
Przewijałem ostatnio aktywność on-chain, nie szukając niczego konkretnego, po prostu obserwując, jak fragmentowane wszystko wciąż wydaje się. Jeden portfel skacze między łańcuchami, inny wchodzi w interakcję z modelem, a gdzie indziej zbiór danych jest ponownie wykorzystywany, podczas gdy nikt tak naprawdę nie widzi, gdzie ta wartość się podziała. Zatrzymało mnie to na chwilę. Wciąż mówimy o efektywności w crypto, ale przepływ wkładu wciąż wydaje się dziwnie niewidoczny.
OpenLedger (OPEN) znajduje się w tym niewygodnym miejscu pomiędzy tym, co jest produkowane, a tym, co jest rzeczywiście uchwycone. To AI blockchain próbuje uczynić dane, modele i agentów ekonomicznie czytelnymi. Wciąż staram się zdecydować, czy to ujęcie ma sens w praktyce, czy brzmi lepiej na papierze niż w rzeczywistych systemach.
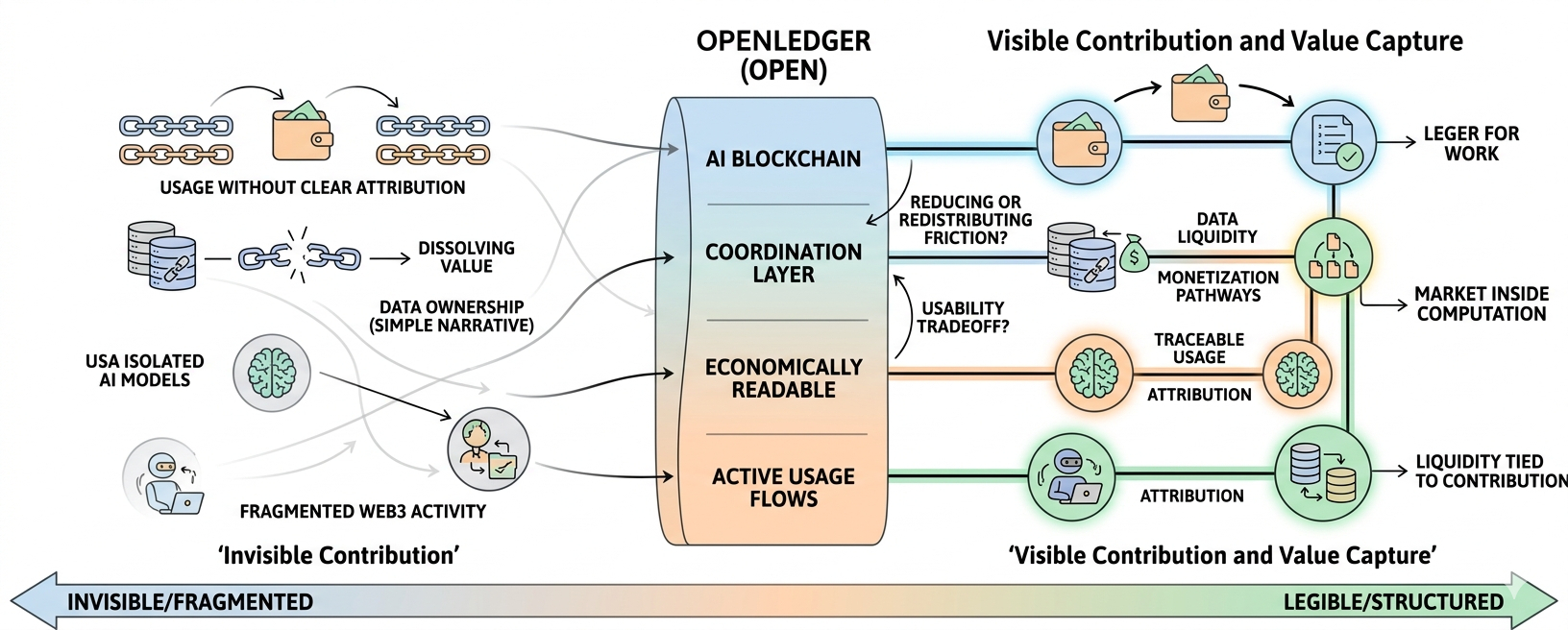
To, co przykuło moją uwagę, to nie tylko kąt AI. To idea płynności związanej z wkładem. Dane generowane są nieprzerwanie w Web3, modele są trenowane, agenci wykonują zadania, ale większość z tego rozpuszcza się w użyciu bez wyraźnych warstw przypisania. Może za bardzo nad tym myślę, ale czuję, że brakuje nam rejestru dla pracy, która nie jest czysto finansowa.
Pamiętam, kiedy "własność danych" była głównym tematem. Ta faza wydawała się prostsza, prawie zbyt prosta w retrospektywie. Posiadanie danych nie oznaczało automatycznie, że można z nich wyprowadzić wartość. OpenLedger zdaje się przesuwać tę rozmowę o jeden krok głębiej, w kierunku ścieżek monetyzacji, które nie są tylko prawami do przechowywania, ale aktywnymi przepływami użycia.
Jest też coś lekko niepokojącego w tym kierunku. Jeśli wszystko staje się monetyzowalne na poziomie modeli i agentów, czy zyskujemy jasność, czy tylko wprowadzamy dodatkową warstwę abstrakcji? Nie mam czystej odpowiedzi na to. To może pójść w obie strony, w zależności od tego, jak zaprojektowane jest przypisanie.
Pomysł, że agenci zarabiają lub kierują wartością na podstawie wykonania, jest interesujący, ale rodzi też pytania o granularność. W którym momencie wkład staje się zbyt fragmentaryczny, by go sensownie śledzić? Widziałem podobne próby w innych systemach, gdzie precyzja wzrasta, ale użyteczność cichutko cierpi.
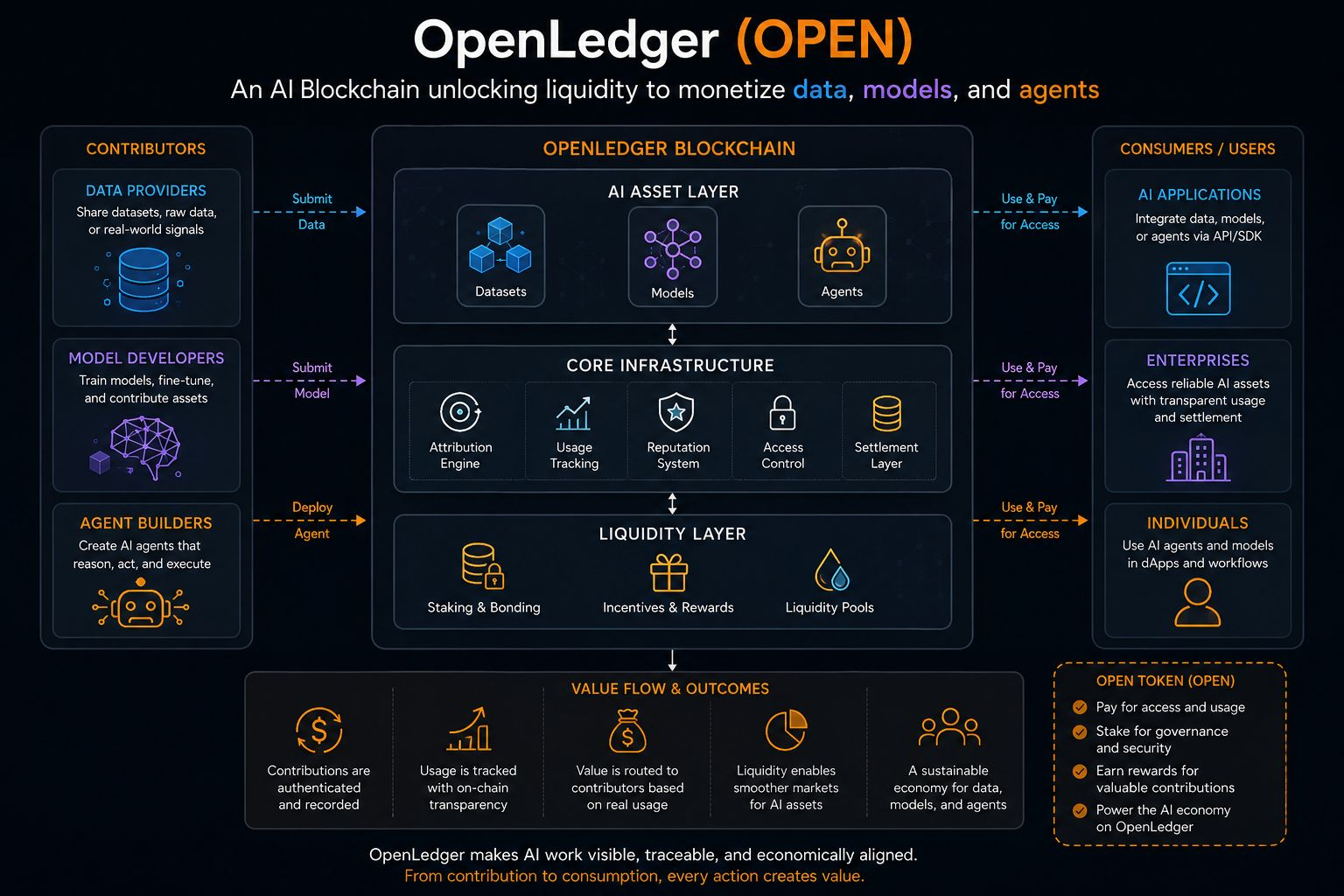
OpenLedger pozycjonuje się jako warstwa koordynacyjna między wynikami AI a rozliczeniem gospodarczym. Brzmi fajnie, ale w rzeczywistości warstwy koordynacyjne mają tendencję do absorbowania złożoności zamiast jej eliminowania. Nie jestem pewien, czy ta unika tej pułapki, czy po prostu przenosi ją w inne miejsce.
Mimo wszystko, jest coś przekonującego w próbie uczynienia wykorzystania modeli przejrzystym. W tradycyjnych systemach AI, wszystko zlewa się w czarną skrzynkę wnioskowania. Tutaj pomysł jest bliższy gospodarce interakcji. Każde wywołanie, każde ponowne wykorzystanie zbioru danych, każda akcja agenta potencjalnie ma znaczenie. To prawie przypomina rynek, który próbuje się uformować wewnątrz samego obliczenia.
Ale potem się zastanawiam, czy przeciętny użytkownik lub budowniczy w ogóle chce takiego poziomu widoczności? Czasami systemy stają się bardziej efektywne, ale mniej intuicyjne. A w krypto, ten kompromis zazwyczaj pojawia się później, nie od razu.
Z perspektywy rynku narracje wokół AI i infrastruktury mają tendencję do szybkiego cyklingu. To, co przetrwa, zazwyczaj nie jest najgłośniejszym ujęciem, ale częścią, która rzeczywiście redukuje tarcia. Ciągle się zastanawiam, czy OpenLedger redukuje tarcia, czy po prostu redystrybuuje je w bardziej złożonym stosie.
Jest też pytanie o samą płynność. Często zakładamy, że płynność dotyczy tokenów i głębokości handlu, ale tutaj wydaje się rozszerzać na aktywa informacyjne. Płynność danych brzmi użytecznie, ale wciąż nie jestem pewien, jak bezpośrednio przekłada się na trwałe przechwytywanie wartości bez zniekształceń.
Może bardziej interesującym kątem nie jest wcale monetyzacja, ale widoczność. Jeśli wkład staje się czytelny w systemach AI, nawet niedoskonały, to samo może zmienić sposób, w jaki zachowują się budowniczy. A może po prostu tworzy nowe formy optymalizacyjnej gry. Widziałem oba wyniki w podobnych konfiguracjach.
Nie sądzę, że OpenLedger ma jeszcze wyraźny punkt końcowy i może to być w porządku. Większość wczesnych warstw infrastrukturalnych nie ma. Zaczynają jako eksperymenty w koordynacji i powoli twardnieją w coś bardziej zdefiniowanego, lub znikają, zostając wchłoniętymi przez szersze stosy.
To, co mi zostaje, to myśl, że zmierzamy w kierunku systemów, gdzie wartość nie jest tworzona ani transferowana tylko, ale ciągle na nowo mierzona, gdy przechodzi przez modele i agentów. Nie jestem do końca przekonany, czy jesteśmy gotowi na taki poziom granularności, ale czuję, że kierunek już się formuje, niezależnie od tego, czy jesteśmy na to gotowi.
\u003ct-43/\u003e\u003cm-44/\u003e\u003cc-45/\u003e
