Jest pewien rodzaj zmęczenia, które pojawia się po przesłaniu trzeciej partii anotacji danych w ciągu dnia i nadal nie jesteś pewny, czy to zostało policzone.
Nie zmęczenie sieciowe. Nie tarcie portfela. Coś cichszego — uczucie wkładu w system, którego nie potrafisz w pełni odczytać.
Więc zacząłem dokładniej sprawdzać @OpenLedger . Nie dokumenty. Rzeczywisty przepływ wkładu. Co jest rejestrowane, co jest ważone, co protokół faktycznie rejestruje w porównaniu do tego, co zakładasz, że rejestruje, gdy klikniesz wyślij.
co myślałem, że się dzieje
Założenie, które większość ludzi wnosi do protokołów wkładów AI, jest proste: więcej pracy zgłoszonej oznacza więcej udziału w wyniku. To intuicyjne. Anotujesz, weryfikujesz, trenujesz — akumulujesz.
Model OpenLedger opiera się na tej intuicji, ale działa inaczej pod spodem. Warstwa $OPEN incenty nie tylko liczy zgłoszenia. Waży je. Jakość wkładu, konsensus walidacji węzłów i pochodzenie danych wchodzą w to, co faktycznie trafia do portfela.
Myślałem, że to rozumiem. Nie rozumiałem.
Napięcie nie polega na tym, że system jest niesprawiedliwy. Napięcie polega na tym, że możesz aktywnie przyczyniać się — zgłaszając ważną pracę, pozostając online, wykonując zadanie — a mimo to akumulować mniej niż ktoś, kto prowadzi lżejszy ładunek pracy z lepiej źródłowanymi zestawami danych.
Wysiłek i zysk nie poruszają się razem tak, jak się spodziewasz.
moment, w którym stało się to konkretne
Pamiętam, jak siedziałem z dwoma otwartymi kartami przeglądarki. Jedna to był mój pulpit wkładów. Druga to wątek, w którym ktoś opisywał swoje ustawienie węzła — minimalna ręczna anotacja, głównie uporządkowane dane przesyłane z istniejących repozytoriów.
Ich wskaźnik akumulacji był zauważalnie inny od mojego. Nie dramatycznie. Ale wystarczająco, aby zmienić moje myślenie o tym, co oznacza "uczestnictwo" w tym protokole.
Myślałem, że robię więcej. Z logiki systemu wynikało, że wykonuję więcej pracy, ale niekoniecznie pracy o wyższym sygnale. To nie jest błąd. To model. Ale odczuwanie tego w czasie rzeczywistym jest inne niż czytanie o tym w litepaper.
Na łańcuchu możesz odwołać się do interakcji umowy dystrybucji nagród węzłów OpenLedger — szczególnie wydarzeń związanych z oceną wkładów zarejestrowanych na łańcuchu w zakresie bloków 19,872,000–19,875,000 (sieć Base, około 16–17 maja 2025) — gdzie dostosowania wagi konsensusu walidatorów były odzwierciedlane w różnicowej akumulacji w adresach aktywnych uczestników. Rozpiętość między uczestnikami z górnego kwartylu a medianą nie była trywialna.
pętla sprzężenia zwrotnego, której nikt nie rysuje jasno
Oto prosty model, który zbudowałem w mojej głowie po tym.
Większość ludzi myśli o protokołach wkładów AI jako o linarnych: zgłoś → zweryfikuj → zarabiaj. Architektura OpenLedger jest bliższa pętli ważonej reputacją. Jakość twojego wcześniejszego wkładu wpływa na to, jak ocenia się twoje obecne zgłoszenia. Co oznacza, że wczesni uczestnicy z czystymi historiami danych kumulują. Późni gracze z wysokim wolumenem, ale głośniejszymi danymi nie.
To nie jest Ponzi. To krzywa kumulującej się jakości.
Porównania rynkowe, które przychodzą mi na myśl, to nie inne tokeny AI. Są bliższe temu, jak Render Network obsługuje priorytetyzację zadań — zaufane węzły są kierowane do wyższej wartości renderów — lub jak dowód pokrycia Helium historycznie nagradzał jakość umiejscowienia ponad surowy czas działania. W obu przypadkach protokół ostatecznie oddziela "aktywny" od "efektywnego".
$OPEN'owa napięcie to dokładnie ta luka. I nie jest widoczne, dopóki nie byłeś wystarczająco długo w pętli zadań, aby poczuć delta.
ale ta część wciąż mnie niepokoi
Jeśli jakość wkładu kumuluje się, to długoterminowa akumulacja wartości protokołu skoncentruje się — nie przez blokady tokenów czy akumulację wielorybów, ale przez przewagę epistemiczną. Wczesni uczestnicy z dobrze źródłowanymi danymi treningowymi będą mieli strukturalną przewagę, której późniejsi uczestnicy nie będą mogli łatwo zniwelować.
To w porządku dla jakości wyjścia AI sieci. Może to być problem dla historii dystrybucji tokenów.
Nie mam czystej odpowiedzi na to. Nie jestem pewien, czy zespół też ma, ani czy to w ogóle właściwe ramy. Ale to jest część, do której ciągle wracam, myśląc o tym, co "szkolenie AI w zdecentralizowany sposób" oznacza w praktyce versus w pozycjonowaniu.
siedząc z tym
Co mnie uderza, kilka dni po tej chwili z dwoma kartami, to jak wiele z narracji dotyczącej wkładów AI wciąż opiera się na metaforze pracy. Pracujesz, zarabiasz. To zrozumiałe, motywujące, odzwierciedla znane instynkty.$OPEN
Ale OpenLedger — i prawdopodobnie każdy poważny protokół w tej przestrzeni ostatecznie — buduje coś bliższego rynku ekspertyz. Jednostką wymienianą nie jest wysiłek. To jakość sygnału. A jakość sygnału jest trudniejsza do wyprodukowania, trudniejsza do wizualizacji, trudniejsza do zakomunikowania komuś, kto dopiero wchodzi w tę przestrzeń.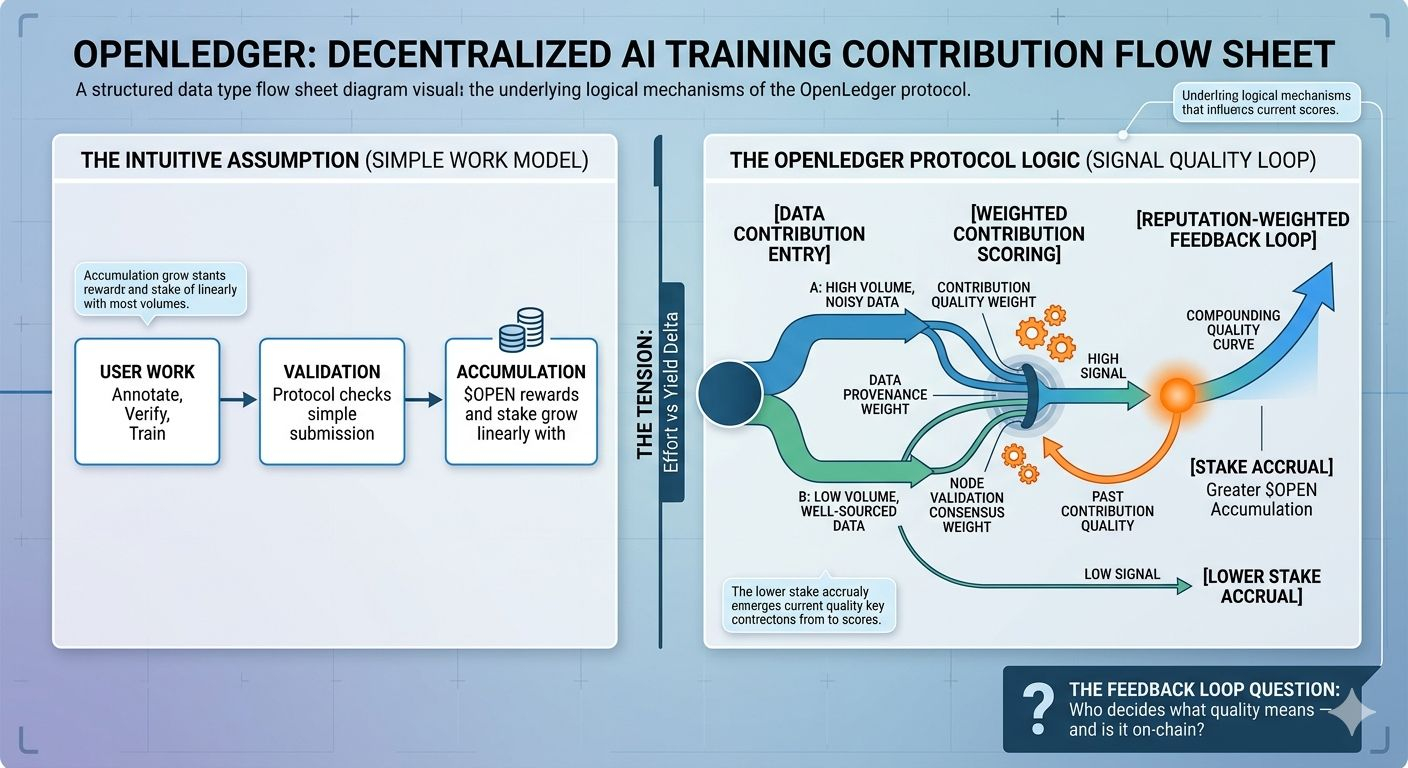
Nie uważam, że to błąd. Myślę, że to po prostu... nie jest jeszcze opowiadana historia.
Pytanie, z którym nie mogę przestać siedzieć:
Jeśli protokół już nagradza jakość nad ilością, kto decyduje, co oznacza jakość — i czy ta decyzja jest sama w sobie na łańcuchu?