
前段时间我帮朋友梳理过AI数据变现的实操问题,真切体会到行业里最无奈的现状。无数个人和小团队辛苦标注、清洗的训练数据,一旦提交给平台就彻底失去权属,后续模型迭代、商业落地产生的所有价值,创作者都无法参与分配。我看过太多DeAI项目只是空谈数据确权,直到我逐字研读@OpenLedger 官方技术文档后,才明白它主打的归属证明共识,是目前少数真正落地、可链上验证的AI价值分配底层机制。
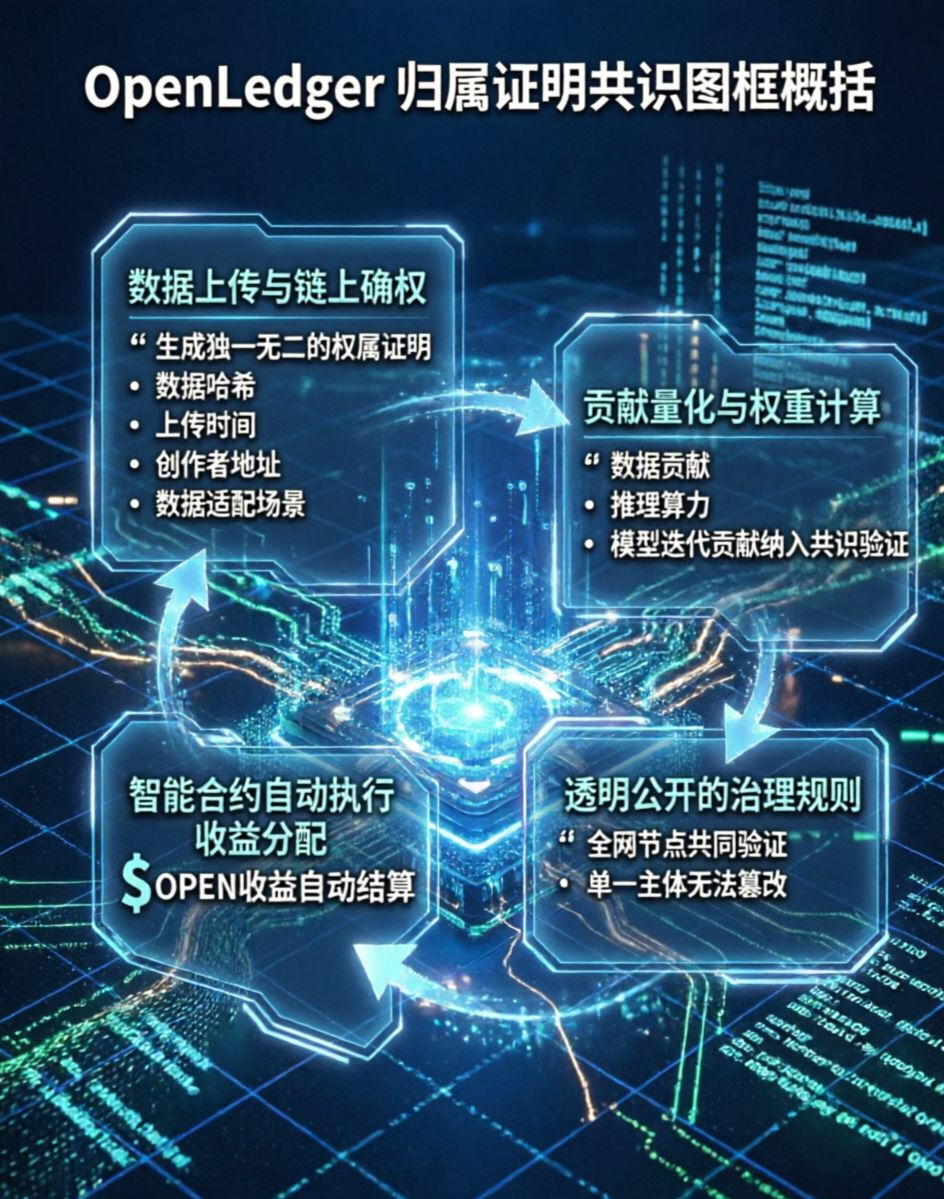
我看过市面上九成以上Layer2和AI公链的底层共识,基本都是在PoS共识上做参数微调,全网记账权、出块权益全部绑定代币质押数量,本质还是资本主导的规则。但是OpenLedger完全换了一套底层逻辑,它摒弃了单纯的质押权重体系,把数据贡献、推理算力、模型迭代贡献纳入全网共识验证体系,我觉得这是整个项目最核心、最容易被普通用户忽略的硬核创新。不同于普通的激励活动,归属证明是嵌入底层的共识规则,是整条网络安全运行、权益分配的核心准则,而非简单的链上功能。
我专门拆解过这套机制的完整运行链路,这里分享下我自己的实操理解。任何用户将合规有效的结构化数据、标注数据上传至OpenLedger数据网络后,节点会完成多轮交叉验证,确认数据有效后会生成独一无二的链上权属证明。这份证明包含数据哈希、上传时间、创作者地址、数据适配场景四大核心信息,永久存储不可篡改。后续这些数据被调用参与AI模型训练、链上推理服务时,共识层会实时计算每一份原始数据的贡献权重,按照固定算法自动分配$OPEN 收益实现一次贡献持续获利。

我实测过链上小型数据贡献的收益结算流程,整个过程完全智能合约自动执行,没有人工干预的空间,结算精度和溯源完整度远超同行项目。不过我客观分析后发现,这套机制存在天然的技术取舍。极致精细的权属溯源和权重计算,会大幅增加节点的运算负担,相比传统极简共识机制,它的区块确认耗时会略有增加。我推断,当未来网络迎来大规模商用、海量AI推理任务并发时,节点算力压力会持续攀升,如果不能持续优化轻量化算法,网络整体吞吐量会受到一定限制。
我长期观察DeAI赛道发现,多数项目的贡献奖励极度模糊,没有统一量化标准,平台方可以随意调整奖励比例,用户权益根本没有保障。OpenLedger的优势就在于,所有贡献量化规则、权重计算公式、收益分配比例全部公开透明,由全网节点共同验证共识,单一主体无法篡改规则。但我也发现了现存的短板,目前机制对数据质量的分层判定还不够细致,高质量的垂直领域专业数据,和普通通用数据的收益差异化不够明显,长期来看,很难持续激励优质核心数据持续上链。很多用户只会关注盘面的短期起伏,但我始终认为,公链和AI结合的项目,最终比拼的一定是底层机制的落地能力。归属证明共识解决了行业多年的痛点,把AI生产环节里每一份细碎的劳动价值,都做到链上确权、量化、分配,彻底改变了中心化平台垄断价值的格局。

综合我长期的观察、机制拆解和链上实测,我对这套机制的看法很清晰。归属证明共识有着传统共识不具备的公平性和实用性,精准适配DeAI的发展需求,为普通参与者提供了透明可信的价值获取渠道。不过它目前仍存在运算效率偏低、数据评级精细化不足的问题,需要后续版本持续迭代优化。我认为这套独有的底层共识,是OpenLedger最核心的竞争底气,只要持续优化技术短板、完善治理规则,它会持续拉开和同质化DeAI项目的差距,走出属于自己的落地发展路线。#OpenLedger