Îmi imaginez un viitor în care o mică echipă web3 stă într-un apel de guvernanță târziu, cu ochii obosiți pe un ecran, cifrele trezoreriei pe altul și un agent AI citind liniștit ani de dezbateri ale comunității în fundal.
Apoi cineva întreabă: „Care parte a acestei propuneri are dovezi mai puternice?”
Agentul nu răspunde ca un magician. Nu aruncă un paragraf lustruit și nu cere tuturor să aibă încredere în el. Deschide memoria din spatele răspunsului. O notă de risc dintr-un vechi thread de forum. O defalcare a bugetului de la un contributor. O problemă cu smart contract-ul de la un dezvoltator. O avertizare de la cineva care a văzut un vot similar să meargă prost înainte. Fiecare piesă are o urmă. Fiecare urmă are o sursă.
Aceasta este versiunea de AI în care vreau să cred.
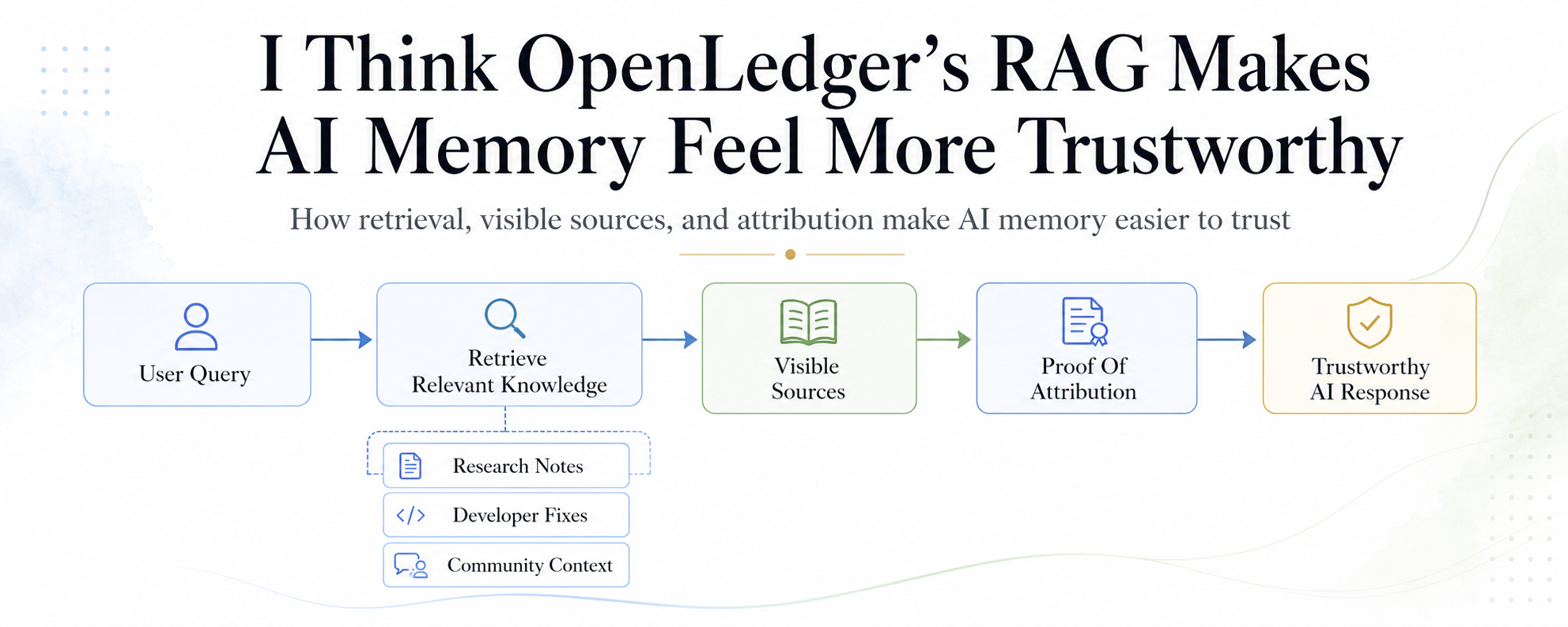
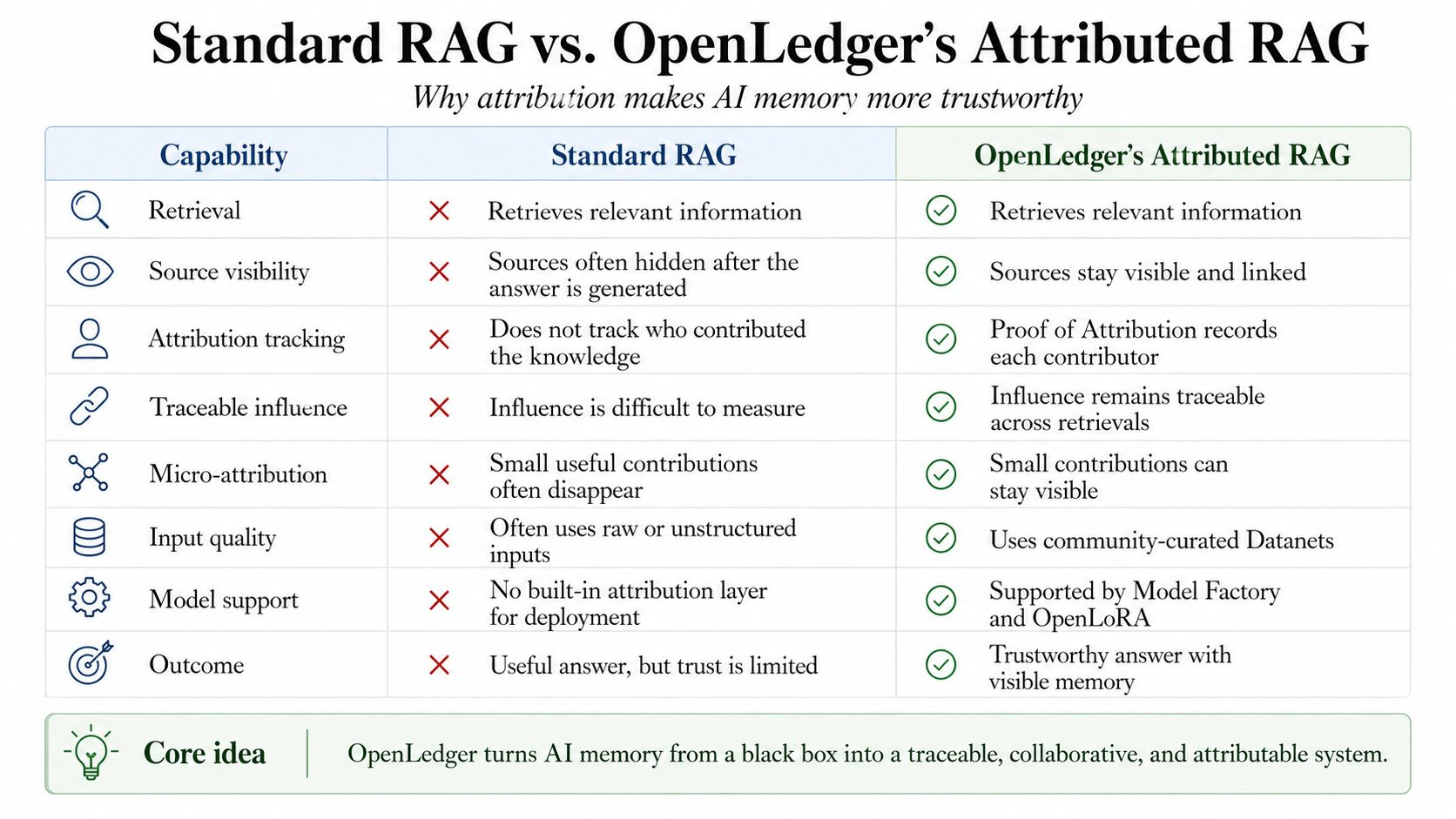
Pentru că cea mai mare problemă cu memoria AI nu este doar dacă își amintește corect. Problema mai profundă este dacă își amintește cu onestitate. RAG-ul standard ajută un sistem AI să recupereze informații externe înainte de a oferi un răspuns. Asta este util. Dar majoritatea sistemelor RAG au totuși o mică defectiune tăcută. Ele pot folosi cunoștințele umane fără a păstra omul vizibil.
Văd viziunea RAG a lui @OpenLedger diferit. Pentru mine, nu este doar un instrument de memorie. Este o modalitate de a oferi memoriei AI un proprietar.
Vechea internet ne-a arătat deja ce se întâmplă când oamenii creează valoare, dar platformele capturează harta. Scriitorii au scris. Comunitățile au explicat. Dezvoltatorii au împărtășit soluții. Cercetătorii au publicat note. Utilizatorii au antrenat sistemele de recomandare cu fiecare clic și comentariu. Apoi valoarea a mers către platforme, în timp ce oamenii care au modelat cunoștințele au devenit adesea zgomot de fond.
Acum AI-ul face aceeași problemă mai acută.
Cunoștințele umane intră într-un model. Modelul produce un răspuns. Răspunsul arată curat. Dar de unde a venit partea utilă? Cine a ajutat să o modeleze? Cine a corectat datele slabe? Cine ar trebui să fie amintit când răspunsul devine valoros?
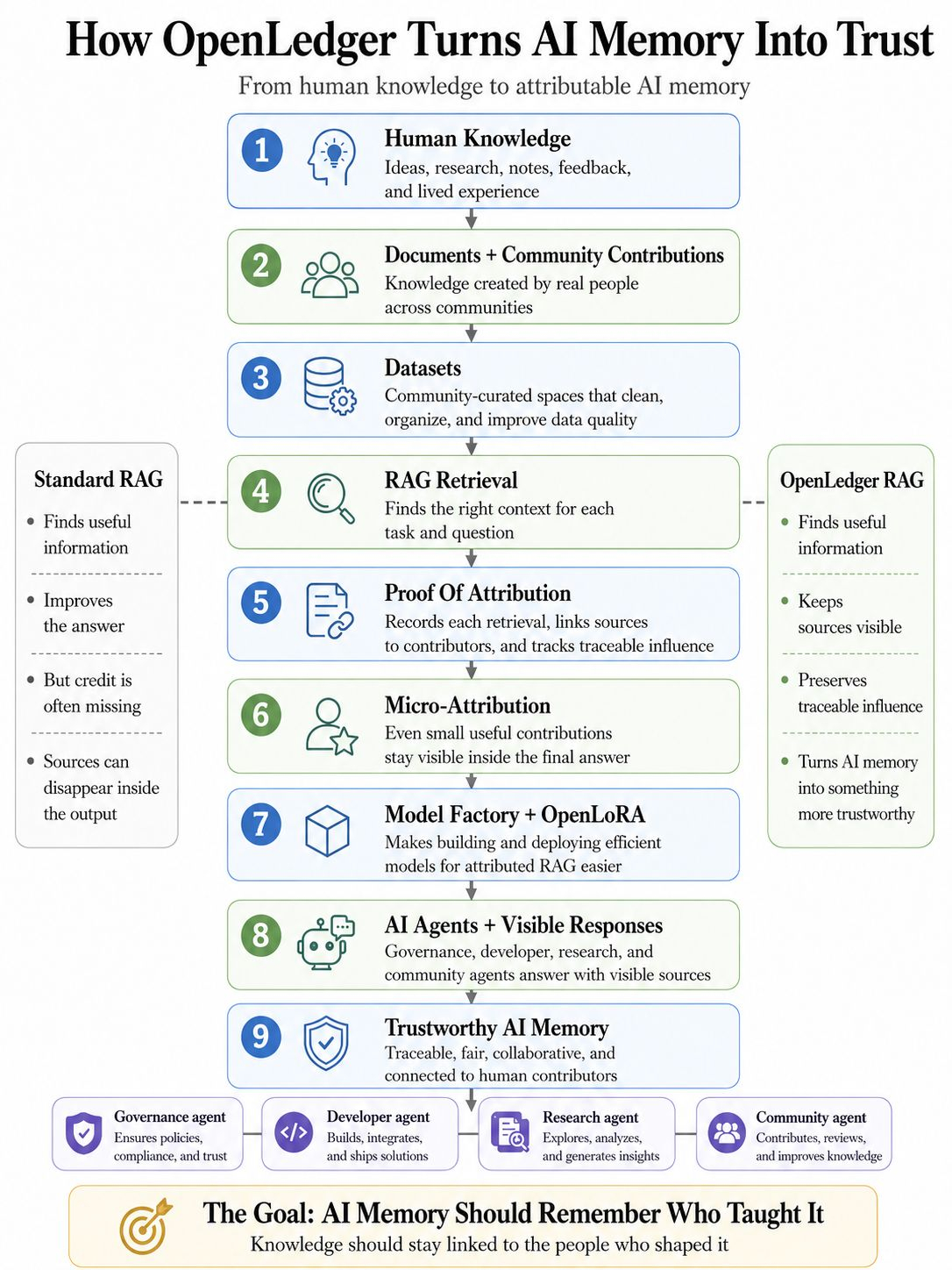
Aici dovada de atribuire contează. În designul OpenLedger, atribuirea nu este tratată ca o mică notă de subsol după răspuns. Devine parte din sistemul însuși. Fiecare recuperare poate fi înregistrată. Documentele pot rămâne legate de contribuabili reali. Influența poate deveni de urmărit. Piese mici, dar utile de cunoștințe pot primi micro-attribuire în loc să fie înghițite de mașină.
Gândește-te la un agent de guvernare în timpul unui vot serios în DAO.
Propunerea nu e simplă. Afectează cheltuielile din trezorerie, stimulentele viitoare și încrederea comunității. Un agent AI normal ar putea rezuma situația într-un mod lin, dar răspunsul poate părea totuși că plutește în aer. Cu RAG atribuit, agentul poate arăta care documente au modelat secțiunea de risc, ce contribuabili au oferit contextul votului anterior și ce note de cercetare au influențat explicația finală. Dezbaterea devine mai puțin despre încrederea oarbă și mai mult despre memorie vizibilă.
Acum imaginează-ți un agent dezvoltator ajutând un constructor să rezolve o problemă cu un contract inteligent.
Agentul citește note de audit, rapoarte vechi de erori, exemple verificate și explicații ale contribuabililor din datanet-uri. Aceste datanet-uri contează deoarece datele brute sunt haotice. Postări aleatorii, fișiere dispersate, note parțial scrise și comentarii învechite nu pot deveni automat o memorie bună. Au nevoie de structură. Au nevoie de curățare comunitară. Au nevoie de calitate. Datanet-urile transformă acel zgomot în spații de cunoștințe organizate unde RAG-ul poate recupera inputuri mai bune.
Aici, atribuirea schimbă rezultatul. Dezvoltatorul obține răspunsul, dar persoana care a scris soluția utilă nu dispare. Nota de securitate rămâne vizibilă. Influența contribuabilului rămâne conectată. Agentul devine mai mult decât un scurtcircuit. Devine un pod între munca umană și răspunsul mașinii.
Un agent de cercetare arată aceeași idee dintr-o altă perspectivă.
Imaginează-ți un cercetător care studiază o nouă economie de agenți. AI-ul extrage din lucrări tehnice, note de guvernare, rapoarte de model și explicații scrise de comunitate. Fără atribuire, răspunsul poate suna încrezător, dar se simte fără rădăcini. Cu dovada de atribuire, răspunsul poate purta o urma de memorie. Ce sursă a modelat afirmația? Ce document a susținut comparația? Ce contribuabil a adăugat contextul lipsă?
Nu e mai aproape de cum ar trebui să funcționeze cunoștințele serioase?
Apoi există agentul comunității, poate cel mai uman exemplu dintre toate.
Un membru al comunității scrie un avertisment scurt după testarea unui instrument. O altă persoană adaugă un ghid simplu. Cineva altcineva explică un caz de utilizare local în limbaj simplu. Singure, aceste piese pot părea mici. Într-un datanet curat, pot deveni parte din memoria AI-ului viitor. Prin micro-attribuire, chiar și o mică contribuție utilă poate păstra identitatea sa atunci când ajută un răspuns mai târziu.
Asta este puternic pentru că majoritatea oamenilor nu creează seturi mari de date. Ei creează fragmente. Note. Corecturi. Exemple. Avertismente. Viziunea OpenLedger oferă acelor fragmente o șansă mai bună de a rămâne conectate la proprietarii lor.
Desigur, acest viitor are provocări reale.
Acuratețea atribuirii trebuie să fie puternică. Calitatea datelor trebuie protejată. Un sistem nu ar trebui să recompenseze zgomotul doar pentru că există. Ar trebui să știe diferența dintre cunoștințele utile, conținutul repetat, contextul învechit și contribuția reală. De aceea, întreaga stivă contează. Datanet-urile îmbunătățesc inputul. RAG-ul recuperează inputul. Dovada atribuirii înregistrează influența. Fabrica de modele și OpenLora îi fac mai ușor pe constructori să creeze și să implementeze modele care pot folosi efectiv această memorie atribuită.
Ideea nu e să facem AI-ul să sune mai deștept.
Ideea este să facem AI-ul mai responsabil.
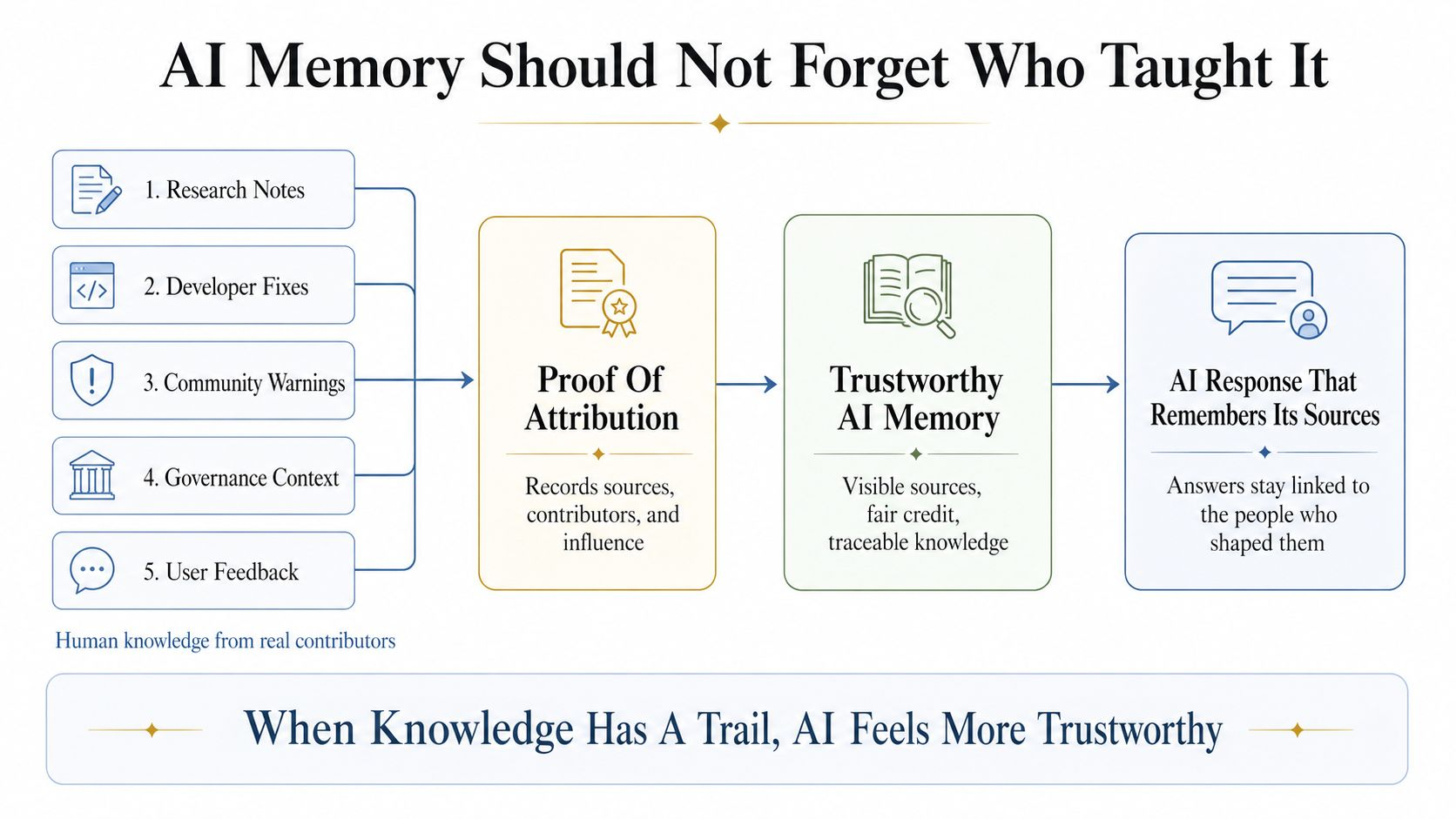
Când privesc OpenLedger prin această lentilă, nu văd RAG-ul ca pe o caracteristică de backend. Îl văd ca pe o economie a memoriei cu o conștiință. Datele, modelele și agenții sunt conectați printr-o întrebare centrală: când AI-ul folosește cunoștințele umane, poate acea cunoștință să își păstreze numele?
Dacă răspunsul este da, atunci AI devine mai puțin ca o cutie neagră și mai mult ca un registru viu al muncii împărtășite.
Și poate asta este revoluția ascunsă aici.
Dacă AI-ul va învăța de la oameni la scară, atunci persoanele din acea memorie nu ar trebui să dispară.