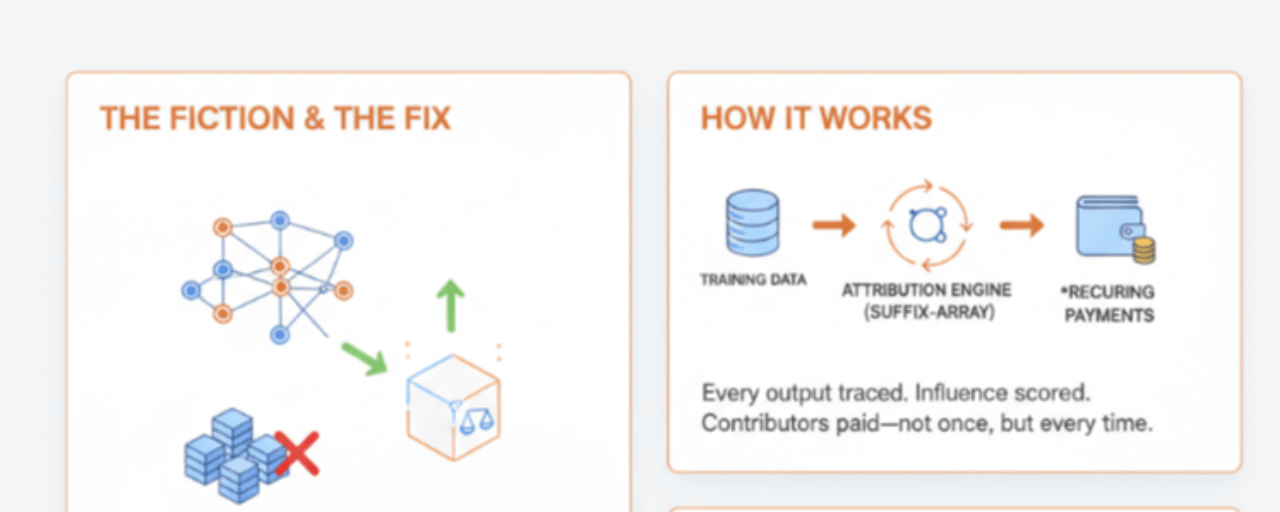

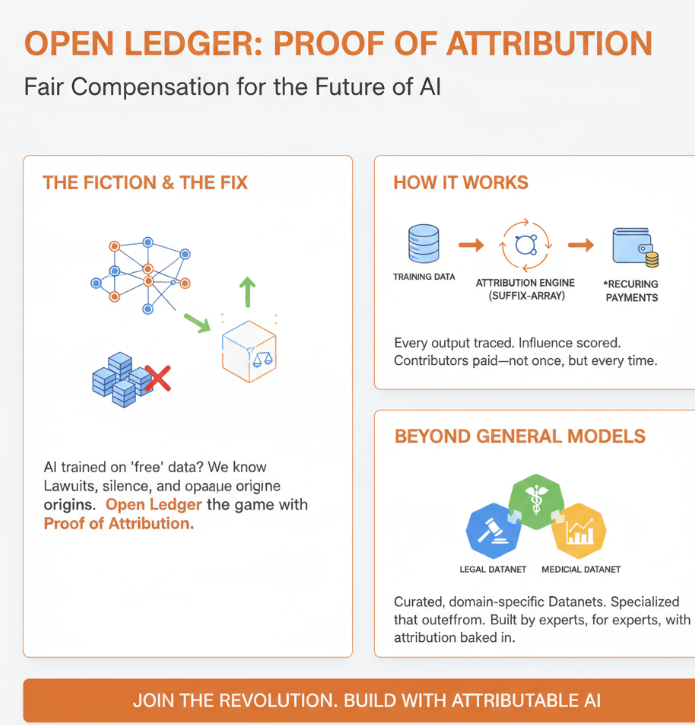
I've been thinking about this for a while and I keep coming back to the same conclusion. The entire AI industry has been running on a kind of polite fiction. The fiction is that training data is either free, public domain, or properly licensed, and that the people whose work shaped these models are either compensated already or don't really matter. Everyone in the industry knows this isn't true. The lawsuits make it obvious. The silence from major AI labs on the question of training data provenance makes it obvious. The fact that nobody can actually show you where a specific model output came from makes it extremely obvious.
Proof of Attribution, which is what Open Ledger built into its core protocol, is the first serious technical answer to that fiction that I've actually seen deployed at infrastructure level rather than just described in a research paper.
Here's what it actually does. When a model trained on Open Ledger's network produces an output, the system can trace which parts of the training data influenced that output using suffix-array based token attribution. That's not a simple thing to build. It checks the model's outputs against compressed training corpora to detect what was memorized and what was genuinely synthesized. The influence score that comes out of that process becomes the basis for actual payments to the contributors whose data drove the result. Not a flat fee for uploading. Not a one-time payment. A recurring attribution every time your data does something useful.
That distinction matters more than it probably sounds. Most people who contribute data to AI projects currently get nothing at all. The more generous arrangements offer a one-time compensation for access. What Open Ledger's model does instead is treat data contribution more like intellectual property that keeps generating value over time. If your specialized knowledge shaped a model that's answering thousands of questions, you get a share of that activity indefinitely.
I think the reason this doesn't get more attention is that most of the conversation around AI and crypto focuses on the agent side, the token price side, or the infrastructure side in terms of raw compute. The data ownership layer feels less exciting until you realize it's actually the load-bearing part of the whole structure. Without clean, attributable, fairly compensated training data, every AI model that gets built on this infrastructure has a legal and ethical question mark hanging over it. With it, builders get something they currently can't find anywhere else: a training pipeline they can actually defend.
The Attribution Engine update that shipped in January 2026 made this even more significant by ensuring that data-output links stay intact even as models are updated and fine-tuned over time. That's the part that really got me. Models aren't static. They evolve. Old attribution systems would lose the thread every time a model iteration happened. Open Ledger's approach keeps the attribution chain continuous regardless of how the model changes after initial training. That's genuinely difficult to do and the fact that it works means contributors don't get cut off from earnings just because the model they helped train got better.
I'm not saying this is a solved problem across every edge case. It isn't. But it's the most honest structural attempt at solving it that exists right now and for anyone who's been watching the AI training data situation with any level of concern, that matters.
Now layer domain-specific Datanets on top of this and the picture gets even more interesting.
The assumption most people bring to AI training is that more data is always better. That's been the dominant paradigm for a while. Bigger datasets, larger scrapes, more tokens. General models trained on essentially everything produced impressive generalist results and for a while that seemed like the whole game. But anyone who's actually tried to use a general-purpose model for specialized professional work has run into the ceiling. Legal analysis, medical diagnostics, financial modeling. These aren't tasks where knowing a little about everything gets you where you need to go. They need models that have been trained on the right data, curated by people who understand the domain, and fine-tuned against standards that a general internet scrape can't provide.
Open Ledger's Datanet system is specifically designed for this. Instead of one giant pool of everything, Datanets are curated, domain-specific data pools that contributors build and maintain. A legal Datanet contains case law, contract structures, regulatory frameworks, and the kind of judgment-heavy language that comes from practitioners who understand what matters. A medical Datanet contains clinical notes, research literature, and diagnostic reasoning patterns that a general model has never been exposed to with any depth. A financial Datanet contains the kind of market structure analysis, risk modeling language, and institutional logic that simply doesn't exist in the volume or quality needed on the open web.
The specialized language models that get trained on these Datanets outperform general models on domain tasks by a margin that isn't close. This isn't a theoretical claim. It's the reason every serious enterprise AI deployment I've seen is moving toward fine-tuned specialized models rather than raw GPT calls. The question was always where the high-quality domain-specific training data comes from and who has any incentive to curate and maintain it. Open Ledger's attribution system answers both parts of that question simultaneously. The data comes from practitioners who know the domain. They have incentive to contribute and maintain quality because they get paid every time that data drives a useful output.
For industries like legal, medical, and finance this combination is significant enough that I think it changes the build vs buy calculation for AI products in those sectors. Right now most enterprise AI teams are either scraping whatever they can find or paying large sums for proprietary datasets with unclear provenance. Open Ledger's model offers a third option that has attribution built in, quality incentives built in, and a compliance story that the first two options simply don't have.
