
Majoritatea dintre noi suntem încă obsedati de întrebarea greșită: care model este mai inteligent, mai rapid sau are mai mult capital în spate? Răsfoim prin benchmark-uri, ne contrazicem despre scorurile de raționare și aplaudăm fiecare nouă rundă de finanțare ca și cum ar fi sfârșitul jocului. Dar iată ce am realizat după ce am observat acest domeniu pentru o vreme — adevăratul război în AI nu va fi câștigat doar de modele. Se va decide prin cine deține datele, cine le verifică și, cel mai important, cine primește cu adevărat bani pentru ele.
Gândește-te la asta. În fiecare zi, oamenii hrănesc aceste sisteme cu cunoștințele lor, corecturile, expertiza lor de domeniu, feedback-ul din lumea reală. Modelele își amintesc totul. Economia? Uită oamenii aproape instantaneu. Odată ce o companie își antrenează modelul, contributorii dispar în mare parte din ecuație. Sistemul absoarbe valoarea și merge mai departe. Această dezechilibru ne privește în față de ani de zile și pare fundamental rupt — un pic ca acele jocuri timpurii de Play-to-Earn care promiteau jucătorilor adevărată proprietate și recompense, dar au ajuns să stocheze toată valoarea în vârf.
 Asta e exact motivul pentru care OpenLedger mi-a atras atenția într-un mod în care majoritatea proiectelor AI-crypto nu au făcut-o. Ei nu urmăresc doar o altă narațiune de hype în jurul modelelor mai mari. Încearcă să construiască un sistem în care datele devin muncă trasabilă și contribuitorii adună cu adevărat valoare economică în timp.
Asta e exact motivul pentru care OpenLedger mi-a atras atenția într-un mod în care majoritatea proiectelor AI-crypto nu au făcut-o. Ei nu urmăresc doar o altă narațiune de hype în jurul modelelor mai mari. Încearcă să construiască un sistem în care datele devin muncă trasabilă și contribuitorii adună cu adevărat valoare economică în timp.
Ideea lor de “Payable AI” pare simplă la suprafață, dar este destul de profundă: contribuitorii submit seturi de date de înaltă calitate în Dataneturi specifice domeniilor, dezvoltatorii folosesc acele date pentru a antrena modele specializate, iar contractele inteligente distribuie automat recompense $OPEN bazate pe contribuția reală. Fără extracție invizibilă. Datele au proveniență, influența poate fi măsurată, iar economia se întoarce la oamenii care au creat valoarea.
Ce mă face să remarc asta este motorul Proof of Attribution pe care l-au lansat. Partea bazată pe gradient pentru modelele mai mici are sens — dacă eliminarea unui punct de date afectează clar performanța, acea dată avea o valoare măsurabilă. Dar partea mai ambițioasă este atribuirea token-urilor prin sufix-array pentru modelele de limbaj mai mari. Să urmărești exact care părți ale corpului de antrenament au influențat token-urile de ieșire specifice a fost întotdeauna extrem de dificil. Ieșirile par colective și neclare. Să încerci să faci asta transparent este o problemă tehnică cu adevărat greu de rezolvat, și nu pretind că este perfect — dar cel puțin încearcă să construiască responsabilitate în loc să optimizeze doar pentru extracție.
Partea legală este o altă piesă care pare să fie înaintea curvei. Parteneriatul lor cu Story Protocol este inteligent pentru că, pe măsură ce AI avansează în utilizarea comercială — în special în medicină, finanțe, drept sau orice domeniu reglementat — întreprinderile nu vor întreba doar „cât de bun este acest model?” Vor dori să știe: Este acest set de date verificat? Licențiat? Legal curat? Apărat? A avea atribuirea pe blockchain plus o licențiere IP corectă ar putea deveni un avantaj competitiv masiv.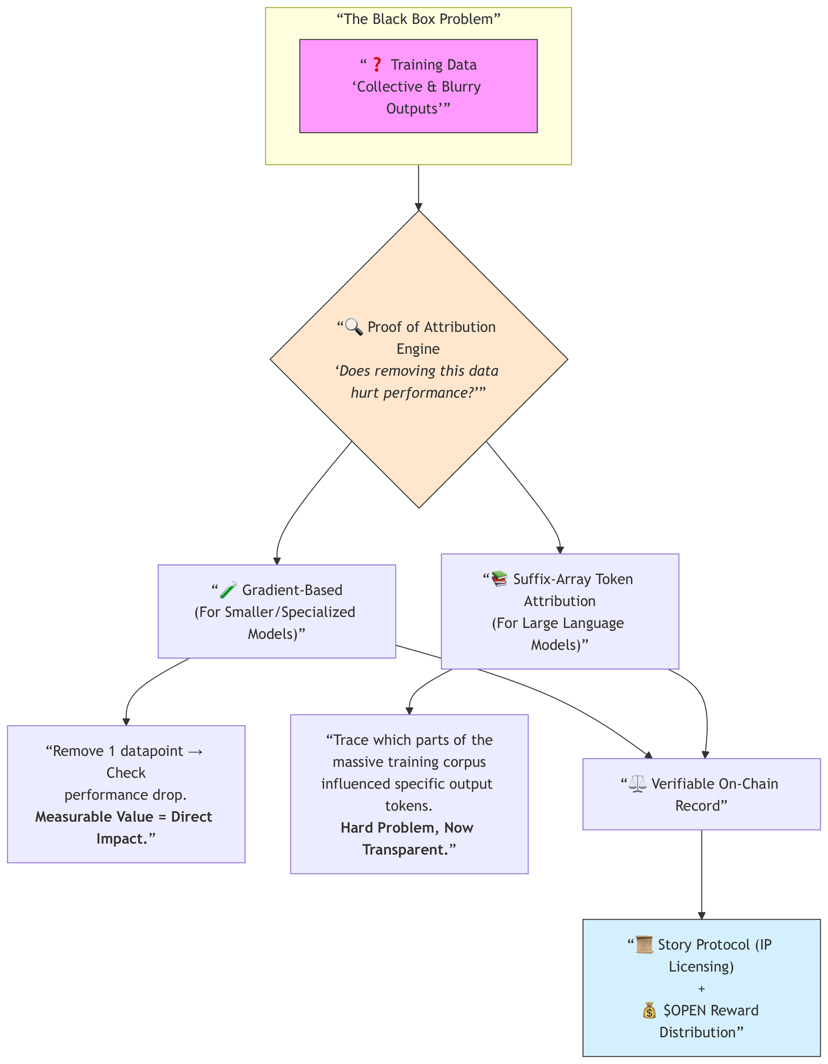
Și cifrele din faza lor de testnet chiar îi conferă o greutate: peste 6 milioane de noduri înregistrate, 25 milioane+ de tranzacții și 20,000 de modele AI construite înainte ca mainnet-ul să fie activat la sfârșitul anului trecut. Asta nu este doar hype de hârtie — arată o participare reală și testare la scară. Acum că mainnet-ul este operațional cu peste 40 de proiecte deja construite pe el, testul real începe.
Pentru că să fim cinstiți — acolo unde curg banii reali, comportamentul prost urmează. Vom vedea jocuri pe leaderboard, spam de date sintetice de slabă calitate, dispute de atribuire și oameni care încearcă să optimizeze pentru recompense în loc de calitate. Stratificarea de validare și alinierea stimulentelor pe termen lung vor decide dacă asta funcționează cu adevărat la scară sau devine doar un alt experiment interesant.
Totuși, respect că OpenLedger abordează întrebarea incomodă pe care majoritatea din industrie a evitat-o: Dacă oamenii obișnuiți ajută la crearea valorii în aceste sisteme AI… își va aminti sistemul de ei?
Asta pare să fie întrebarea corectă de pus în 2026. Războaiele modelelor vor continua, dar proiectele care își dau seama de proprietatea și atribuirea datelor corecte și transparente ar putea avea avantajul cel mai durabil — atât tehnic, cât și economic.
Ce părere ai — va fi proprietatea datelor adevărata fortăreață în AI, sau suntem încă la ani distanță de sisteme care recompensează cu adevărat contribuitorii corect? Sunt cu adevărat curios unde va ajunge asta pe termen lung.
