

Ostatnio ciągle wracam do tej samej niewygodnej myśli. Może gospodarka AI nigdy nie była naprawdę o modelach. Może zawsze chodziło o niewidzialną pracę. Każdy prompt, każdy wzór handlowy, każdy zestaw danych, każda interakcja online cicho karmi inteligencję maszynową gdzieś w tle. Nieustannie przyczyniamy się do systemów, których nie posiadamy. A przez długi czas branża traktowała to jako normę. Dane wpływały, korporacje rosły, a przypisanie znikało w infrastrukturze czarnej skrzynki, której nikt nie mógł zbadać.
Potem zacząłem testować @OpenLedger mocniej, i szczerze mówiąc, cała ramka dotycząca własności AI zaczęła wydawać się inna.
Na początku zakładałem, że protokół po prostu pozycjonuje się w obecnym cyklu narracyjnym AI jak wszyscy inni. Rynki kryptowalutowe robią to nieustannie. Jeden miesiąc wszystko staje się modułowe. W następnym miesiącu wszystko staje się agentowe. Ale architektura #OpenLedger czuła się wyjątkowo skoncentrowana na czymś głębszym niż uwaga rynku. Biała księga wielokrotnie wraca do jednego centralnego pomysłu: inteligencja powinna pozostać ekonomicznie związana z ludźmi i systemami, które w nią wkładają. Nie symbolicznie. Programowo.
Ta różnica ma większe znaczenie, niż się spodziewałem.
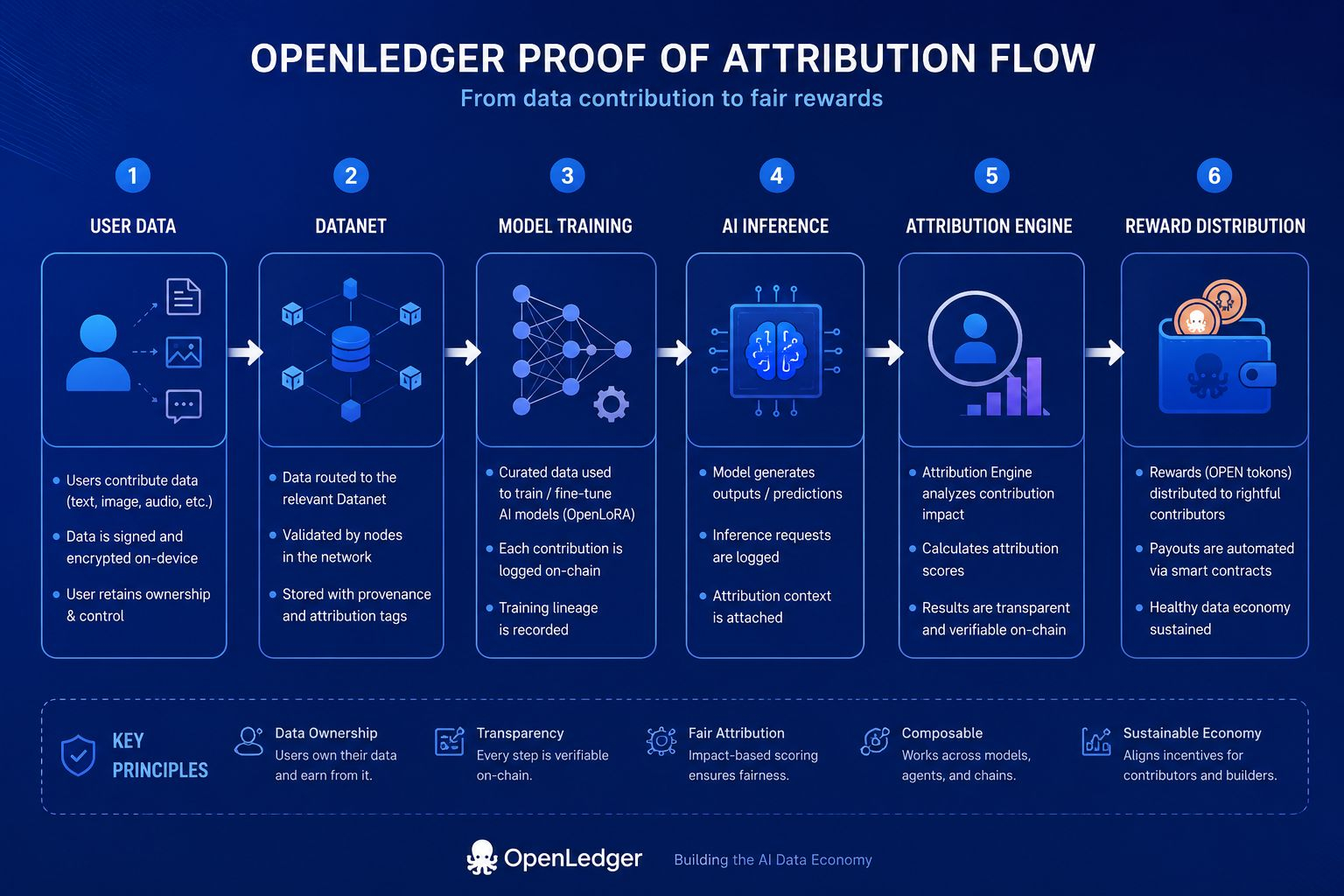
Ramowy system Proof of Attribution protokołu stara się rozwiązać problem, który większość systemów AI celowo ignoruje. Tradycyjne modele pochłaniają informacje, nie zachowując linii wkładu. Gdy zbiory danych trafiają do scentralizowanych kanałów, własność efektywnie znika. OpenLedger próbuje odwrócić tę dynamikę poprzez infrastrukturę opartą na atrybucji, gdzie zbiory danych, dane wejściowe do fine-tuningu, aktywność wnioskowania, agenci AI i wyniki modeli pozostają ekonomicznie śledzone w sieci. W prostym języku, system zadaje pytanie, które wydaje się zaskakująco radykalne teraz: kto tak naprawdę pomógł w produkcji tej inteligencji?
I tu rzeczy stają się technicznie fascynujące.
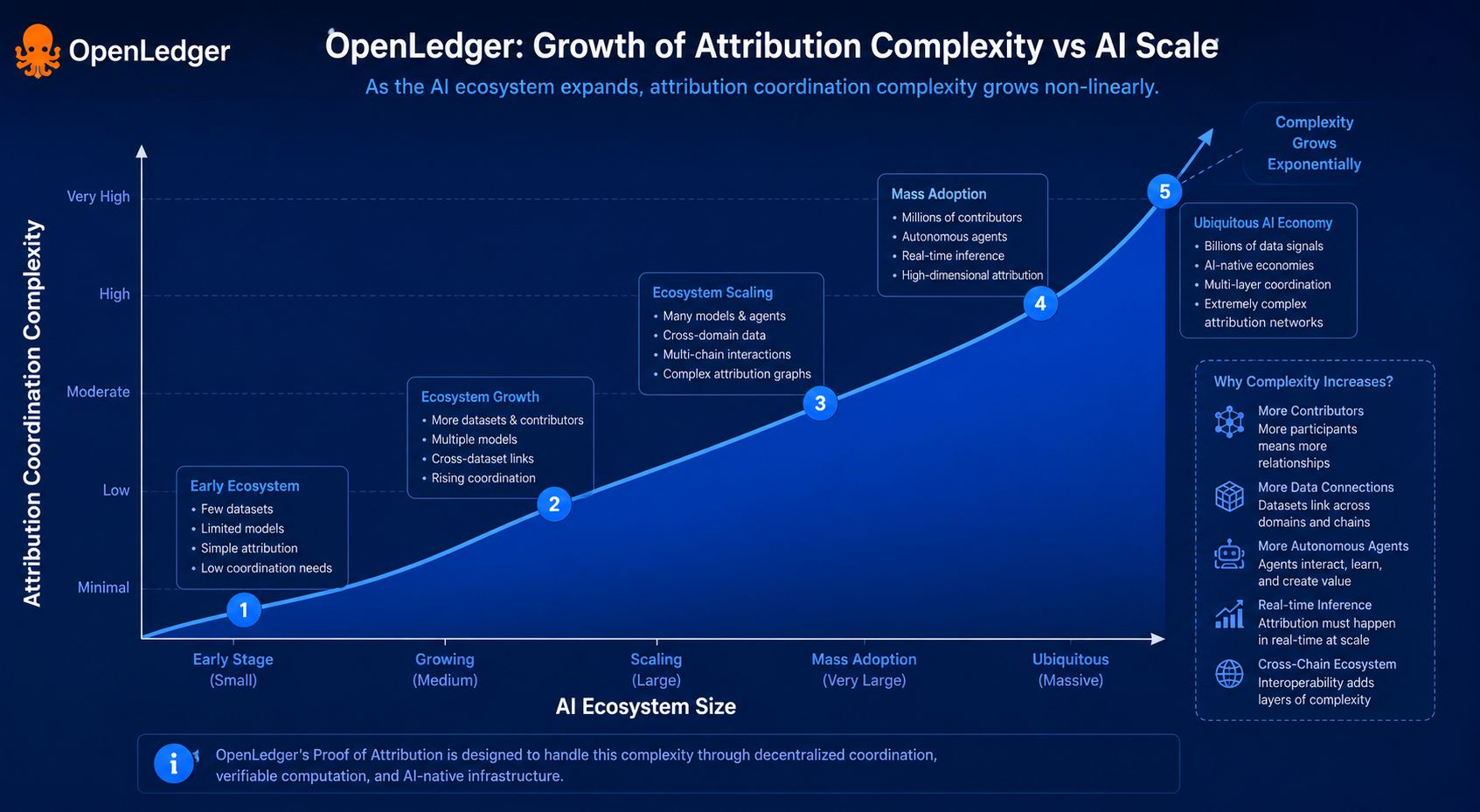
Im więcej badałem Datanety OpenLedger, tym mniej przypominały normalną infrastrukturę blockchainową, a tym bardziej zaczęły wyglądać jak zdecentralizowane gospodarki inteligencji. Każdy Datanet może specjalizować się w unikalnych kategoriach danych i koordynacji AI, jednocześnie nieustannie zasilając przepływy wartości związane z atrybucją w całym ekosystemie. OpenLedger niedawno przekroczył 3 miliony aktywnych węzłów według metryk ekosystemu, podczas gdy koordynacja wnioskowania i wdrożenia OpenLoRA wciąż rozszerzają się w różnych środowiskach wykonawczych. Te liczby zwróciły moją uwagę, ponieważ systemy atrybucji mają znaczenie tylko wtedy, gdy przetrwają skalę operacyjną. Piękne pomysły szybko upadają pod prawdziwą presją wydajności.
Szczerze mówiąc, skalowalność była pierwszą rzeczą, której nie ufałem.
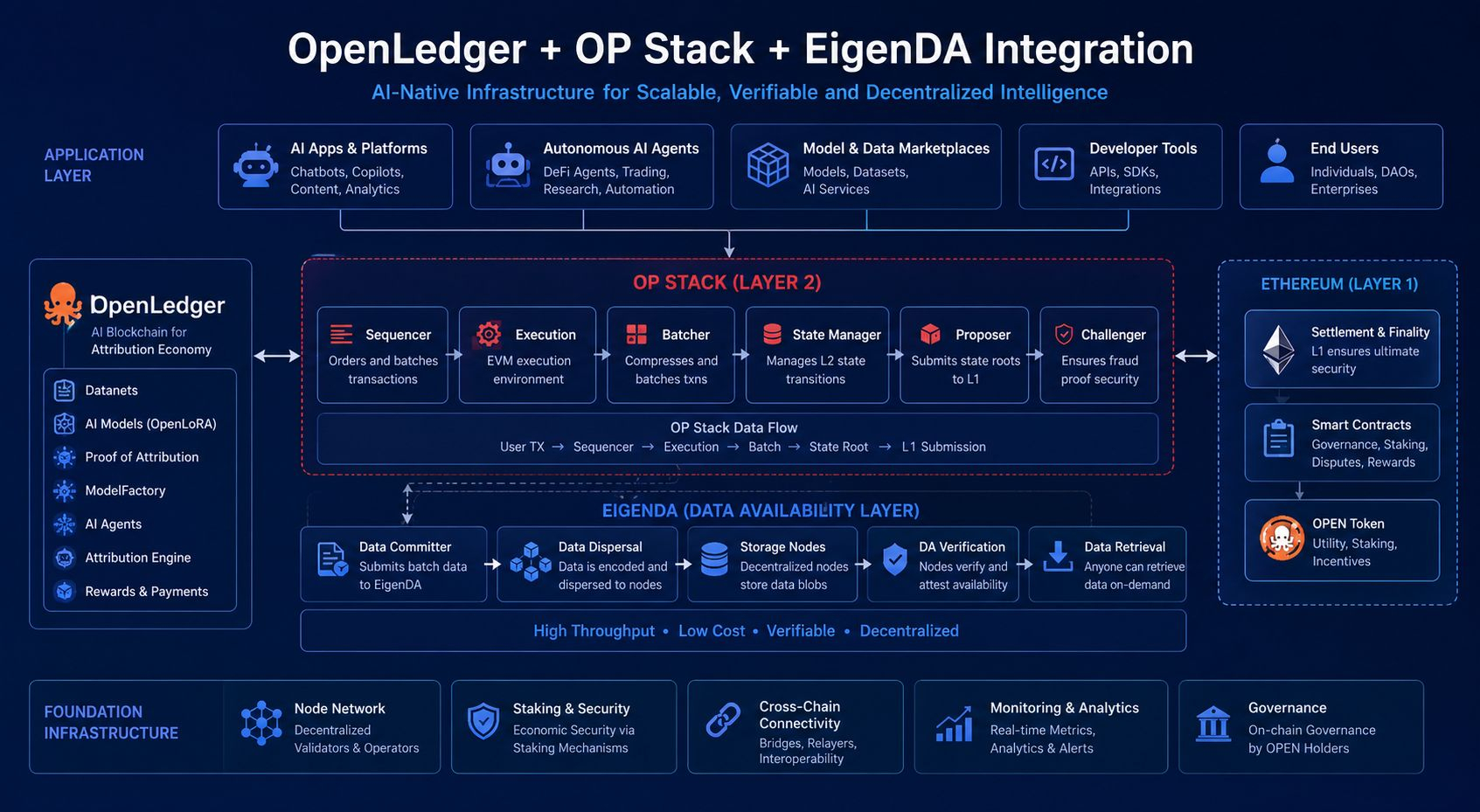
Ponieważ atrybucja brzmi elegancko, dopóki każda interakcja AI nagle nie wymaga warstw weryfikacji, routingu nagród i księgowości wkładów. Złożoność szybko się kumuluje. Pojedynczy wynik generowany przez AI może obejmować dopasowane modele, dostawców wnioskowania, systemy danych w czasie rzeczywistym, koordynację walidatorów i autonomiczne agenty wykonawcze jednocześnie. Architektura OpenLedger wydaje się celowo modułowa, aby zarządzać tą presją. Protokół łączy infrastrukturę OP Stack, dostępność danych wspieraną przez EigenDA oraz systemy interoperacyjności cross-chain, aby zredukować wąskie gardła między obciążeniami AI a warstwami rozliczeniowymi blockchaina. Czytając głębiej w system, przestałem postrzegać go jako kolejną warstwę 2 i zacząłem postrzegać go bardziej jako infrastrukturę operacyjną dla gospodarek maszynowych.
I może to jest prawdziwa historia tutaj.
Większość dzisiejszych systemów kryptowalutowych nadal koncentruje się na efektywniejszym przenoszeniu płynności. Ale AI zmienia naturę produkcji ekonomicznej. Gdy autonomiczne agenty zaczynają podejmować decyzje, wdrażać strategie, analizować rynki i koordynować zasoby niezależnie, inteligencja staje się produktywną infrastrukturą, a nie pasywnym oprogramowaniem. OpenLedger wydaje się zaprojektowane wokół tego założenia. Token $OPEN coraz mniej przypomina spekulacyjny aktyw, a bardziej paliwo koordynacyjne dla walidacji atrybucji, systemów wykonawczych AI, uczestnictwa w Datanetach i interakcji ekonomicznych maszyna do maszyny.
Ale jest inna strona tego, o której nie mogę przestać myśleć.
Im bardziej inteligencja staje się mierzalna, tym bardziej sama własność staje się fragmentaryczna.
Przyszły system AI może polegać na tysiącach rozproszonych mikro wkładów jednocześnie. Ludzkie dane szkoleniowe. Syntetyczne cykle wzmocnienia. Specjalistyczne warstwy fine-tuningu OpenLoRA. Dane finansowe w czasie rzeczywistym. Systemy pamięci autonomicznych agentów. Sygnalizacja wykonania cross-chain. Wdrożenia ModelFactory. Nagle inteligencja nie wydaje się już pojedynczym produktem stworzonym przez jeden podmiot. Zaczyna działać jak ciągle zmieniający się łańcuch dostaw samej kognicji. Atrybucja staje się mniej kwestią autorstwa, a bardziej śledzeniem niewidzialnych relacji ekonomicznych w ramach zdecentralizowanych systemów.
To jest miejsce, w którym pomysł staje się trudny.
Ponieważ sprawiedliwość wprowadza tarcie. Zawsze tak jest. Systemy zoptymalizowane wyłącznie pod kątem wydajności zazwyczaj centralizują się. Systemy zoptymalizowane pod kątem szerokiej atrybucji zwykle stają się operacyjnie cięższe. OpenLedger wydaje się świadome tego napięcia w całym projektowaniu protokołu. Biała księga wielokrotnie podkreśla modułowe routowanie atrybucji zamiast sztywnego egzekwowania własności, prawie tak, jakby sieć rozumiała, że rynki inteligencji pozostaną płynne i adaptacyjne, a nie statyczne. Może się mylę, ale ta elastyczność może stać się konieczna, gdy agenty AI zaczną autonomicznie interagować w różnych łańcuchach i środowiskach wykonawczych jednocześnie.
Wciąż myślę o psychologicznych implikacjach tego wszystkiego.
Internet nauczył ludzi, że dane są jednorazowe. Coś, co wymienia się dla wygody. Ale gospodarki atrybucji mogą całkowicie zmienić tę relację w czasie. Gdy wkładnicy zrozumieją, że ich dane, wzorce zachowań czy specjalistyczna inteligencja mogą generować trwałą wartość ekonomiczną, sama online'owa uczestnictwo może się zmienić. Architektura OpenLedger sugeruje tę możliwość poprzez weryfikowalne kanały danych i systemy wynagradzania związane z atrybucją. Dane przestają zachowywać się jak pasywne odpady i zaczynają działać jak produktywny kapitał.
I szczerze mówiąc, ten pomysł wydaje się zarówno ekscytujący, jak i nieco niepokojący.
Ponieważ przekształcanie inteligencji w aktywa ekonomiczne także niesie ryzyko dalszej finansjalizacji ludzkiego zachowania. Każda interakcja może ostatecznie stać się mierzalna, możliwa do przypisania i monetyzacji w ramach gospodarek maszynowych. Istnieje tu filozoficzne napięcie, które często umyka dyskusjom kryptowalutowym. Systemy atrybucji mogą wzmacniać wkładników, jednocześnie rozszerzając struktury zachęt do nadzoru wokół aktywności cyfrowej. OpenLedger nie rozwiązuje w pełni tej sprzeczności. Nie jestem pewien, czy jakikolwiek protokół potrafi to zrobić. Ale przynajmniej projekt wydaje się gotowy uznać złożoność zamiast udawać, że decentralizacja automatycznie tworzy sprawiedliwość.
Im głębiej wchodziłem w ekosystem, tym bardziej infrastruktura zaczynała przypominać zupełnie nową warstwę koordynacyjną dla rynków natywnych AI. Autonomiczne agenty pozyskujące inteligencję z Datanetów. Systemy wykonawcze cross-chain interagujące z modelami świadomymi atrybucji. Wdrożenia OpenLoRA specjalizujące się w zachowaniach rynkowych w czasie rzeczywistym. ModelFactory umożliwiające ciągłe dostosowywanie zarządzania cyklem życia AI. Czuję, że to mniej przypomina powstawanie kolejnej aplikacji kryptowalutowej, a bardziej obserwację wczesnej architektury ekonomicznej kształtującej się wokół samej inteligencji maszyn.
I może dlatego ten eksperyment pozostał w mojej głowie dłużej, niż się spodziewałem.
Ponieważ OpenLedger cicho zmusza do większej rozmowy w kontekście narracji AI. Nie tylko jak potężna staje się sztuczna inteligencja, ale czy sama inteligencja może pozostać ekonomicznie odpowiedzialna, gdy autonomiczne systemy skalują się globalnie. To pytanie sięga daleko poza rynki kryptowalutowe. Dotyka własności, pracy, koordynacji, zarządzania, a nawet tożsamości ludzkiej w ramach cyfrowych gospodarek coraz bardziej kształtowanych przez rozumowanie maszyn.
Dziwne jest to, jak wszystko wciąż wydaje się bardzo wczesne.
Obecnie większość ludzi interakcjonujących z systemami AI ledwie myśli o infrastrukturze atrybucji pod powierzchnią. Zależy im na wynikach. Szybkości. Wygodzie. Ale infrastruktura zawsze ma znaczenie w końcu. Najpierw cicho. Potem nagle wszystko naraz. Chmura działała w ten sposób. Centra danych działały w ten sposób. Warstwy rozliczeniowe blockchaina działały w ten sposób. Gospodarki atrybucji mogą podążać tą samą ścieżką, aż pewnego dnia ludzie zdadzą sobie sprawę, że systemy produkujące inteligencję stały się tak samo ekonomicznie ważne, jak sama inteligencja.
I może latami z teraz, gdy autonomiczne agenty AI koordynują przepływy wartości w zdecentralizowanych sieciach bez bezpośredniego nadzoru ludzkiego, prawdziwe pytanie historyczne nie będzie brzmiało, czy udało nam się zbudować potężne AI.
Może chodzi o to, czy pamiętaliśmy, aby wbudować pamięć ekonomiczną w warstwę inteligencji, zanim gospodarki maszynowe stały się zbyt duże, by ktokolwiek mógł je sensownie śledzić.