

To jest dziwna ironia w naszych dyskusjach o Web3 i AI. Na papierze nie przestajemy chwalić czystego przypisania AI i sprawiedliwej własności danych. Ale rzeczywistość na gruncie jest dość chaotyczna. Jeśli twoje oryginalne dane zostały użyte do trenowania masywnego modelu AI, jak możesz odzyskać swoje finansowe prawa bez długich i męczących sporów? To jest ta praktyczna luka, którą koniecznie trzeba rozwiązać. I właśnie tutaj system @OpenLedger oferuje realną użyteczność.
Jako doświadczony badacz Web3, zawsze dokładnie studiuję whitepapery i protokoły. Moje podejście jest bardzo proste i realistyczne, bez pustych haseł, po prostu prawdziwa, wartościowa i przejrzysta ocena. Więc przejdźmy dzisiaj#OpenLedger do zrozumienia rdzenia filozofii i mechaniki w prostych słowach jak nauczyciel. Rozbijmy to na format pytań i odpowiedzi, aby skomplikowane kwestie techniczne były całkowicie jasne. Oto kilka pytań, które$OPEN Na które dowiemy się... więc zaczynajmy...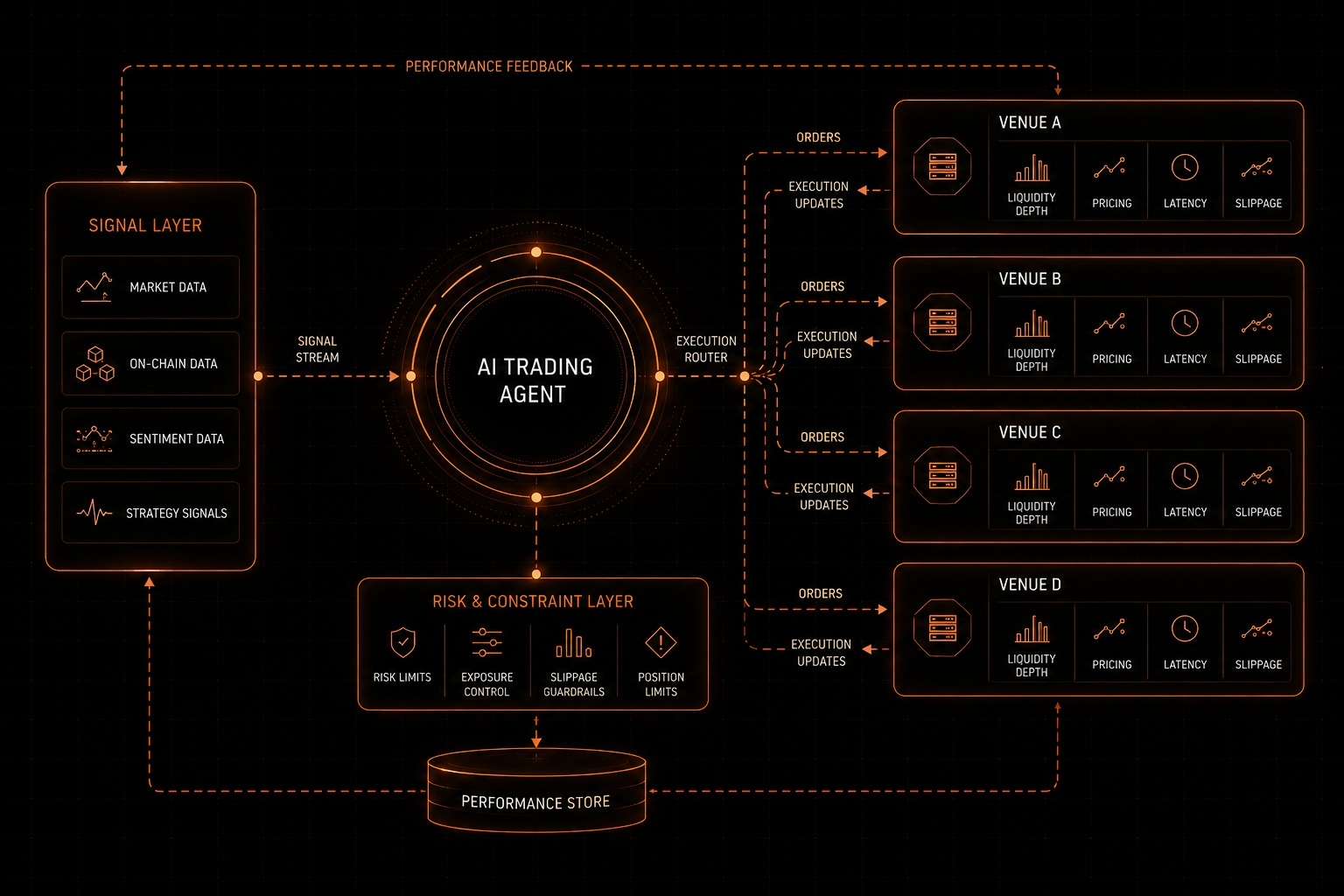
Czym dokładnie jest OpenLoRA i jak działa jego kosztowo efektywny mechanizm serwowania modeli?
Ciągłe trenowanie i dostosowywanie modeli AI to technicznie ciężki i praktycznie bardzo kosztowny proces. OpenLoRA to zasadniczo mechanizm, który daje deweloperom swobodę serwowania modeli w kosztowo efektywny sposób, bez masowych zasobów centralnych serwerów. Pomaga to deweloperom uruchamiać wyspecjalizowane modele AI przy mniejszym kodzie i zoptymalizowanych kosztach. Myśl o tym jak o inteligentnym, lekkim silniku, który wykonuje ciężką pracę, ale bez zbędnego paliwa.
Jaką rolę odgrywają ZKP w AI? Czy OpenLedger naprawdę bezpiecznie obsługuje prywatne wnioskowanie AI?
Tak, ziomek, absolutnie. Kiedy mowa o przyjęciu AI na poziomie przedsiębiorstw, prywatność danych staje się największą przeszkodą. Duże firmy nie chcą dostarczać swoich wrażliwych danych otwartym modelom AI. ZKP (Zero-Knowledge Proofs) pozwalają tutaj na całkowite weryfikowanie wniosków AI bez ujawniania oryginalnych, poufnych danych światu. To oznacza, że przedsiębiorstwa mogą bezpiecznie weryfikować w sposób trustless. OpenLedger wykorzystuje ten dowód, aby zapewnić, że dane pozostaną prywatne, a wyniki modelu AI będą rzetelnie weryfikowalne.
Teraz porozmawiajmy o rzeczywistym frameworku tego czystego ekosystemu.
Tutaj wchodzi logika Open Consensus. Ta zdecentralizowana sieć zapewnia, że wszystkie wkłady AI są weryfikowane bez żadnej centralnej władzy. Żaden tech gigant nie zdecyduje w zamkniętym pokoju, czyj zestaw danych był bardziej wartościowy.
Ale szczerze mówiąc, samo otwarte weryfikowanie to za mało. Potrzebujemy sztywnej, niezmiennej pamięci, którą nazywamy IMmutable Data Provenance. Ten otwarty protokół starannie śledzi, jakie dokładnie surowe dane były używane przy tworzeniu modeli AI i zapewnia, że ta historia nigdy nie zostanie zmieniona ani zmanipulowana.
Spróbujmy to zrozumieć na przykładzie z rzeczywistego świata.
Załóżmy, że jesteś niezależnym naukowcem danych lub artystą, który stworzył wysoce dokładny, wyspecjalizowany zestaw danych. Duża firma AI zbiera dane globalnie, aby trenować swój nowy model, w tym również twój zestaw danych. W normalnym świecie Web2 nigdy nie dostaniesz za to uznania ani grosza. Jeśli złożysz roszczenie, sprawa sądowa będzie trwała latami. Ale w sieci OpenLedger, pochodzenie danych zostanie na stałe zapisane na blockchainie, że twoje dokładne dane były używane w tym modelu AI.
Gdy historia i przejrzystość pochodzenia stają się całkowicie jasne, zaczyna się sprawiedliwe uznanie dla oryginalnych wkładów danych przez AI Model Training Attribution.
Jak w końcu uczynić to wszystko finansowo wykonalnym?
To ten punkt zwrotny, w którym tokenomika pokazuje swoją magię. Jeśli system IMmutable Data Provenance jest pamięcią i prawdą, token OPEN jest potężnym narzędziem, które przekształca te roszczenia w rzeczywistość.
Użyteczność i integracja EVM:
Token OPEN to nie skomplikowany żargon z whitepapera czy tylko ładna nazwa. To finansowy silnik całego systemu. System nie tylko śledzi, kto dostarczył jakie dane, ale także nagradza wkłady za ich pracę. Gdy sieć przypisania zostaje udowodniona, smart kontrakty automatycznie rozdzielają sprawiedliwe wypłaty. Żadnych kłótni, żadnych pośredników, tylko jasne zasady i przejrzyste nagrody. A ponieważ OpenLedger jest w pełni kompatybilny z Ethereum (EVM), przedsiębiorstwa Web3 i deweloperzy mogą smartly wpiąć swoje istniejące portfele korporacyjne i smart kontrakty w ten system.
Dlaczego teraz - dlaczego to jest ważne?
Uważam, że przypisanie bez zarządzania konfliktami to tylko hobby. Jeśli inteligentnie śledzisz, kto co wniósł, ale na tej podstawie nie możesz automatycznie rozwiązywać sporów finansowych, twój system nie jest praktycznie komercyjnie wykonalny. Wprowadzenie OpenLedger sprawia, że ta infrastruktura staje się dokładnie warstwą konfliktów finansowych czytelną maszynowo, gdzie kod sam wymierza sprawiedliwość. To nie jest narracja krótkoterminowego rynku byka ani hype, to absolutne fundamenty długoterminowej zrównoważonej AI dla przedsiębiorstw. Sygnały, na które czekamy w integracji rzeczywistego użycia i codziennych procesów roboczych, zaczynają się tutaj.
Uważam, że w nowej erze AI dane będą nie tylko paliwem, ale klasą aktywów finansowych.
Ostatnie pytanie dla Ciebie
W miarę jak modele AI będą coraz bardziej polegać na naszych danych własnościowych i ludzkiej pracy, czy nasza branża jest dziś gotowa na całkowicie przejrzyste i on-chain zarządzanie tymi ogromnymi sporami wpływu AI?