

OpenLedger is one of those projects that does not fully make sense if you only look at it from the surface. At first glance, it can easily be placed in the same crowded bucket as every other AI blockchain project. There is a token. There is talk of data, models, agents, liquidity, and ownership. The usual vocabulary is there, and that can make it easy to dismiss too quickly.
But OpenLedger becomes more interesting when the focus moves away from the broad AI branding and toward the specific problem it is trying to organize around: attribution.
That is the part of the project that feels worth studying.
OpenLedger is not simply trying to say that AI should be decentralized. That would be too vague. The stronger idea is that AI systems need a way to remember where their value came from. If a model is trained on contributed data, improved through specialized datasets, used by agents, and eventually generates revenue, then the people or communities behind those inputs should not completely disappear from the economic loop.
That is the core tension OpenLedger is trying to work with.
Most AI systems today are very good at absorbing value and very bad at explaining who helped create it. Data goes in. A model comes out. The model becomes useful. The reward usually collects around the platform, the lab, or the company that owns the interface. The original contributors, data owners, curators, and domain experts often become invisible.
OpenLedger is built around the idea that this should change.
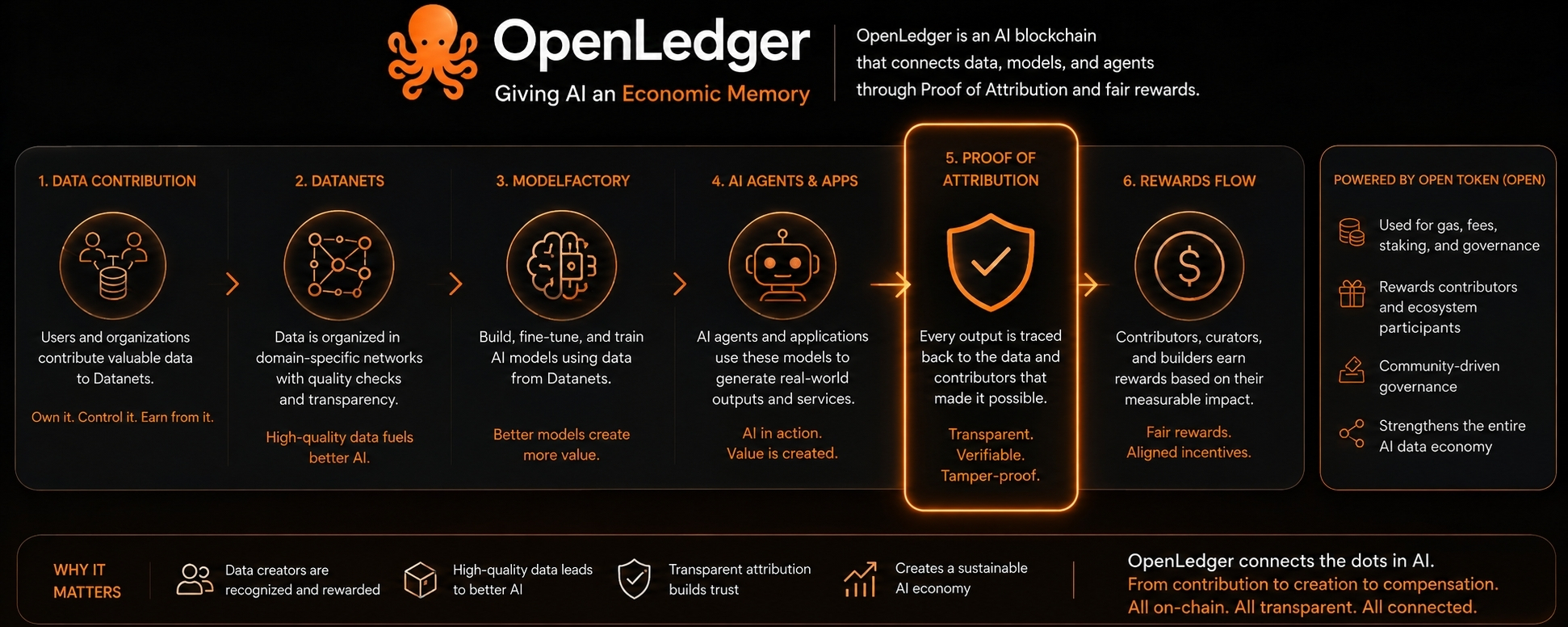
Its main concept, Proof of Attribution, is meant to track how data contributes to AI outputs and then connect that contribution to rewards. On paper, that sounds clean. In reality, it is a very difficult thing to do. AI attribution is not simple. A model does not behave like a spreadsheet where every output can be traced neatly back to one input. Data influence is messy. Some data matters because it appears often. Some matters because it teaches a rare edge case. Some data may shape a model in ways that are hard to measure directly.
That is why OpenLedger feels less like a finished answer and more like a serious attempt to build around a problem most AI platforms avoid.
The project’s most important piece may be its Datanets. These are domain-specific data networks where contributors can provide data that may be used to train or fine-tune AI models. This is where OpenLedger starts to feel different from projects that only talk about AI agents or decentralized compute.
The focus on specialized data makes sense.
Trying to compete with large AI labs on general-purpose models is a brutal game. Those companies have huge compute budgets, massive datasets, distribution, and research teams. OpenLedger’s more realistic opening is not to beat them at everything. It is to build an environment where useful, narrow, high-quality data can become an asset.
That is a better angle.
A good Datanet could matter if it contains data that is hard to find elsewhere. A legal dataset, a medical dataset, a trading dataset, a local language dataset, an industry-specific dataset — these things can be genuinely valuable if they are clean, permissioned, and maintained properly. The value is not just in having a lot of data. The value is in having the right data with the right structure and the right ownership trail.
That is where OpenLedger’s design starts to make sense.
Still, this is also where the project has to prove the most.
If Datanets are weak, the whole system becomes less convincing. A data network is only useful if the data inside it is useful. If contributors upload low-quality material just to chase rewards, the system can become noisy very quickly. If validation is unclear, users may not trust the models trained on that data. If attribution is too easy to game, rewards may flow to the loudest or most active participants instead of the most useful ones.
This is the boring part of the project, but it is probably the most important part.
OpenLedger needs strong filtering. It needs clear validation. It needs ways to handle duplicate data, bad data, copied data, and low-effort submissions. It also needs a reward system that does not accidentally encourage people to flood the network with useless material.
That is not a small challenge.
The ModelFactory side of OpenLedger is also important because it gives users a way to build or fine-tune models using datasets inside the ecosystem. This part shows that the project is not only thinking about data storage or token rewards. It wants data to move into actual model creation.
That matters because data alone is not the final product. A dataset becomes more valuable when it can improve a model, and a model becomes more valuable when people actually use it.
The question is whether OpenLedger can make that full loop visible.
A contributor adds data. The data enters a Datanet. A model is trained or fine-tuned. Someone uses the model. Revenue is generated. Attribution is calculated. Contributors are rewarded.
That loop is the project.
Everything else should support that loop.
This is also where OpenLedger has to be careful with complexity. The project already has many moving parts: Datanets, Proof of Attribution, ModelFactory, agents, staking, token utility, governance, and ecosystem activity. Each part may have a purpose, but together they can make the project feel crowded.
The strongest version of OpenLedger is actually simple.
It is trying to create an economic layer for AI contributions.
That should stay at the center.
The agent side of the project is interesting, but it needs to stay connected to that core idea. AI agents are everywhere right now, and because of that, the word has lost some meaning. A project saying it has agents is not enough anymore. The useful question is what those agents actually do inside the system.
For OpenLedger, agents become more meaningful if they use specialized models built from Datanets, and if the usage of those models sends value back through the attribution system. In that case, agents are not just an extra feature. They become part of the economic flow.
But if the agent layer sits separately from the attribution system, it becomes less interesting. Then it risks feeling like something added because the market currently likes agents.
OpenLedger’s strongest idea is attribution. The rest of the project should serve that.
The OPEN token fits into this structure as the native asset used for gas, fees, staking, model-related activity, inference, governance, and contributor rewards. The token design makes sense at a basic level. But the important question is not whether the token has listed utilities. Most crypto projects can list utilities.
The real question is whether there will be repeated demand that comes from actual usage.
Will people pay to use models built through OpenLedger?
Will contributors earn enough for participation to feel worthwhile?
Will developers and data owners prefer this system over more familiar AI platforms?
Will Datanets create value that users can clearly see?
That is where the token story becomes real or weak.
A token tied to speculation can move for a while without much product usage. But a token tied to an attribution economy needs activity. It needs fees. It needs model usage. It needs contributors. It needs a reason for people to come back after the campaign rewards and launch excitement fade.
This is where I remain cautious.
OpenLedger has a strong concept, but concepts do not automatically become usage. The product has to feel practical. Users need to understand what they are doing. Contributors need to trust the reward system. Model builders need good tools. The attribution results need to feel believable.
That last point is especially important.
If OpenLedger says a certain contributor deserves a reward because their data influenced a model output, users need some way to trust that claim. Not necessarily every technical detail, but enough transparency to believe the system is not arbitrary.
Attribution creates consequences. Once money is attached to credit, people will care deeply about how credit is assigned.
This is what makes OpenLedger both promising and difficult.
It is trying to put a price on contribution inside AI systems. That is a powerful idea, but it also creates disputes. People will question why one dataset earned more than another. They will question whether the attribution model is fair. They will question whether low-quality contributors are being filtered properly. They will question whether private or copyrighted data is being used correctly.
These questions do not weaken the project. They define the project.
OpenLedger is working in a space where the hard parts cannot be avoided.
What I like about the project is that it is not just chasing the broad idea of “AI plus blockchain.” The best version of OpenLedger has a clear reason to use blockchain: tracking ownership, recording contribution, distributing rewards, and creating a transparent economic history around AI assets.
That is more convincing than pretending large-scale AI training needs to happen fully on-chain.
The chain is not the AI brain here. It is closer to the memory and settlement layer around AI activity. That is a much more believable role.
OpenLedger also exposes something people often ignore: data is not passive. Data has owners, collectors, curators, labelers, and communities behind it. If AI systems keep becoming more valuable, the fight over who gets paid for data will only become louder.
OpenLedger is positioning itself around that fight.
It is not guaranteed to win. It may struggle with adoption. It may struggle with data quality. It may struggle with explaining attribution in a way normal users trust. It may also struggle with keeping the product focused instead of spreading itself across too many AI narratives.
But the project is asking the right kind of question.
Not “how do we make another AI token?”
More like:
When AI creates value from contributed data, how do we make sure that value does not vanish into a black box?
That is the part that makes OpenLedger worth watching.
The project feels strongest when it stays close to that question. Datanets make sense when they create useful, specialized data pools. ModelFactory makes sense when it turns those data pools into working models. Agents make sense when they use those models and send value back through the system. OPEN makes sense when it powers real activity instead of just market speculation.
Everything depends on whether OpenLedger can make that loop work in practice.
Right now, I would describe OpenLedger as an ambitious AI attribution network rather than just an AI blockchain. That framing feels more accurate. The blockchain part matters, but only because the project is trying to coordinate ownership, usage, and rewards around AI data and models.
The idea is strong.
The execution still has to prove itself.
And that is probably the fairest way to look at OpenLedger. Not as a finished product that has solved AI ownership, and not as another empty AI narrative either. It sits somewhere more interesting than that. It is a project trying to build economic memory for AI — a way for data, models, contributors, and outputs to remain connected after value is created.