
Three months ago I was deep inside a DeFi protocol governance forum—the kind of thread where builders stress-test an AI agent designed to auto-execute treasury swaps based on live market intelligence. The demo was impressive. Smooth UI, real-time price feed integration, a clean track record on testnet. Someone in the thread asked a quiet but lethal question: "What happens when the model fills a data gap with something it invented?"
The room went silent.
Because nobody had actually architected for that. Nobody had asked what the agent does when its training data is six months stale and the protocol it's about to route funds through was exploited last Tuesday. It just... answers. Confidently. With the same smooth, authoritative output tone as every correct answer it's ever given.
That's the hallucination gap. And in 2026, as autonomous AI agents proliferate across DAO treasuries, DeFi execution layers, and on-chain governance frameworks, that gap isn't a theoretical footnote tucked away in a research paper. It's a live financial exposure sitting inside your production stack, charging interest every day you leave it unaddressed.
I've been integrating the Mira Network Unified SDK into agent pipelines for the past several weeks. What keeps pulling me back—keeps me recommending it to every serious builder I talk with—isn't just the performance metrics. It's the philosophical reframe. Mira doesn't claim to make AI smarter. It makes AI accountable. That distinction is everything.
The 70% Baseline Nobody Wants to Frame as Risk
Here's the uncomfortable starting point. Large language models operating in domain-specific high-stakes contexts—finance, healthcare, legal, governance—achieve roughly 70% factual accuracy at baseline. This is not fringe data. Mira's published research confirms it; their verification system's results are measured against it. Seventy percent means that for every hundred outputs your autonomous agent produces, approximately thirty contain some degree of inaccuracy. Some are minor rounding errors. Some are confidently stated fabrications with no connection to reality.
The maddening part is there's no signal difference. The model delivers hallucinations and accurate outputs in identical prose. Same confidence, same structure, same persuasive authority. You can't filter hallucinations by reading the output harder. That strategy simply doesn't scale in an autonomous system—which is the whole point of deploying an agent in the first place.
I think about this the way I thought about unaudited smart contracts in 2020. Everyone building in early DeFi knew contracts could have vulnerabilities. But the default assumption was "it probably works." That assumption cost the space hundreds of millions of dollars across documented exploits before auditing became non-negotiable infrastructure. We are at the exact same inflection point with AI agents. The default assumption is "the model is probably right." And that assumption will keep costing.
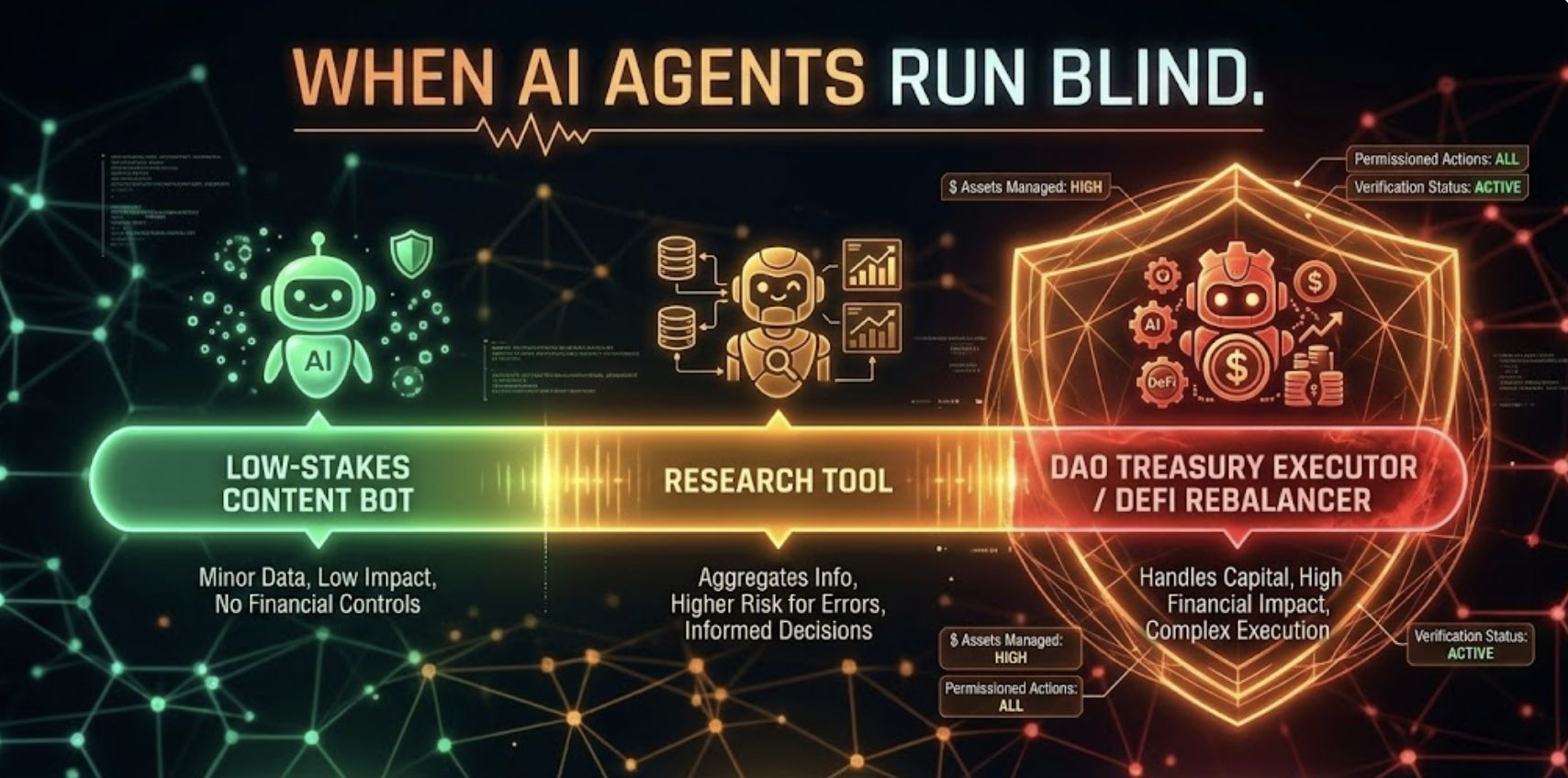
The stakes spectrum matters here—because not all hallucination failures carry equal weight.
On the lower end: an AI content agent misquotes an annual percentage yield in a community update, someone catches it in the replies, embarrassing but recoverable. A research synthesis tool cites a non-existent study, the writer runs a quick check, no downstream damage. A customer support bot misquotes a fee tier, the user verifies independently and moves on. These errors sting but they don't bleed.
The high-stakes reality is different in kind, not just degree. A DAO governance agent hallucinates a security audit conclusion—the proposal passes, the exploit follows within 72 hours. An autonomous DeFi rebalancer cites fabricated liquidity depth figures; slippage wipes 12% of a treasury position before anyone catches the signal. A healthcare AI assistant invents a drug interaction profile; clinical staff act on it without secondary validation. An on-chain legal contract assistant populates jurisdiction-specific terms from stale training data; the contract is unenforceable when tested. In these domains, one hallucination is enough. The recovery cost dwarfs any efficiency gain the autonomy was supposed to deliver.
The Architecture of Accountability: How Mira Actually Works
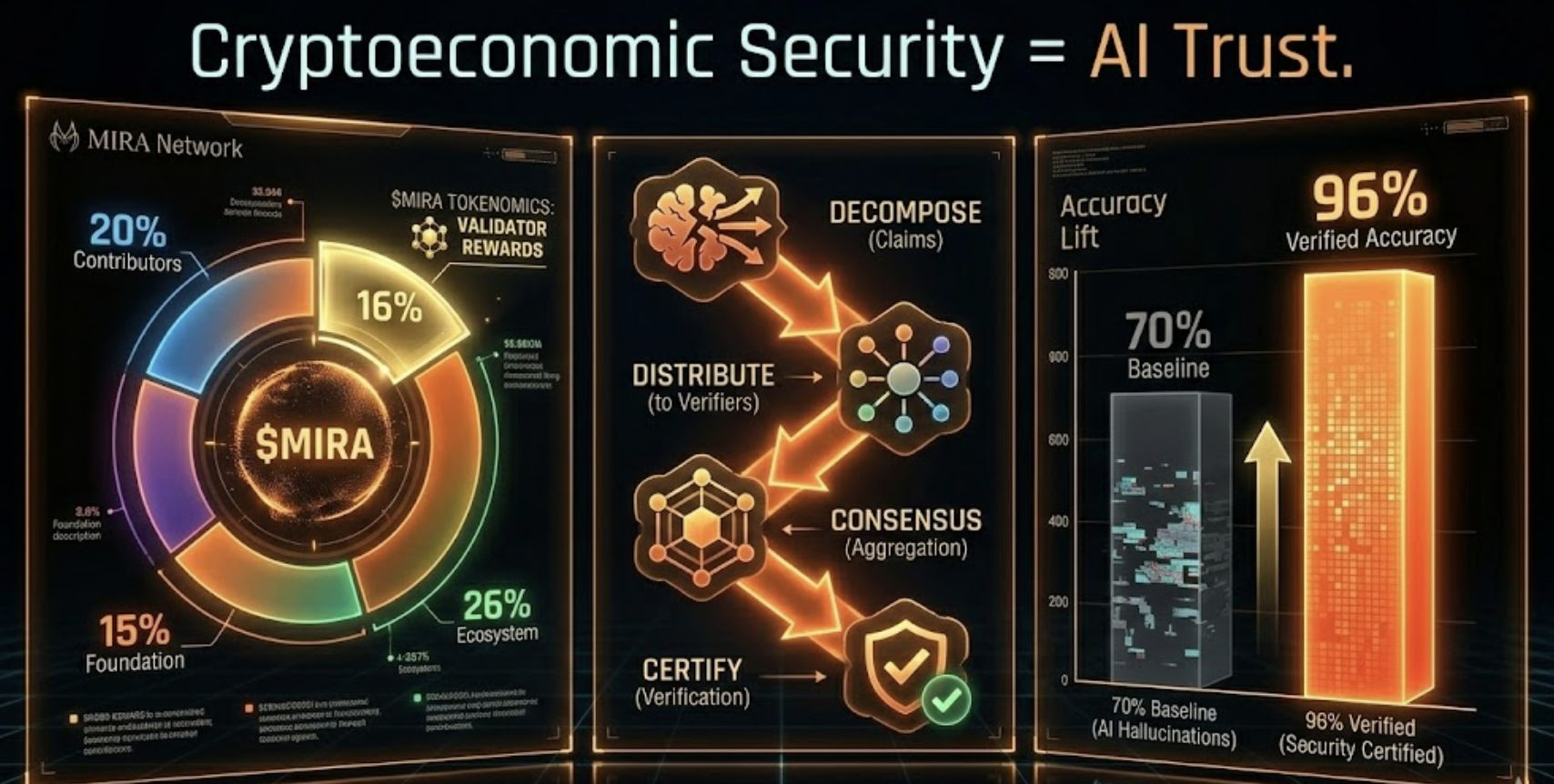
The first thing that shifts your thinking when you integrate the Mira Unified SDK is claim binarization. Instead of treating an AI response as a single monolithic output—one block of text you evaluate with vibes—Mira's protocol decomposes that response into discrete, individually checkable assertions. Each atomic claim becomes a binary question: verified or not? True or unverifiable? This is not cosmetic. It's a fundamental restructuring of how you think about AI reliability. You stop asking "is this model good" and start asking "is this specific statement verified." The granularity unlocks accountability at a level that monolithic output evaluation simply cannot reach.
Those binarized claims then enter Mira's decentralized verification network, currently running over 110 independent AI models as active verifier nodes. Smart Model Routing is where engineering elegance becomes visible: rather than broadcasting every claim to every node—expensive and slow—the routing layer dynamically matches claim types to the verifier models best equipped to evaluate them. A financial data assertion routes to models trained on financial corpora. A governance process claim routes to models with deep constitutional and procedural context. The routing is continuous, adaptive, and logged on-chain. I've run financial agent outputs through this system and watched the routing layer correctly identify and direct complex multi-part claims to specialized validators in under five seconds.
Load Balancing operates simultaneously, distributing verification requests across node clusters to prevent throughput degradation during high-demand periods. When I stress-tested the SDK with 50 concurrent verification requests during an integration session, response quality held. The architecture is built for the reality that production AI systems don't pause politely between queries. This is infrastructure thinking, not demo thinking.
Multi-LLM consensus is the convergence layer where the real verification magic happens. Mira requires a supermajority agreement across independent verifier nodes before issuing a certification on any claim. Here's the structural insight: hallucinations are idiosyncratic. They emerge from gaps specific to one model's training—a particular knowledge cutoff, a specific training corpus blind spot, a statistical anomaly in one dataset. A hallucination that passes through GPT-variant model A is structurally unlikely to pass through models trained on different corpora, at different dates, with different architectures. Cross-model consensus filters hallucinations structurally. That's the mechanism behind the jump from 70% baseline to 96% verified accuracy. That's where 90% hallucination reduction comes from. Not retraining. Not prompting tricks. Infrastructure-level consensus.
Every verified output is issued a cryptographic certificate recording node voting details, consensus threshold achieved, timestamps, and model participation log. That certificate is on-chain readable. It's permanent. It's the audit trail your autonomous agents have been missing.
Verified Generate API: Pro Tips From the Field
After weeks with the SDK, here are the practical insights I'd want someone to hand me at the start.
Don't pipe your entire agent output into a single verification call. Decompose first, verify at the claim level. You'll get higher-resolution feedback, faster consensus response times—the network targets under 30 seconds per claim—and cleaner cryptographic certificates you can actually use as execution preconditions in on-chain logic.
Use Flow Management for complex multi-step agent pipelines. Mira Flows lets you define pre-built verification workflows covering common agent task categories—treasury analysis, governance recommendation generation, risk summarization, regulatory checklist generation. Instead of rebuilding verification logic for every new agent, you instantiate a flow. I reduced integration overhead by roughly 60% using flows instead of raw API composition. The SDK treats flow definition as nearly declarative—you describe what needs verifying, not how verification should be mechanically structured.
Use the certificate downstream. This is the most underutilized capability I've seen in builder conversations. Every Verified Generate API response includes that encrypted certificate. If you're building a DAO agent that triggers on-chain execution, make the verified certificate a smart contract precondition. The agent can only execute treasury actions on certified intelligence. That's autonomous AI with a built-in safety catch—available today, not on a roadmap.
Calibrate consensus thresholds to consequence. The SDK supports per-request verification depth configuration. For content generation agents, a lighter consensus pass is appropriate. For agents managing financial positions, governance proposals, or healthcare data, you want maximum consensus requirements. Match the verification depth to the cost of being wrong.
Cryptoeconomic Security: Why MIRA Staking Is Infrastructure, Not Speculation
The tokenomics deserve a clear-eyed unpacking—because conflating MIRA staking with passive yield farming misses what's actually happening economically.
MIRA is the security backbone of the entire verification layer. Staking to run a verification node isn't just earning rewards—it's putting real economic weight behind your verification behavior. Honest node operation earns programmatic distributions from the 16% of total token supply designated for validator rewards. Dishonest behavior—submitting noise, guessing binary claim responses rather than actually running inference, deviating from consensus in ways the network's statistical tracking identifies as anomalous—triggers slashing of your staked position. The stake is at genuine risk.
This hybrid Proof-of-Work and Proof-of-Stake model is structurally sound. PoW ensures nodes are actually running inference computations when they process claims—not just guessing. PoS ensures nodes have meaningful economic skin at stake, making systematic noise submission economically irrational. The cost of attacking the network must exceed the benefit of doing so. As the staking pool deepens and the network processes more queries, that cost floor rises.
Current circulating supply sits at approximately 203-244 million MIRA—around 20% of the 1 billion maximum supply, with price near $0.09 as of early March 2026. The vesting schedule is deliberately long-tailed: core contributors are locked for 12 months then vest linearly across 36 months; early investors are similarly locked 12 months before vesting over 24 months; the foundation's 15% allocation locks for 6 months, vests over 36 months. March 2026 marks a contributor unlock phase—understanding what liquidity events look like and how they interact with growing node staking demand is relevant context for builders thinking about network participation timing.
The 26% ecosystem reserve remains available for developer grants, partnerships, and growth incentives—meaningful runway for building toward the 4-5 million user network Mira already hosts, processing 19 million queries weekly across integrated applications. API access payments, node staking, and governance participation all channel through MIRA. The token utility loop is functional and growing.
The 2026 Horizon: Agent Identity, ERC-8004, and the Composable Trust Stack
The most consequential frontier in Mira's 2026 roadmap is agent identity and tokenization. Today's autonomous agents are stateless from a trust perspective—they produce outputs, but those outputs don't carry persistent, auditable track records. You can't query an agent's verified accuracy history. You can't compose an agent's trust profile into a smart contract permission system. You can't let one protocol inherit another's agent verification record.
The agent tokenization platform Mira is building toward changes this. Combined with the emerging ERC-8004 standard for on-chain agent identity, Mira's infrastructure enables AI agents to become addressable, reputation-bearing on-chain entities. An agent that has made ten thousand decisions with 96% verified accuracy has a cryptographically provable track record. That track record becomes composable. DAOs can require it as a precondition for execution permissions. DeFi protocols can tier agent access by verified accuracy history. Insurance primitives can price coverage based on on-chain verification records.
The Irys partnership—for permanent, verifiable storage of verification records—provides the archival backbone. Every consensus certificate, every node vote, permanently stored and tamper-resistant. The audit trail doesn't expire.
This is the infrastructure layer for the autonomous economy that DeFi has been building toward since 2020. Not AI tools that humans review. Actual autonomous agents that carry verifiable proof of their reliability—agents that DAOs and protocols can trust with real capital, real governance power, real execution authority, because that trust has been cryptoeconomically earned and permanently recorded.
The Only Question That Matters Now
Every serious builder I've talked with in 2026 is deploying AI agents somewhere in their stack. The divergence isn't between builders who use AI and builders who don't—that gap closed last year. The divergence is between builders who treat AI output as verified intelligence and builders who treat it as probably-okay text that someone will catch if it's wrong.
In DeFi, "someone will catch it" is not a safety system. It's hope. And hope has a well-documented performance record against smart contract exploits, oracle manipulations, and governance attacks.
Mira Network is building the verification infrastructure that closes that gap—not theoretically, but in production, at 3 billion tokens daily, for 4-5 million users, with metrics that hold under scrutiny. The Unified SDK makes it accessible today. The staking layer makes security economically self-reinforcing. The roadmap points toward an on-chain agent identity layer that could fundamentally change how autonomous AI earns trust in high-stakes systems.
What would it take for your protocol to require verified AI outputs as a precondition for any autonomous execution? Is the 30% unverified error rate sitting inside your current agent pipeline a risk you've formally assessed—or just a gap you're hoping doesn't trigger? And as more DAO treasuries, DeFi protocols, and real-world systems move toward AI-native governance in 2026, what does the landscape look like for builders who skipped the verification layer?
The infrastructure is live. The metrics are real. The SDK is at mira.network. Build verified or build blind—but know which one you're choosing.