I did not immediately understand why OpenLedger existed.
At first glance, it looked dangerously close to the familiar pattern that appears every cycle: take whatever technology is dominating headlines, attach a blockchain to it, introduce a token layer, and frame the whole thing as infrastructure for the future. After enough time watching crypto narratives form and dissolve, skepticism becomes almost automatic. Most systems sound profound from a distance because abstraction hides their weaknesses. The closer you get, the more you usually discover that the architecture is thinner than the story around it.
But OpenLedger stayed in my head longer than I expected.
Not because of marketing. Actually, the opposite. The more I looked into it, the more it felt like the project was attempting to solve something uncomfortable that the broader AI industry still avoids discussing honestly. Everyone talks about building intelligence. Very few talk seriously about ownership around intelligence.
That difference matters more than people realize.
The current AI economy runs on an enormous amount of invisible labor. Datasets compiled over years. Human feedback loops. Fine-tuning contributions. Agent interactions. Behavioral traces. Synthetic outputs improving future systems. Knowledge extracted from millions of fragmented participants who often do not even realize they are contributing economic value in the first place.
Yet once these systems become commercially useful, the value tends to consolidate quickly around whoever owns the aggregation layer. The model provider captures the revenue. The platform controls distribution. The infrastructure operator becomes the gatekeeper. Meanwhile the underlying informational substrate that made the intelligence possible dissolves into the background like it never existed.
I think this is the part that OpenLedger is reacting to.
Not AI itself, but the asymmetry forming around AI.
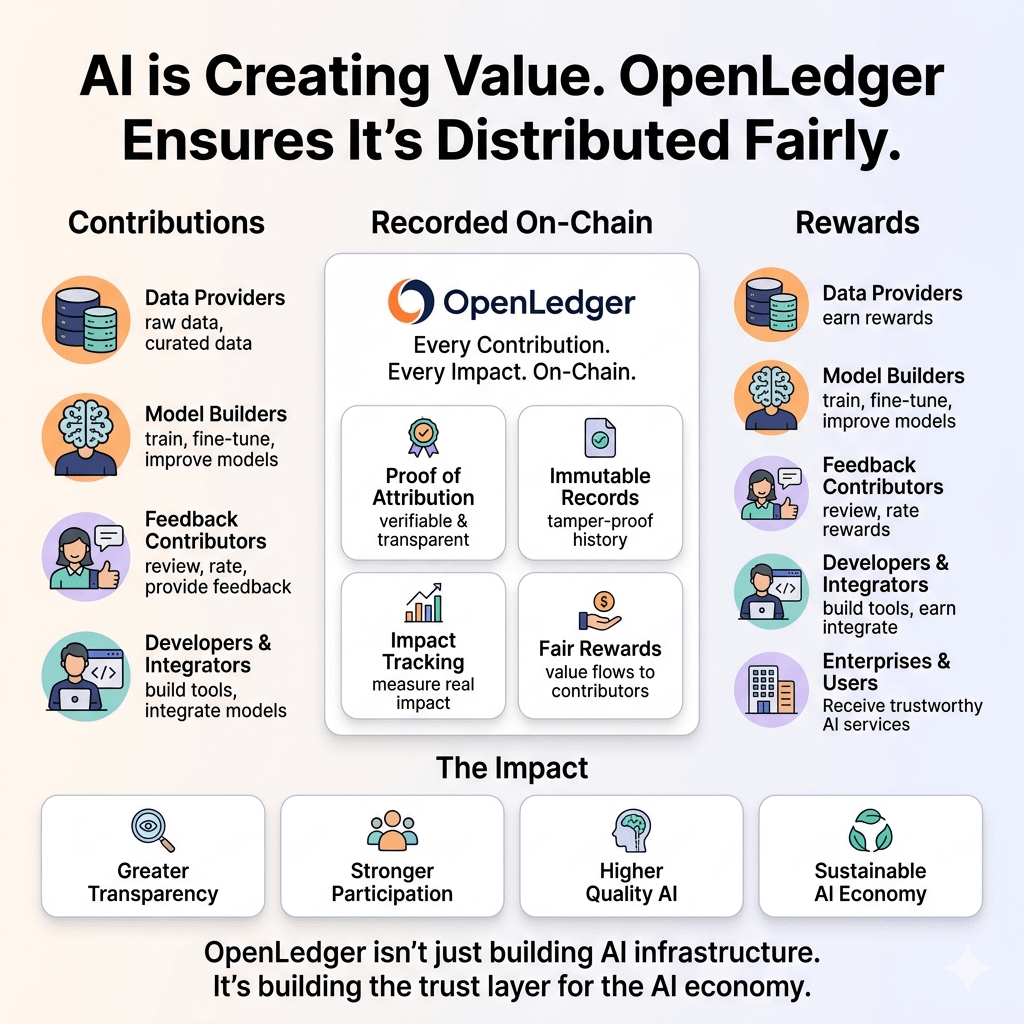
The protocol seems built around a simple but surprisingly difficult idea: what if data, models, agents, and inference outputs were treated as economic assets with traceable participation rather than raw material absorbed into opaque systems?
That sounds straightforward when written in a sentence. In practice, it introduces an entirely different way of thinking about AI infrastructure.
Most AI systems today behave like centralized extraction engines. Information flows inward, models refine themselves behind closed systems, and economic rewards move upward toward whoever controls computation and distribution. Attribution exists in fragments at best. Usually it disappears entirely once data enters the training process.
OpenLedger appears to question whether that model remains sustainable once AI becomes deeply embedded into everyday economic activity.
Because intelligence is no longer static software.
It is becoming collaborative, modular, and recursive.
One model depends on another model. Agents interact with external systems. Datasets evolve continuously. Outputs become future inputs. AI is slowly turning into an ecosystem rather than a product, and ecosystems create ownership problems that traditional infrastructure was never designed to handle.
That is where OpenLedger started becoming more interesting to me.
Not as a “decentralized AI platform,” because honestly that phrase has lost most of its meaning, but as an attempt to create accounting infrastructure for intelligence itself.
And I do not mean accounting in the financial spreadsheet sense.
I mean accounting in the deeper structural sense: systems capable of recognizing contribution, tracking participation, and distributing value across increasingly complex computational environments.
The modern internet was never really designed for that.
Most digital systems still assume a relatively simple relationship between creator, platform, and consumer. AI breaks that assumption completely. A single output might involve countless invisible dependencies layered together across time. Data contributors, model builders, inference providers, retrieval systems, autonomous agents, validators, and external applications all become part of the same economic chain.
The moment intelligence becomes composable, ownership becomes blurry.
That blurriness is where most existing systems quietly fail.
Centralized companies solve it through opacity. They absorb complexity internally and monetize the output externally. Efficient, profitable, scalable. But also structurally unequal, because contributors rarely remain visible once value compounds.
OpenLedger seems to approach the problem differently. The protocol architecture appears designed around keeping participation economically legible as activity moves through the network. Attribution mechanisms, validation systems, staking structures, and decentralized coordination are not just technical features here. They are attempts to answer a larger question about whether intelligence economies can function without hiding the people and systems contributing to them.
I think that philosophical layer is what separates this from many shallow AI-chain narratives.
The project feels less obsessed with creating artificial scarcity around intelligence and more interested in making contribution measurable enough to sustain open participation.
Of course, that immediately creates another problem.
The moment contribution becomes measurable, people begin optimizing for metrics instead of meaning.
This is where decentralized systems become complicated very quickly. Incentives are never neutral. If a protocol rewards data contribution, someone will generate low-quality synthetic data at scale. If validation becomes profitable, groups will coordinate around influence. If governance exists, capital eventually tries to dominate it. Human behavior adapts aggressively around whatever the system chooses to reward.
Crypto has been relearning this lesson for years.
Idealism often enters decentralized systems first. Optimization follows immediately after.
I actually think OpenLedger becomes more credible once you stop viewing it as a perfect coordination system and start viewing it as an imperfect negotiation layer between competing incentives.
Because that is probably what real decentralized AI infrastructure will look like in practice.
Messy. Recursive. Politically complicated.
Not the clean utopian version people sometimes imagine.
And maybe that is okay.
Perfect attribution was never realistic anyway. Human knowledge itself is too interconnected for clean ownership boundaries to exist. Every model inherits prior structures. Every dataset contains echoes of older systems. Every idea emerges from overlapping networks of influence. Trying to isolate contribution with mathematical purity may ultimately be impossible.
But imperfect visibility can still matter.
There is a meaningful difference between a world where contribution disappears completely and a world where contribution remains partially observable, economically recognized, and structurally embedded into the infrastructure itself.
That difference shapes power.
Right now, the AI industry is moving toward enormous concentration because aggregation naturally compounds. The more data, computation, and distribution a company controls, the more intelligence it can produce, which then attracts even more users and data. It is an accelerating feedback loop. Efficient, but deeply centralizing.
Projects like OpenLedger seem to emerge from the belief that intelligence should perhaps evolve more like a network economy than a corporate product stack.
Not fully decentralized in the ideological sense. That word often becomes detached from reality. Large-scale systems still require coordination, governance, dispute resolution, and incentive enforcement. But decentralized enough that value does not disappear silently into closed accumulation systems.
I find that idea increasingly important because AI is no longer just software infrastructure. It is becoming social infrastructure.
The systems being built now will influence how knowledge, labor, creativity, and economic participation are recognized in the future. That is not a small design decision. It affects who remains visible once intelligence itself becomes automated and distributed across machines.
And honestly, I do not think the industry has fully processed that yet.
Most conversations still focus on capability. Smarter models. Faster inference. Better agents. More autonomy.
But capability without transparent economic structure eventually creates imbalance. We already saw this happen with the internet itself. Massive participation generated enormous value, yet ownership concentrated heavily around a relatively small number of platforms that controlled visibility and distribution.
AI could easily repeat that pattern at an even larger scale.
OpenLedger feels like one attempt to interrupt that trajectory before it fully solidifies.
Whether it succeeds is another question entirely.
The governance could become difficult. The economics could distort over time. Attribution systems may become noisy or exploitable. Scalability pressures may force compromises that slowly recreate centralization in different forms. This is the uncomfortable reality almost every decentralized coordination system eventually encounters.
But even with those flaws, I think the experiment itself matters.
Because underneath the protocol mechanics, token structures, and infrastructure layers sits a deeper recognition that the future AI economy may ultimately depend less on intelligence generation and more on intelligence ownership.
Not ownership in the simplistic sense of patents or platform control, but ownership as ongoing economic participation inside systems that continuously evolve through collective contribution.
That is a much harder problem than building models.
And honestly, I suspect it may become the more important one.