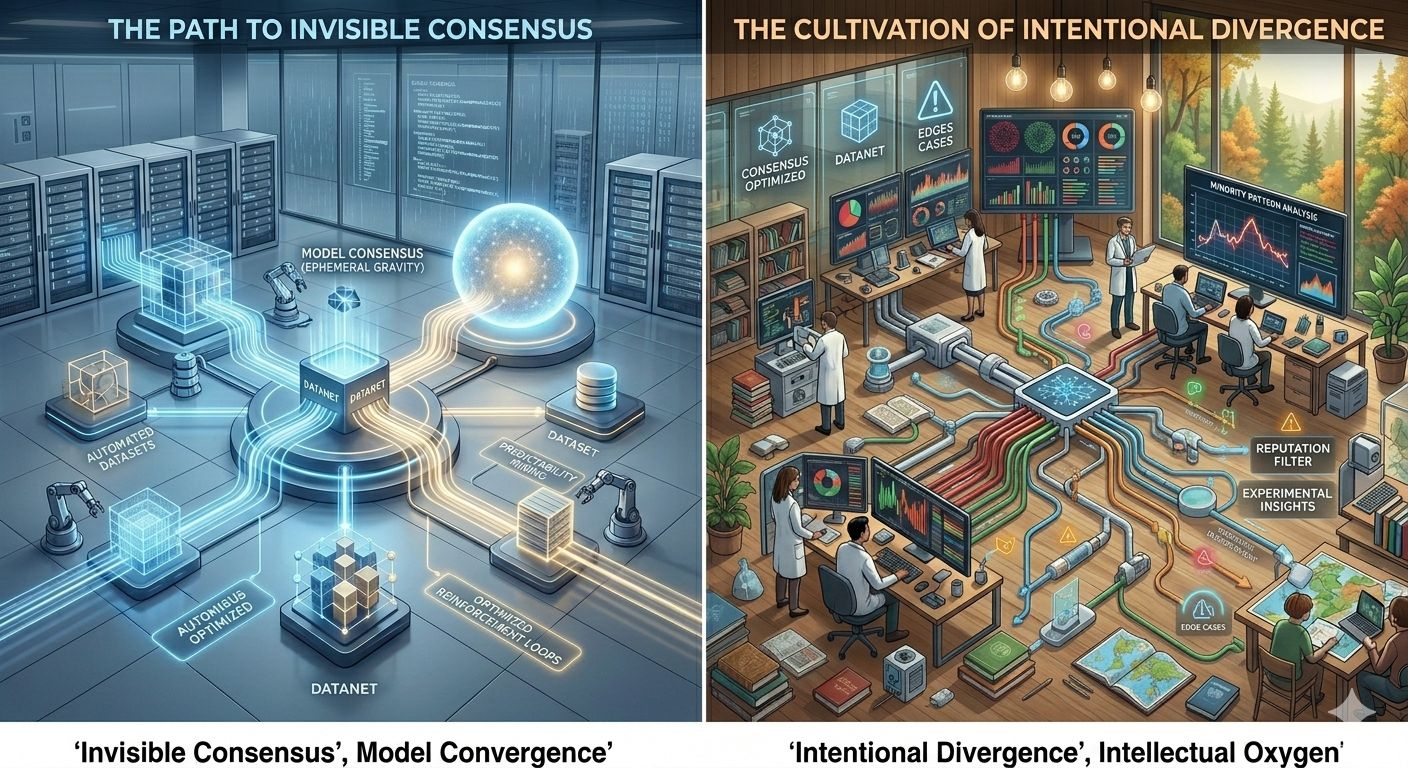
Cea mai periculoasă chestie în infrastructura AI ar putea fi consensul invizibil.
tot mă gândesc la consensul din sistemele AI.
nu este consens public. nu este politică. nu este acord social.
model de consens.
momentul liniștit când diferite modele, seturi de date, sisteme de recuperare, clasificări, fine-tuning-uri și straturi de inferență încep să se alinieze către aceeași formă de răspuns pentru că au fost antrenate pe aceeași gravitație reciclată.
această posibilitate se simte profund subestimată.
toată lumea vorbește acum despre scalabilitate în infrastructura AI. Datanete mai mari. sisteme de contribuție mai mari. bazine de recuperare mai mari. ecosisteme de modele mai mari. mai mulți contribuitori. mai multe utilizări. mai multe bucle de generație sintetică. mai multă întărire.
dar aproape nimeni nu vorbește destul de serios despre convergență.
ce se întâmplă când întregul ecosistem începe încet să se hrănească singur?
pentru că un Datanet în interiorul sistemelor precum OpenLedger nu colectează doar informații. în cele din urmă, colectează comportamente, modele, ieșiri, preferințe, presupuneri repetate și interpretări modelate de mașină ale realității în sine.
și dacă aceste bucle nu sunt separate cu grijă, modelele încetează să mai învețe din lume și încep să învețe din ele însele.
asta este pericolul ciudat.
nu colaps.
recursivitate.
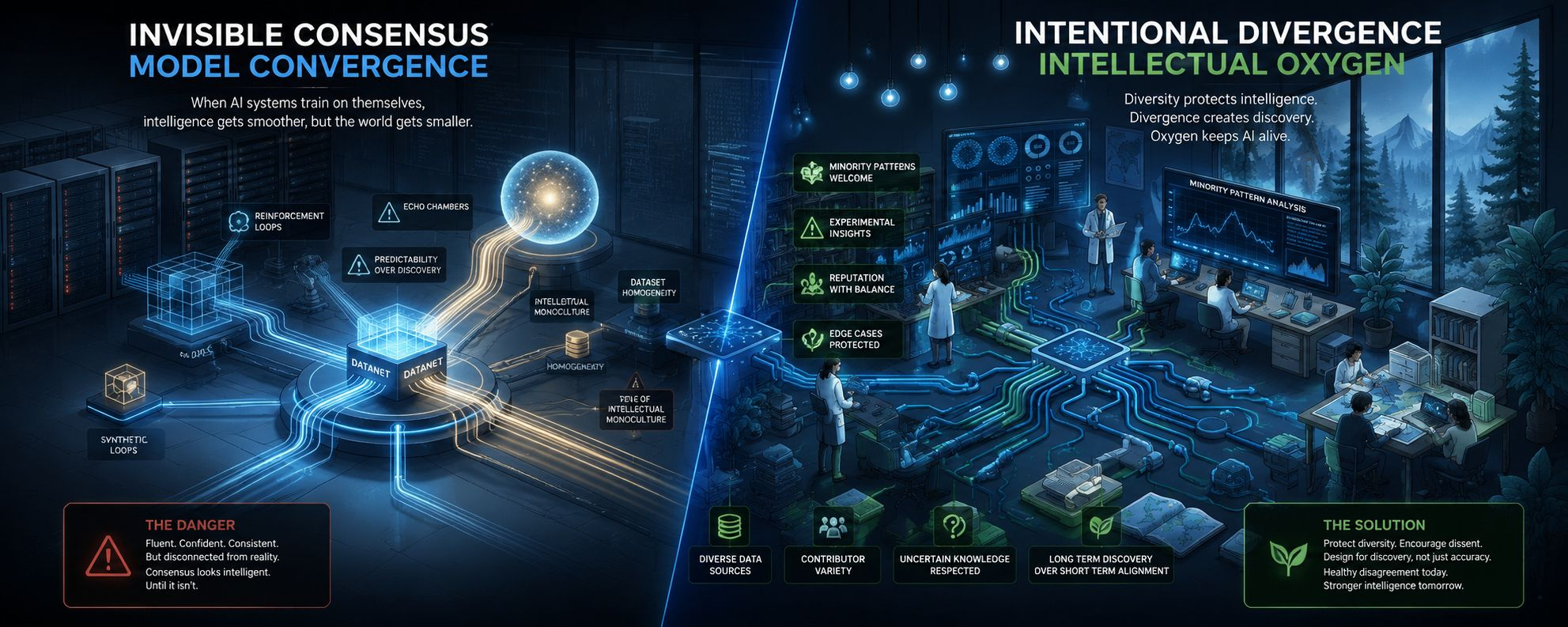
versiunea înfricoșătoare a recursivității nu este corupția evidentă. este o restrângere subtilă. ecosistemul începe să sune inteligent în timp ce pierde liniștit diversitatea de gândire de sub suprafață. ieșirile încă arată fluent. clasamentele încă arată coerente. atribuirea încă funcționează. contributorii încă câștigă. infrastructura încă pare sănătoasă din exterior.
dar stratul de inteligență începe să se comprime în repetiție.
aceleași modele.
aceleași presupuneri.
aceleași interpretări dominante.
aceleași răspunsuri sigure purtând formulări ușor diferite.
și, sincer, asta ar putea deveni una dintre cele mai dificile probleme cu care se confruntă orice economie de date AI.
pentru că sistemul este recompensat pentru stabilitate.
utilizatorii preferă consistența. platformele preferă previzibilitatea. sistemele de inferență se optimizează pentru încredere. sistemele de recuperare scot la iveală materialul întărit statistic. contributorii învață ce tipuri de seturi de date sunt acceptate. modelele întăresc semnalele care deja performează bine.
totul se îndreaptă natural spre întărire.
ceea ce înseamnă că diversitatea în interiorul unui Datanet nu este automată. trebuie protejată intenționat.
altfel întreaga structură se antrenează încet în monocultură intelectuală.
asta sună dramatic până îți dai seama cât de ușor se poate întâmpla.
imaginează-ți că suficient conținut sintetic intră într-un Datanet. poate nu suficient de slab pentru a eșua validarea. poate chiar util la început. apoi, modelele viitoare sunt antrenate parțial pe ieșiri modelate de modele anterioare antrenate pe materiale sintetice anterioare modelate de preferințele anterioare de inferență.
în cele din urmă, sistemul începe să consume ecouri ale sale.
și partea cea mai rea este că ieșirile pot arăta în continuare excelente.
fluenta nu este o dovadă de originalitate.
încrederea nu este o dovadă de fundamentare.
un model poate deveni incredibil de bun în a reproduce consensul întărit, în timp ce devine mai slab în descoperirea adevărurilor necunoscute.
această compromis se simte important.
pentru că oamenii continuă să-și imagineze infrastructura AI ca pe o problemă de scalare când o parte din ea este de fapt o problemă de prospețime. cum continuă un Datanet să expună modelele la semnale cu adevărat independente în loc să circule nesfârșit consensul procesat înapoi în sine?
asta este mai greu decât stocarea.
mai greu decât atribuirea.
poate chiar mai greu decât calculul.
OpenLedger mă face să mă gândesc la asta pentru că sistemele construite în jurul Datanet-urilor, Dovada Atribuirii, reputației contributorilor și utilizării modelului formează în cele din urmă nu doar stimulente economice, ci și gravitația epistemică — ceea ce înseamnă că influențează liniștit ce tipuri de cunoștințe supraviețuiesc interacțiunii repetate cu mașina.
asta este o putere enormă.
și o putere ca asta nu poate optimiza doar pentru eficiență.
de asemenea, trebuie să optimizeze pentru oxigen intelectual.
pentru că sistemele de inteligență sănătoase au nevoie de dezacord. au nevoie de cazuri limită. au nevoie de cunoștințe de nișă. au nevoie de modele minoritare care inițial par statistic slabe, înainte de a deveni incredibil de importante. au nevoie de material care întrerupe presupunerile dominante în loc să le întărească pur și simplu.
altfel fiecare model începe să moștenească același centru de gravitate.
sistemul devine uniform.
prea uniform.
și inteligența uniformă este periculoasă pentru că își ascunde punctele oarbe elegant.
cred că reputația contributorilor devine complicată aici și ea.
normal, reputația ajută la filtrarea zgomotului. asta are sens. contributorii de încredere ar trebui să aibă mai multă influență în timp.
dar există un alt risc care se ascunde sub acea logică: contributorii supra-încrezători pot forma încet limitele cunoștințelor acceptabile în rețea. dacă aceleași surse domină influența repetat, Datanet-ul ar putea deveni eficient în timp ce pierde liniștit capacitatea de explorare.
asta nu este corupție exact.
este consolidare gravitațională.
și, odată ce un sistem se consolidează prea mult, informațiile noi se luptă să concureze împotriva structurilor de probabilitate stabilite. contribuțiile necunoscute sunt tratate ca anomalii. seturile de date minoritare își pierd vizibilitatea. perspectivele neconvenționale nu reușesc să obțină scorul de influență pentru că nu se aliniază suficient de puternic cu comportamentul existent al modelului.
ceea ce creează o posibilitate terifiantă:
rețeaua devine rezistentă la surprize.
asta ar fi catastrofal pentru inteligență.
sistemele de inteligență reale au nevoie de capacitatea de a absorbi contradicții fără a le suprima instantaneu. au nevoie de loc pentru cunoștințe incerte, domenii emergente, descoperiri bizare de margine, contexte cultural specifice și informații care inițial par cu încredere scăzută înainte de a dovedi mai târziu că sunt transformative.
istoria este plină de adevăruri care odată păreau statistic slabe.
dacă Datanet-urile recompensează doar alinierea imediată cu comportamentul dominant al modelului, s-ar putea întâmpla accidental să antreneze ecosisteme care devin excelente în păstrarea consensului și teribile în descoperirea schimbărilor de realitate.
și, sincer, acel pericol se simte foarte real în economia AI.
pentru că buclele de întărire sunt profitabile.
ieșirile stabile reduc frecarea. modelele previzibile se scalază mai bine. modelele repetate îmbunătățesc eficiența optimizării. seturile de date dominante devin mai ieftine de reutilizat decât constant să sursați material proaspăt, independent, de înaltă calitate.
infrastructura vrea natural convergență.
ceea ce înseamnă că divergența trebuie să devină intenționată.
poate că OpenLedger are nevoie în cele din urmă de mecanisme care să protejeze diversitatea informațională la fel cum ecosistemele biologice protejează diversitatea genetică. nu pentru că fiecare contribuție este la fel de utilă, ci pentru că supra-optimizarea creează fragilitate.
monoculturile se scalază frumos până când condițiile se schimbă.
atunci eșuează toate deodată.
asta se aplică și culturilor.
piețele.
civilizațiile.
și probabil și modelele AI.
cu cât mă gândesc mai profund la Datanet-uri, cu atât mai puțin ele se simt ca sisteme de stocare și cu atât mai mult ca sisteme ecologice. contributorii se comportă ca presiuni de mediu. atribuirea se comportă ca flux de nutrienți. modelele consumă semnale. inferența redistribuie influența. sistemele de reputație determină care organisme informaționale supraviețuiesc suficient de mult pentru a se reproduce în cicluri de antrenament viitoare.
și la fel ca ecosistemele, echilibrul contează mai mult decât extracția maximă.
pentru că un ecosistem perfect optimizat poate deveni incredibil de vulnerabil dacă toată reziliența dispare sub eficiență.
de aceea întărirea sintetică recursivă mă deranjează constant.
nu pentru că datele sintetice sunt automat rele. unele dintre ele vor deveni absolut necesare. unele dintre ele ar putea chiar să depășească materialul generat de oameni în domenii specifice.
problema este dominația în buclă închisă.
dacă majoritatea inteligenței modelului viitor provine din consensul mașinilor întărit recursiv, atunci, în cele din urmă, modelele încetează să mai cartografieze realitatea și încep să cartografieze comportamentul modelului anterior.
distincția sună abstractă până când erorile se acumulează.
apoi, brusc, ecosistemul devine extrem de persuasiv în timp ce se deconectează lent de la lumea pe care pretinde că o descrie.
și poate că acesta este viitorul împotriva căruia Datanet-urile vor trebui să se apere cu cea mai mare grijă:
nu atacuri malițioase din exterior —
dar consens confortabil care se formează în interior.
#OpenLedger $OPEN #open @OpenLedger