
When I first came across the idea of @OpenLedger turning raw data into “liquid assets,” I kind of brushed it off as one of those AI-blockchain phrases that sounds cleaner than it probably is in practice. But the more I sat with it, the more it stopped feeling like a slogan and started looking like a very specific attempt to solve something crypto has struggled with for years: how to price data without pretending it behaves like a normal asset.
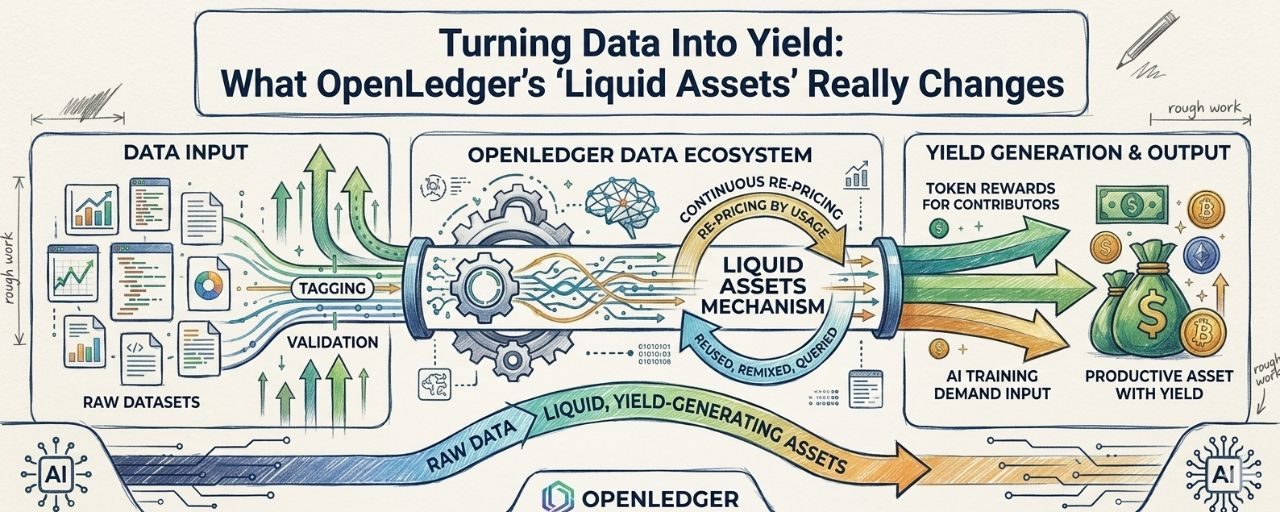
The core mechanism, at least the way I’m piecing it together, seems to be this loop where data stops being a static input and becomes something closer to a yield-generating object. Raw datasets get contributed, tagged, sometimes validated, then exposed to AI training demand. And instead of just selling access once, the system tries to keep that dataset “active” — reused, remixed, queried — with each interaction feeding back into some form of reward distribution.
It’s less like storing data and more like continuously re-pricing its relevance through usage.
I’m not sure OpenLedger implements it exactly like this… but structurally it rhymes with what we’ve seen in other data liquidity designs.
It reminds me a bit of Ocean Protocol experiments and even parts of Bittensor, though the framing is different. In those systems, the incentive design quietly shifts from “own data” to “prove your data is useful in a networked context.” That shift is subtle but important. Because once usefulness becomes measurable, you can start attaching token flows to it. And once token flows exist, data stops being just data — it becomes something closer to a productive asset with yield expectations.
Weirdly, this is where things start to feel a bit fragile. Because the moment you financialize usefulness, you also invite reflexivity. People don’t just submit data because it’s valuable — they start optimizing for what the network rewards. I think we saw a version of this in early liquidity mining cycles around 2021 DeFi protocols, where “participation” became indistinguishable from “farming behavior.” Not the same thing here, but the behavioral loop feels familiar.
Market context matters here more than it should. AI tokens already had their narrative explosion when compute scarcity and GPU markets dominated attention. Then liquidity rotated, as it always does, back toward BTC strength and macro-driven flows — ETF inflows, rate expectations, risk-off phases bleeding alt liquidity. In those conditions, infra-heavy experiments like data markets tend to either quietly build or lose attention entirely. So systems like OpenLedger are kind of living in that in-between state where the narrative is strong, but sustained capital rotation isn’t guaranteed.
What stands out to me is the implied assumption: that data can behave like liquidity if you wrap it in enough coordination layers. Token incentives for contributors, maybe staking or validation layers for quality, and demand-side consumption from AI agents or model builders. On paper, it creates a closed loop. Data enters, gets priced through usage, and exits as rewards. But I keep wondering where the leakage is.
The entire system only works if external demand for model training grows faster than the network’s ability to manufacture ‘useful-looking’ data internally — otherwise liquidity becomes self-referential instead of real.
Because every time crypto builds a “closed loop,” it usually turns out there’s an open door somewhere — either in pricing oracle assumptions, or in how usage is measured, or just in human behavior gaming the incentives.
Maybe I’m overthinking it, but the interesting part isn’t whether data becomes liquid. It’s whether liquidity here is real or just simulated through repeated internal recycling. Like, if the same dataset is constantly reused inside a narrow AI ecosystem, does it actually gain value… or just circulate value already assigned elsewhere?
I think I saw something loosely similar during the early AI compute narratives in 2023, where “utilization” was treated as value creation, even when marginal utility started flattening. Could be a different case here though.
Still, I can’t shake the question of what happens when demand slows. If token incentives keep data flowing in, but model training demand doesn’t scale at the same pace, does the system start overpricing its own internal activity?
Feels efficient on the surface… but I’m not fully convinced I understand where the real liquidity anchor is when external demand shifts.
