Obserwuję @OpenLedger od jakiegoś czasu - głównie dlatego, że pozycjonowanie $OPEN wokół atrybucji danych AI wydawało się naprawdę inne niż zwykła narracja "budujemy infrastrukturę". Ale dzisiaj zacząłem dokładniej przyglądać się ich tokenomice. Nie podsumowaniu. Rzeczywistemu podziałowi dystrybucji.
I utknąłem w czymś, czego nie mogę się pozbyć od dawna.
Standardowa narracja wokół OpenLedger jest taka, że buduje nowy typ gospodarki - takiej, w której modele AI muszą płacić za dane, które konsumują, a ludzie, którzy te dane dostarczają, rzeczywiście dostają wynagrodzenie. Atrybucja na łańcuchu. Weryfikowalna proweniencja. Czysta pętla zachęt. Wciągnęło mnie to. Większość ludzi, którzy relacjonują ten projekt, wydaje się to kupować.
Ale tu jest moment, w którym coś się dla mnie zmieniło.
Kiedy spojrzałem na harmonogram odblokowania, alokację zespołu i inwestorów — mniej więcej jedna trzecia całkowitej $OPEN supplaj — nie wchodzi w życie aż do września 2026. To jest odblokowanie klifu. Nie stopniowe kroplówki. To ściana. A ten czas przypada dokładnie na moment, kiedy projekt teoretycznie zacznie generować realne przychody oparte na użytkowaniu, zakładając, że krzywe adopcji faktycznie się zrealizują.
Więc oto rzecz, nad którą ciągle się zastanawiam: cała narracja "gospodarki danych AI" zakłada, że wartość płynie z użycia. Modele konsumują dane, wkład jest nagradzany, token uchwyca tę wymianę. Ale jeśli największe wydarzenie podaży w historii $OPEN następuje dokładnie w momencie, kiedy sieć ma udowodnić swoją wartość — kto właściwie pozycjonuje się na długoterminowy model, a kto tylko trzyma do momentu otwarcia okna wyjścia?
Myślałem, że te dwie rzeczy są oddzielne. Narracja i vesting. Ale nie jestem pewien, czy tak jest.
Jest taka wersja, w której to wcale nie jest szkodliwe. Zespoły potrzebują wsparcia finansowego. Wczesni inwestorzy podejmują realne ryzyko. Struktury klifowe są standardowe. Wiem o tym. Ale jest coś niepokojącego w projekcie, którego oferta brzmi "zmieniamy sposób, w jaki modele AI płacą za informacje", a największe wydarzenie odblokowujące następuje dokładnie w momencie, gdy ta historia powinna być potwierdzona przez dane on-chain. To nie jest spisek. To po prostu niezręczny zbieg okoliczności strukturalnych, który myślę, że większość osób zajmujących się open nie analizuje wystarczająco długo.
Najbardziej irytującą częścią jest coś subtelniejszego niż samo odblokowanie. Chodzi o to, że model przypisania danych — prawdziwy czy nie — jest prawie niemożliwy do zweryfikowania w tej chwili. Możesz zobaczyć przepływy z portfeli. Możesz zobaczyć uczestnictwo w stakingu. Ale czy operatorzy modeli AI naprawdę płacą za pochodzenie, czy to nadal obietnica z białej księgi przebrana w wizualizacje on-chain — naprawdę nie potrafię stwierdzić z zewnątrz. I nie jestem pewien, czy większość detalicznych uczestników również to potrafi.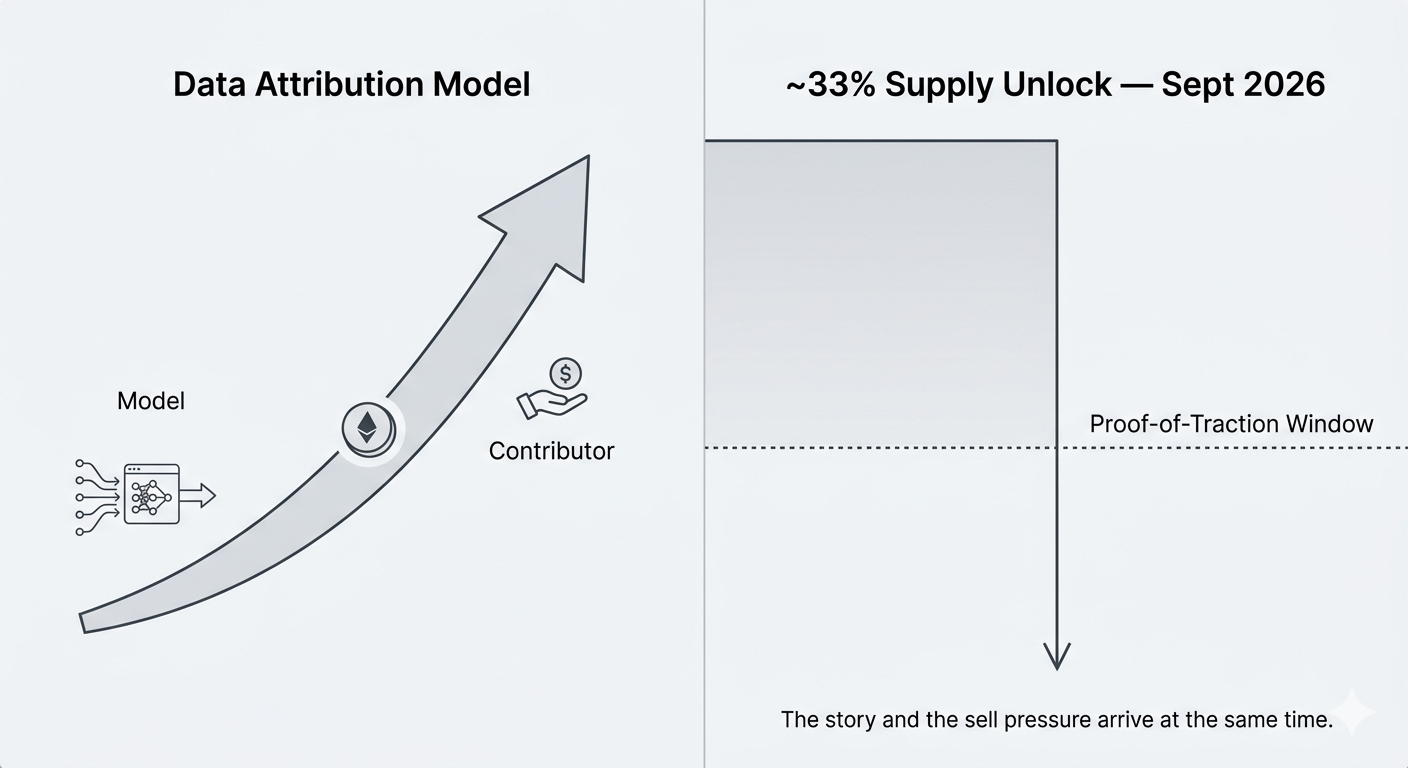
Co oznacza, że narracja wykonuje wiele ciężkiej pracy.
To nie jest unikalne dla OpenLedger. Większość projektów Web3 żyje z narracji, dopóki mechanika nie zostanie poddana testom wytrzymałościowym. Ale powód, dla którego to mnie tu niepokoi, jest taki, że narracja dotyczy przejrzystości — ostatecznie uczynienia przepływów danych AI widocznymi i odpowiedzialnymi. A jednak część, która teraz ma największe znaczenie, faktyczny sygnał behawioralny od konsumentów danych i operatorów modeli, jest w większości nieprzezroczysta.
Nie mówię, że model nie działa. Mówię, że czułbym się pewniej co do $OPEN at $X, gdyby odblokowanie klifu nie było tuż nad oknem, w którym sieć musi udowodnić swoją przyczepność. Te dwie rzeczy razem wymagają dużo od detalicznego posiadacza, aby cicho to przyswoić.