been going through openledger’s architecture docs and a few technical breakdowns, mostly focused on how they connect ai data flows to on-chain coordination. what caught my attention is that they’re not only building a decentralized dataset layer — they’re trying to build economic traceability around the data itself. meaning: if a model uses some dataset, the protocol should theoretically know enough to route rewards back to contributors over time.
that sounds clean conceptually. in practice, honestly, it feels like the entire system depends on whether attribution can survive contact with real-world ai workflows.
most people think openledger is just another ai + crypto token where contributors upload data and earn rewards. but the architecture is actually making a bigger assumption: that future ai development will rely on open, composable data markets instead of mostly private pipelines. i’m not fully convinced that assumption is wrong, but it’s a pretty important one.
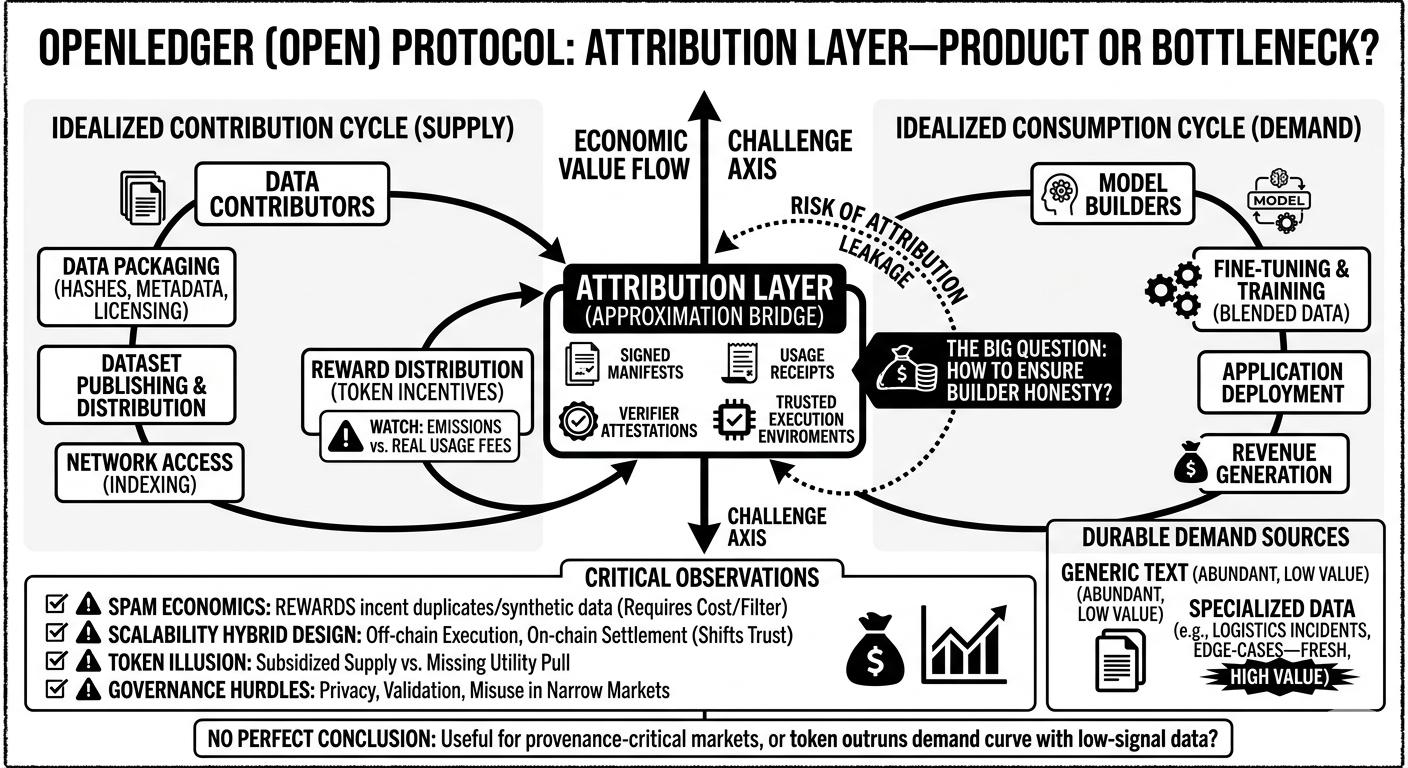
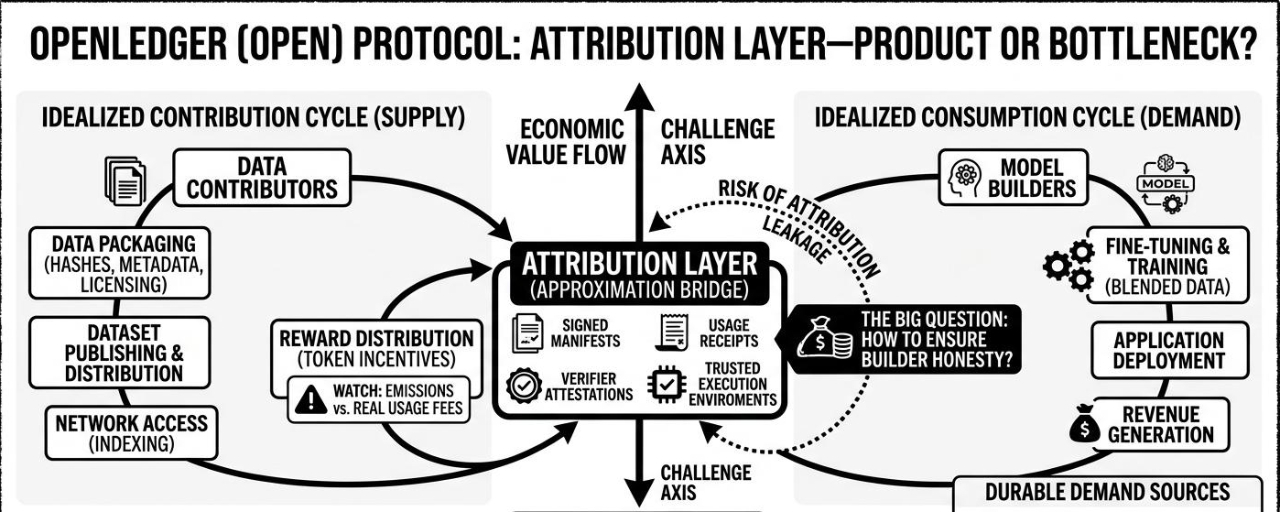
the decentralized data contribution system is probably the easiest part to understand. contributors package datasets with hashes, metadata, licensing info, maybe version history. the protocol indexes and distributes them across the network. straightforward enough. the difficult part is quality control. if rewards are tied to uploads, spam becomes economically rational almost immediately. synthetic datasets, duplicated corpora, slightly modified versions of existing samples — all of that will show up fast unless publishing has some cost or filtering mechanism.
and this is the part i keep thinking about… attribution. openledger seems to position attribution as the bridge between ai and crypto economics. but training attribution is messy by default. once a model trains on blended datasets, the influence of individual contributions becomes hard to isolate. so the protocol probably relies on approximations: signed training manifests, usage receipts, verifier attestations, maybe trusted execution environments eventually. but none of those fully solve the “how do we know the builder is telling the truth?” problem.
there’s also the marketplace layer sitting on top of this. the ideal flow is obvious: contributors provide data → model builders consume it → applications generate revenue → rewards flow backward through the attribution graph.
but i keep wondering where the durable demand starts. generic text datasets are abundant already. the more believable market is specialized data that changes frequently or requires domain expertise. imagine a logistics company fine-tuning a routing model using real warehouse incident reports and edge-case delivery logs. that data has actual operational value because it’s fresh and hard to source publicly. openledger could coordinate those contributions better than a closed platform in theory, especially if contributors want transparent compensation. but then you inherit all the hard governance problems around privacy, validation, and misuse.
the token incentive layer is where things get murkier for me. open is supposed to coordinate participation across contributors, validators/verifiers, maybe model operators too. but token emissions can create a weird illusion of demand. you can have lots of “activity” on the network without meaningful buyer-side pull. this happens in a lot of crypto infrastructure projects: supply gets subsidized long before utility exists.
the scalability question matters too. ai workflows generate huge amounts of off-chain computation. openledger can’t realistically verify every training step or inference call directly on-chain. so the network design ends up hybrid almost by necessity: off-chain execution, on-chain commitments and settlement. that’s probably fine, but it means trust shifts toward whoever controls the verification layer.
who actually creates value here? contributors create optionality, not guaranteed value. builders create products and revenue, but they’re also the easiest place for attribution leakage to happen. so the protocol implicitly assumes honest reporting becomes economically preferable to cheating. maybe through staking, audits, reputation, or buyer expectations around provenance. still feels unresolved.
watching:
percentage of rewards funded by actual usage fees vs token emissions
repeat dataset buyers instead of one-time incentive-driven experiments
spam/dispute rates on contributed datasets
whether attribution verification stays lightweight or becomes operationally expensive
no perfect conclusion yet. i can see openledger becoming useful for narrow, high-value data coordination markets where provenance actually matters. but i can also see a future where the token incentives outrun the real demand curve and the network fills with low-signal contributions.
the open question for me is still pretty simple: once the incentives normalize, what genuinely forces model builders to keep participating honestly in the attribution system instead of routing around it entirely?