
I’ve watched the same scene play out in more teams than I can count. Someone shares a document in a hurry. Then it gets copied into a new folder, forwarded in an email, pasted into a chat, exported into a dashboard, renamed twice, and—without anyone intending to—its meaning quietly starts dissolving. Two weeks later a decision is being defended with a screenshot and a half-remembered sentence. Three months later, when somebody asks why that decision happened, you’re not looking for the file anymore. You’re looking for the chain of context that used to live around it: who approved it, what assumptions were true at the time, which version was “final,” what got changed in conversation, what got ignored, what got misunderstood. The system technically worked. The reasoning is what vanished.
That’s the exact kind of practical headache Vanar’s Neutron + Kayon + Axon direction is trying to aim at in 2026. Not by being loud. Not by trying to sell a “futuristic vibe.” But by treating meaning like something a network can carry—structured memory, traceable reasoning, and restrained execution—so you can walk backward from “what happened” to “why it happened” to “what evidence it used,” without the whole thing collapsing into “just trust the server.”
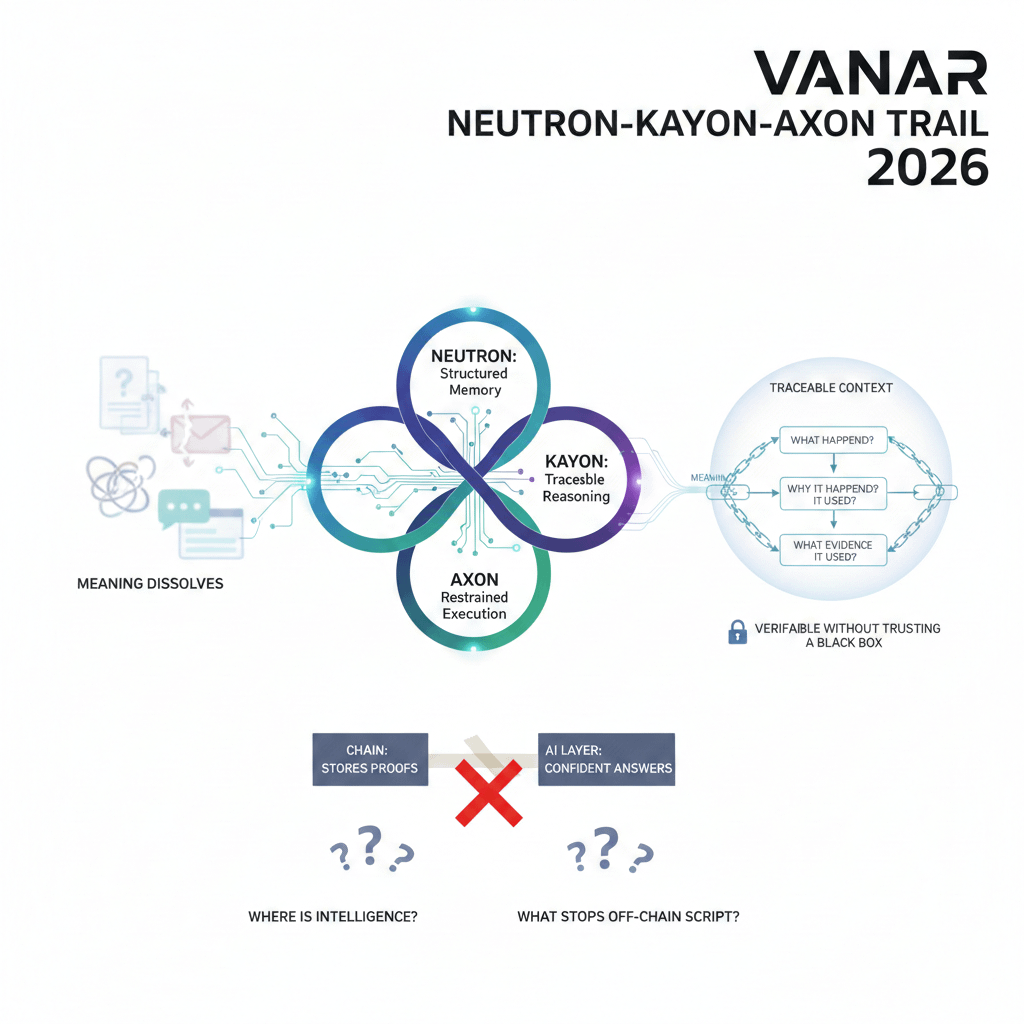
Because if we’re honest, most “AI stacks” in crypto still look like two things taped together: a chain that can store proofs, and an AI layer sitting off to the side producing confident answers. It feels clean in a diagram. Then it wobbles the moment you ask three basic questions: where does the intelligence actually live, what part of it can you verify without trusting a box you don’t control, and when it’s time to act, what stops it from turning into an off-chain script with a fancy label?
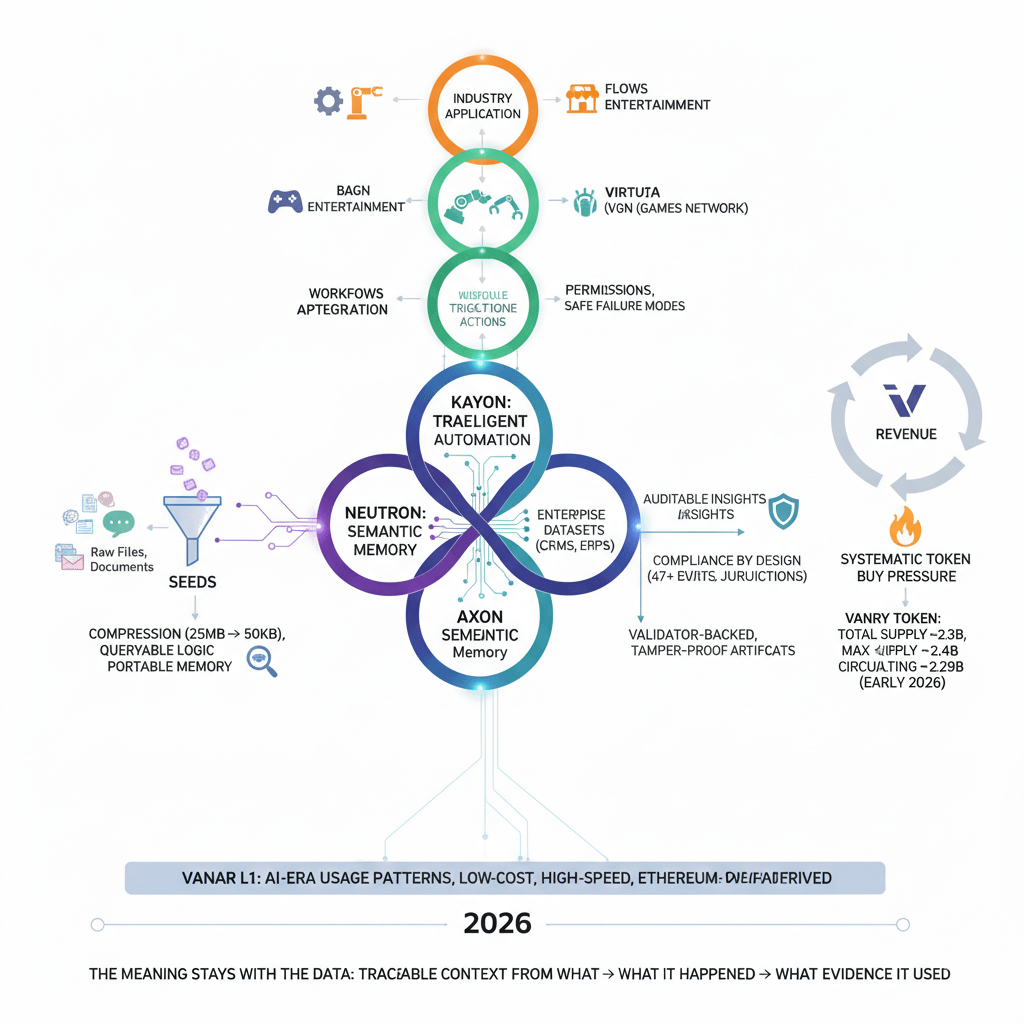
Vanar is framing the stack as five layers that climb in a very specific order: the base chain, then Neutron (semantic memory), then Kayon (reasoning), then Axon (intelligent automation), and finally “Flows” as the industry applications that sit on top. That ordering is quietly important. It’s basically a promise that you don’t start with the agent and hope you can bolt trust onto it later. You start with durable memory, then you allow reasoning to happen against that memory, then—only then—you let execution touch the world.
Underneath it, Vanar positions its L1 as something designed around AI-era usage patterns rather than just being another generic ledger. The messaging is that it’s built “for AI workloads from day one,” with protocol-level support aimed at making semantic operations and AI-shaped validation feel native instead of forced. It’s also presented in a way that feels intentionally familiar to builders—an environment derived from Ethereum so existing tools and habits aren’t thrown away—and marketed as low-cost and high-speed, with a stated fixed transaction price point in the developer material.
That’s the infrastructure story. But the first place the “meaning” story becomes tangible is Neutron.
Neutron isn’t framed as ordinary storage, and that’s where it immediately separates itself from the usual “we put files on-chain” pitch. The idea is to take raw files, chats, and documents and transform them into compact, structured outputs called Seeds—small enough to store on-chain, searchable, and usable as inputs for logic. That’s a different intention than the classic “hash plus pointer” approach. A hash can prove a file didn’t change. But a hash can’t answer questions. It can’t surface what matters. It can’t power automation. It can’t help you reason. It’s integrity without usability.
The core claim around Seeds is that the content is made smaller and stays useful. There’s a concrete compression example used in the Neutron narrative: compressing roughly 25MB down to about 50KB by combining multiple semantic, heuristic, and algorithmic layers. The size drop is impressive on its own, but the real point is what that smaller object becomes: something queryable and executable, something that can sit inside workflows, contracts, and agent logic without dragging the entire original file everywhere.
Neutron also leans into “queryable data” as a first-class behavior—ask a PDF questions, extract insights, index and retrieve like a language model would—while still keeping the object anchored to a verifiable trail. And it goes one step further with “executable file logic,” implying those Seeds can become triggers that activate apps, contracts, or agents.
Then comes the line that forces the serious engineering conversation: the claim that an AI component isn’t just a front-end feature, but is embedded directly into validator nodes for on-chain AI execution. That’s not a casual statement. AI outputs are probabilistic by nature, and consensus systems don’t tolerate “close enough.” So if intelligence actually lives in the validator environment, it has to be constrained into something that consensus can survive—either deterministic checks, tightly scoped inference roles, or a design where the AI produces receipts that can be verified without destabilizing finality. Any one of those paths is harder than “we integrated a model,” but it’s also exactly what would separate a toy stack from a serious one.
There’s also a user-facing wedge in the Neutron vision that matters more than it looks: the idea of portable memory. The framing is that context dies when you switch between AI tools and work surfaces—one chat can’t remember what you said in another, one workflow can’t see what you already decided elsewhere—and that a memory layer can persist across those platforms. That portability is where Neutron tries to become something people use daily, not just something developers talk about.
And in early 2026, you can see why this angle matters. The agent frameworks that got popular made “memory” the quiet weak point. Default memory is usually just files in a workspace, and the agent “remembers” only what gets written and retrieved. It’s simple. It also breaks the moment agents restart, migrate, operate across channels, or get deployed in environments where security boundaries matter. The more disposable the agent instance becomes, the more valuable durable memory becomes. Neutron’s bet is to make that memory survive the instance—long-term semantic memory, cross-channel retrieval, persistent context that grows with every interaction.
But memory alone still doesn’t fix the problem, because a perfect record can remain useless if people can’t trust how it’s interpreted. That’s where Kayon comes in—and honestly, this is the part that decides whether the approach carries weight in 2026.
Kayon is positioned as contextual reasoning that sits on top of Neutron Seeds and enterprise datasets, producing auditable insights, predictions, and workflows—not just chat answers. One design choice that stands out is the connectivity posture: it leans on MCP-based APIs and direct integration into real systems—explorers, dashboards, ERPs, CRMs, and custom backends—so organizations don’t have to rebuild everything on-chain just to participate. That’s how you survive real-world adoption. Most teams won’t remodel their entire data universe for “crypto AI.” They’ll plug in what they have, test outcomes, and only then expand.
Kayon also carries a heavy compliance claim: “compliance by design,” including monitoring rules across 47+ jurisdictions, automating reporting, and enforcing compliance natively. If that’s real, it’s not a marketing sticker. It’s an operational burden: rule changes, versioning, explainability, and evidence trails that can hold up under disputes. But if it’s executed properly—if reasoning artifacts are anchored back to the Seeds and inputs that produced them—then you get something most compliance tooling struggles with: not just a result, but a defensible “why” tied to provenance.
This is where the phrase “validator-backed” and “tamper-proof” becomes meaningful. In practice, it’s a claim that the reasoning output can’t be quietly rewritten later when outcomes become inconvenient. It implies you can treat the “reason” as an artifact, not just a transient answer. And once you treat reasoning as an artifact, the conversation changes. The question stops being “can it answer?” and becomes “can it be held accountable to its inputs?”
Then comes Axon—the layer that decides whether the entire stack becomes real, or stays a beautiful theory.
Because insight without execution is still just analysis. Reasoning that stays trapped in a chat box doesn’t change the world. Axon is positioned as the intelligent automation layer that turns Neutron’s memory and Kayon’s reasoning into workflows that actually do things: trigger actions, run sequences, orchestrate processes. It’s currently framed as “coming soon,” which is the honest place to be, because automation is where systems get dangerous if they’re not designed with restraint.
“Agentic execution” sounds fine until you remember what real-world actions require: permissions, allowlists, approvals for sensitive steps, deterministic logs, clear retry behavior, safe failure modes, and—most importantly—a way to prove why the action happened. If Axon can’t bind every action back to a reasoning artifact and the Seeds that reasoning relied on, you’re right back to the old world. Automation that works until it doesn’t, and then nobody can explain what went wrong.
Now, none of this exists in a vacuum. Vanar’s broader positioning is still rooted in consumer adoption—gaming, entertainment, and brand integrations as a path to the next 3 billion users. That matters because those verticals generate endless messy data: identity signals, asset histories, community actions, economic behaviors, content provenance. It’s exactly the kind of data that becomes useless the moment context is lost. If you can turn that mess into Seeds and reason over it without trusting a single company’s database as the unquestioned source of truth, you’re not just adding AI to entertainment. You’re building a system that can preserve meaning as user activity scales.
Two ecosystem pillars repeatedly associated with that consumer-facing surface are Virtua (a metaverse direction) and VGN (a games network direction), with the broader stack powered by the VANRY token.
On the token side, there are a few things that are straightforward and verifiable, and I’ll keep them explicit because clarity matters here. The token uses 18 decimals. And the commonly reported supply picture around early 2026 is roughly shaped like this: total supply around ~2.3B, max supply around ~2.4B, circulating supply around ~2.29B (these figures can drift slightly depending on timing and indexing, but the overall structure remains consistent).
The deeper 2026 question isn’t the exact number though. It’s whether usage routes back into token demand in a way that doesn’t depend on hype. And that’s where the revenue-to-token capture narrative becomes relevant: the attempt to tie paid product usage—especially subscription-style access to AI-native tools—into systematic buy pressure and potential supply reduction via buybacks and burns. Structurally, the idea is simple: if products generate revenue and that revenue reliably converts into market buys (and possibly burns), you reduce the common problem where the product succeeds but the token remains decorative.
That loops back to why the “portable memory” angle matters so much. If Neutron becomes a daily driver—memory that persists across AI platforms, that can be queried and used as input for workflows—then usage becomes repeatable. It becomes a stream, not a spike. And repeatable usage is what stress-tests architecture, proves demand, and forces the discipline that a real network needs.
So when I say this Neutron + Kayon + Axon direction feels worth paying attention to in 2026, I don’t mean it in a “new narrative” way. I mean it in a painfully practical way: most teams are already drowning in data that loses meaning the moment it moves. Most organizations already suffer from decisions that can’t be explained later because the reasoning evaporated into chat history and human memory. A system that can preserve meaning as a first-class object—Seeds for memory, auditable artifacts for reasoning, and guarded rails for execution—would solve something that isn’t theoretical at all.
And maybe that’s the real point. Not whether the diagrams look clean. Not whether the buzzwords land. But whether, months after a decision, you can open the trail and see the story of it—what was known, what was assumed, what was used, what was ignored, and why the system chose to act.
Because if Vanar gets that right, it won’t feel like “AI on a chain.” It’ll feel like the first time the meaning stayed with the data… even after everything moved.
