na początku nie traktowałem tego poważnie...
nie dlatego, że OpenLedger brzmiał pustawo. bardziej dlatego, że widziałem zbyt wiele pomysłów infrastrukturalnych wchodzących w krypto z ostrożnym językiem, które powoli stają się kolejną maszyną motywacyjną, której nikt do końca nie rozumie po pierwszej fali wiary.
tak to zazwyczaj wygląda.
pojawia się prawdziwy problem. wszyscy się zgadzają, że to ma znaczenie. system jest zaprojektowany wokół sprawiedliwości, koordynacji, przejrzystości, własności. potem przychodzą pieniądze, pojawia się użycie, przychodzą skróty, a system zaczyna zachowywać się mniej jak idea, a bardziej jak rynek pod presją.
Może to zbyt surowe.
ale po wystarczającej liczbie cykli, zaczynasz mniej dbać o to, co infrastruktura twierdzi, że naprawia, a bardziej o to, czego przypadkowo uczy ludzi. co nagradza. co ignoruje. co czyni zrozumiałym. co pcha w cienie, ponieważ warstwa pomiarowa nie może poradzić sobie z chaosem.
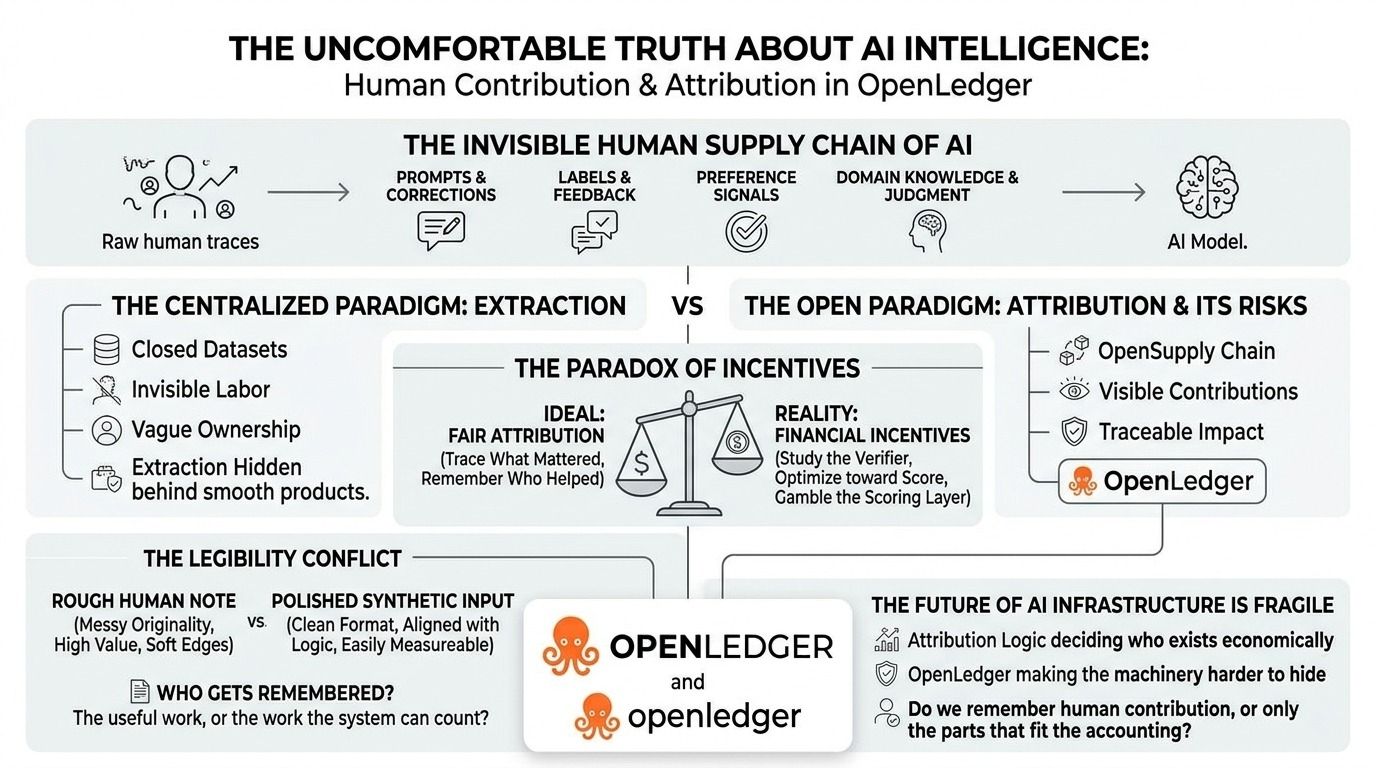
Dane AI są niewygodne z dokładnie tego powodu.
modele nie są budowane z jakiejś czystej, unoszącej się inteligencji. są kształtowane przez ludzkie ślady wszędzie. podpowiedzi, poprawki, etykiety, opinie, przykłady, sygnały preferencji, wiedza dziedzinowa, małe kawałki osądu. większość z tego wydaje się drobna, gdy to się dzieje. prawie jednorazowa.
potem model się poprawia.
potem wszyscy nazywają to zdolnością.
a ludzka część znika w 'danych'.
Ciągle wracam do przypisania.
jest tam coś niezbędnego. jeśli inteligencja ma łańcuch dostaw, może ten łańcuch dostaw nie powinien pozostać ukryty wewnątrz zamkniętych systemów. może ludzie nie powinni znikać w momencie, gdy ich wkład staje się wartościowy. może OpenLedger ma znaczenie, ponieważ stara się sprawić, by wkład było trudniej wymazać.
nie idealnie.
nie w sposób czysty.
ale na tyle widocznie, by uczynić to pytanie trudniejszym do uniknięcia.
i to jest miejsce, gdzie zaczyna się moja ciekawość.
potem niewygoda wraca.
ponieważ przypisanie zmienia się, gdy staje się finansowe. przed zachętami brzmi to sprawiedliwie. pamiętaj, kto pomógł. śledź, co było istotne. spraw, aby wkład był widoczny. po zachętach cała tekstura się zmienia. ludzie badają, co się liczy. uczą się, co to jest weryfikator. produkują w kierunku warstwy oceny. użyteczna praca i mierzalna praca zaczynają się oddalać, a system musi nadal twierdzić, że zna różnicę.
Działa w teorii. Większość rzeczy działa.
Problem nie tkwi naprawdę w technologii… ani tylko w technologii. problem polega na tym, że ludzki wkład jest miękki na brzegach. kontekst jest miękki. oryginalność jest miękka. użyteczność może pojawić się późno, po tym jak model się zmieni, po tym jak inne wkłady go otoczą, po tym jak nikt nie pamięta, która mała poprawka zrobiła różnicę.
szorstka ludzka nuta może mieć większe znaczenie niż wypolerowany zestaw danych.
syntetyczny wkład może wyglądać czyściej niż rzeczywisty osąd.
skopiowana praca może lepiej pasować do logiki przypisania niż chaotyczny oryginał.
więc kto zostaje zapamiętany?
osoba, która pomogła, czy osoba, którą system mógł rozpoznać?
Ta część ciągle mnie niepokoi bardziej niż powinna.
a potem jest starszy dryf Web3. otwarte systemy rzadko centralizują się ponownie w jednym dramatycznym momencie. zwężają się przez wygodę. zmęczenie. pulpity. indeksy. oceny jakości. operatorzy. warstwy sporu. cała niewidoczna infrastruktura, której nikt nie chce audytować wiecznie.
Infrastruktura AI wydaje się tam szczególnie krucha, ponieważ niewidoczne warstwy nie są drugorzędne. logika przypisania, ocena wkładu, filtrowanie, koordynacja modeli — te warstwy decydują, co się liczy. a kiedy zdecydują, co się liczy, decydują, kto istnieje ekonomicznie.
jednak nie mogę odrzucić OpenLedger.
centralizowane AI również nie zasłużyło na to komfortowe poczucie. zamknięte zestawy danych, niejasne własności, niewidoczna praca, wydobycie ukryte za gładkimi produktami. ta wersja już wydaje się zepsuta, po prostu łatwiejsza do zniesienia, ponieważ maszyny pozostają prywatne.
może OpenLedger sprawia, że maszyny trudniej ukryć.
może to ma znaczenie.
albo może, gdy zachęty będą wystarczająco ostre, system stworzony do zapamiętywania ludzkiego wkładu zacznie pamiętać tylko te części, które ładnie pasują do jego księgowości, podczas gdy reszta wróci do modelu, użyteczna i nieznana.
[6/3, 12:22 AM] A M S: **AGENT AI BEZ ŚLADU DOKUMENTACJI TO TYLKO BARDZO PEWNY NIEZNAJOMY**
byłem na jednej z tych późnonocnych dyskusji o kryptowalutach, gdzie wszyscy znów kłócili się o agentów AI.
nie czy działają.
ta część prawie wydaje się oczywista teraz. agenci mogą badać, podsumowywać, handlować, kierować, planować, odpowiadać i udawać, że rozumieją kontekst na tyle dobrze, że większość ludzi przestaje zadawać głębsze pytania.
rozmowa dotyczyła głównie prędkości.
szybsze agenty. lepsze modele. płynniejsza automatyzacja. mniej tarcia.
ale po pewnym czasie wciąż myślałem o czymś bardziej podstawowym.
przypomniało mi to obserwowanie tradera wchodzącego do pokoju, dokonującego idealnej transakcji i odmawiającego wyjaśnienia, skąd wzięła się ta idea. żadnego źródła, żadnych notatek, żadnych śladów, żadnych limitów ryzyka. po prostu pewność.
a ludzie z branży kryptowalut, z wszystkich ludzi, powinni wiedzieć lepiej, niż ufać pewności bez weryfikacji.
prawdziwe pytanie nie brzmi, czy AI jest inteligentne. chodzi o to, czy AI jest odpowiedzialne.
skąd pochodzi inteligencja?
kto przyczynił się do danych?
kto to oczyścił, oznaczył, zweryfikował, poprawił?
kto dał agentowi pozwolenie na działanie?
kto dostaje wynagrodzenie, gdy ta inteligencja staje się wartościowa?
bez przypisania inteligencja staje się anonimową pracą.
to jest soczewka, przez którą OpenLedger zaczyna być warte zbadania. nie dlatego, że jest doskonałe. nie sądzę, by jakikolwiek projekt AI w kryptowalutach mógł teraz nosić tę etykietę. większość tej przestrzeni jest nadal eksperymentalna, z dużą ilością zachęt i bardzo łatwa do zniekształcenia przez nagrody w tokenach.
ale OpenLedger wydaje się patrzeć na brakującą księgę za inteligencją.
Dowód przypisania, własność danych, zachęty dla współpracowników, datanety, wyspecjalizowane modele AI, weryfikowalna inteligencja, dystrybucja wartości AI — te pomysły nie są tak efektowne jak demonstracja agenta. nie sprawiają, że ludzie od razu się ekscytują tak, jak robi to bot handlowy czy autonomiczny asystent.
ale mogą mieć większe znaczenie.
ponieważ model AI bez pochodzenia to czarna skrzynka z pewnym tonem.
OpenAI i tradycyjne platformy AI są silne w skali, polerowaniu, dystrybucji i wydajności modelu. uczyniły AI użytecznym dla zwykłych ludzi. to jest prawdziwe wykonanie. ale łańcuch dostaw pozostaje głównie zamknięty. użytkownicy widzą wynik, a nie ślad własności. współpracownicy rzadko wiedzą, jak ich dane ukształtowały system lub czy zasługują na coś z wartości stworzonej.
Fetch.ai koncentruje się bardziej na autonomicznych agentach i koordynacji maszynowej. ta warstwa jest ważna, jeśli agenci mają działać na różnych rynkach, usługach i urządzeniach. ale autonomiczność agenta stwarza inny problem: uprawnienia. co agent może właściwie zrobić? co kształtowało jego decyzję? kto audytuje go, gdy działa niepoprawnie?
Protokół Virtuals jest interesujący z perspektywy gospodarki agentów. rozumie, że agenci mogą stać się społecznymi, finansowymi i wspólnotowymi aktywami. ale uczynienie agenta widocznym nie jest tym samym, co uczynienie jego inteligencji śledzonej. postać może mieć token, ale skąd wzięła się jej wiedza?
Bittensor prawdopodobnie znajduje się bliżej głębszej debaty infrastrukturalnej. tworzy rynki wokół inteligencji maszynowej i nagradza użyteczne wyniki. ale OpenLedger wydaje się bardziej skoncentrowane na warstwie poniżej: sieciach danych, ścieżkach przypisania, logice własności i nagrodach dla współpracowników, które istnieją zanim inteligencja stanie się ostateczną odpowiedzią.
to rozróżnienie ma znaczenie.
branża ciągle optymalizuje inteligencję, zaniedbując odpowiedzialność.
OpenLedger wydaje się mniej zainteresowane tym, by AI było głośniejsze, a bardziej tym, by AI było śledzone.
jednak wciąż jestem sceptyczny.
przypisanie na dużą skalę jest trudne. jakość danych może się załamać, jeśli zachęty są źle zaprojektowane. nagrody dla współpracowników mogą stać się grami farmingowymi. datanety potrzebują rzeczywistego popytu, a nie tylko emisji. wyspecjalizowane modele AI potrzebują rzeczywistych użytkowników. zarządzanie może dryfować. a 'transparentna gospodarka AI' to tylko fraza, chyba że przezroczystość zmienia to, kto dostaje wynagrodzenie.
więc nie, nie mówię, że OpenLedger wygrywa.
mówię, że pytanie, na które wskazuje, wydaje się większe niż jeden projekt.
może następna główna warstwa infrastruktury AI nie jest najsprytniejszym modelem, najszybszym łańcuchem czy najbardziej autonomicznym agentem.
może to system, który w końcu odpowiada:
skąd pochodzi ta inteligencja i kto powinien być nagrodzony za jej stworzenie?