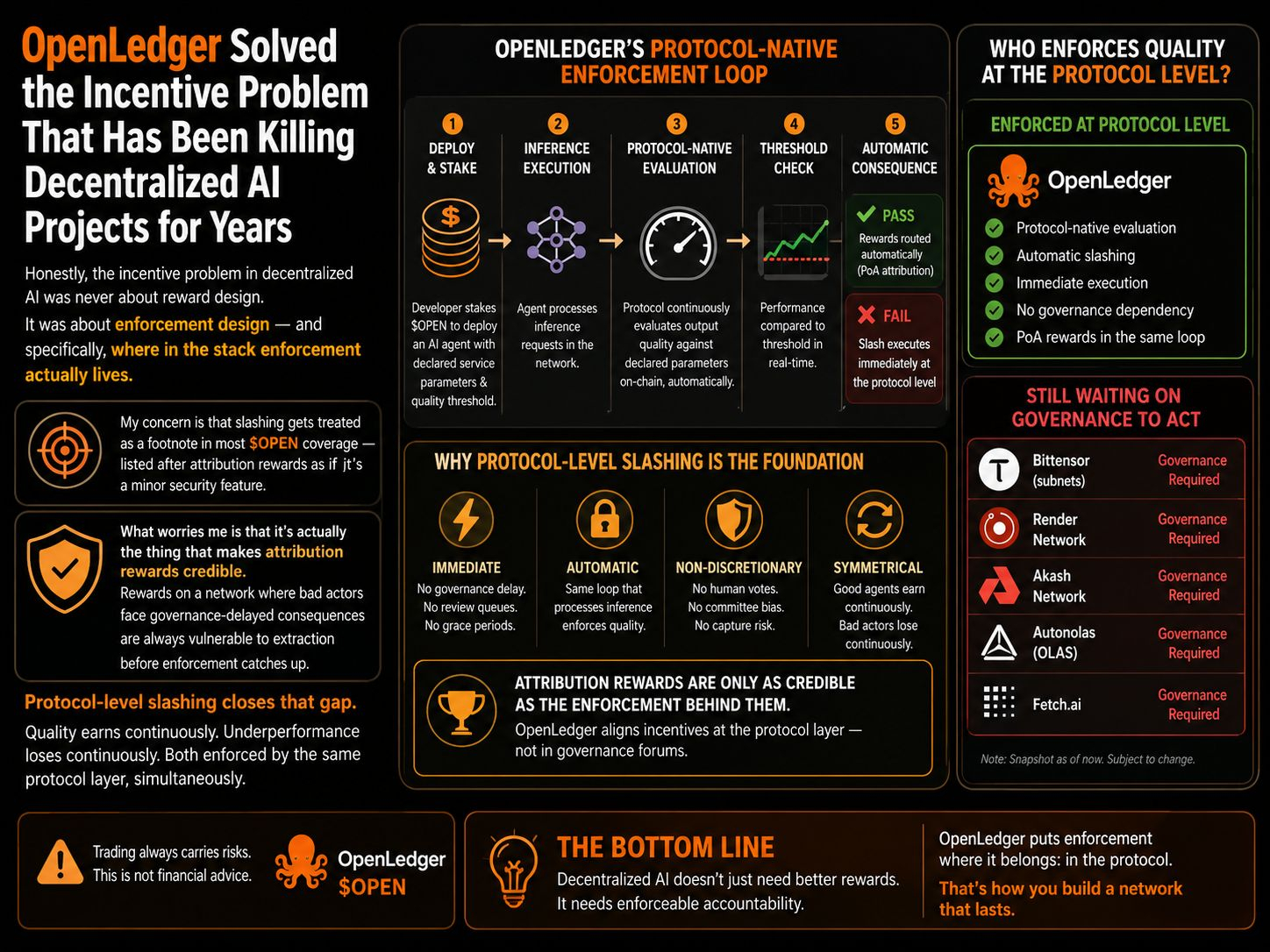
sincer, problema stimulentului în AI decentralizat nu a fost niciodată despre designul recompenselor. a fost despre designul aplicării — și, în special, unde în stivă se află de fapt aplicarea. 😂
ce m-a atras este că trigger-ul de penalizare de la OpenLedger este nativ protocolului, nu depinde de guvernanță. pentru a lansa un agent AI pe rețea, un developer mizează $OPEN. protocolul evaluează continuu calitatea output-ului agentului în raport cu parametrii de serviciu declarați la lansare — on-chain, automat. dacă performanța scade sub prag, penalizarea se execută la nivel de protocol. nicio votare de guvernanță nu o inițiază. nicio comisie de revizuire nu o programează. nicio fereastră de întârziere în care agentul subperformant continuă să încaseze taxe în timp ce cazul său este în așteptare. bucla de evaluare este aceeași buclă care procesează inferența: în momentul în care performanța scade sub pragul declarat, consecința economică este automată și imediată. și pentru că PoA rulează în aceeași conductă, rutarea recompenselor pentru agenții buni este la fel de automată — fără oameni care să ia decizii de atribuire caz cu caz. calitatea câștigă continuu. subperformanța pierde continuu. ambele fiind aplicate de aceeași strat de protocol, simultan.
îngrijorarea mea este că penalizările sunt tratate ca o notă de subsol în majoritatea acoperirilor deschise, listate după recompensele de atribuire, ca și cum ar fi o caracteristică minoră de securitate.
ce mă îngrijorează este că, de fapt, aceasta este ceea ce face recompensele de atribuire credibile. recompensele pe o rețea unde actorii răi se confruntă cu consecințe întârziate de guvernanță sunt întotdeauna vulnerabile la extracție înainte ca aplicarea să ajungă din urmă. penalizările la nivel de protocol închid acea breșă.
ce rețele de agenți AI urmărești care impun calitate la nivel de protocol și care așteaptă încă un vot de guvernanță pentru a prinde un actor rău?