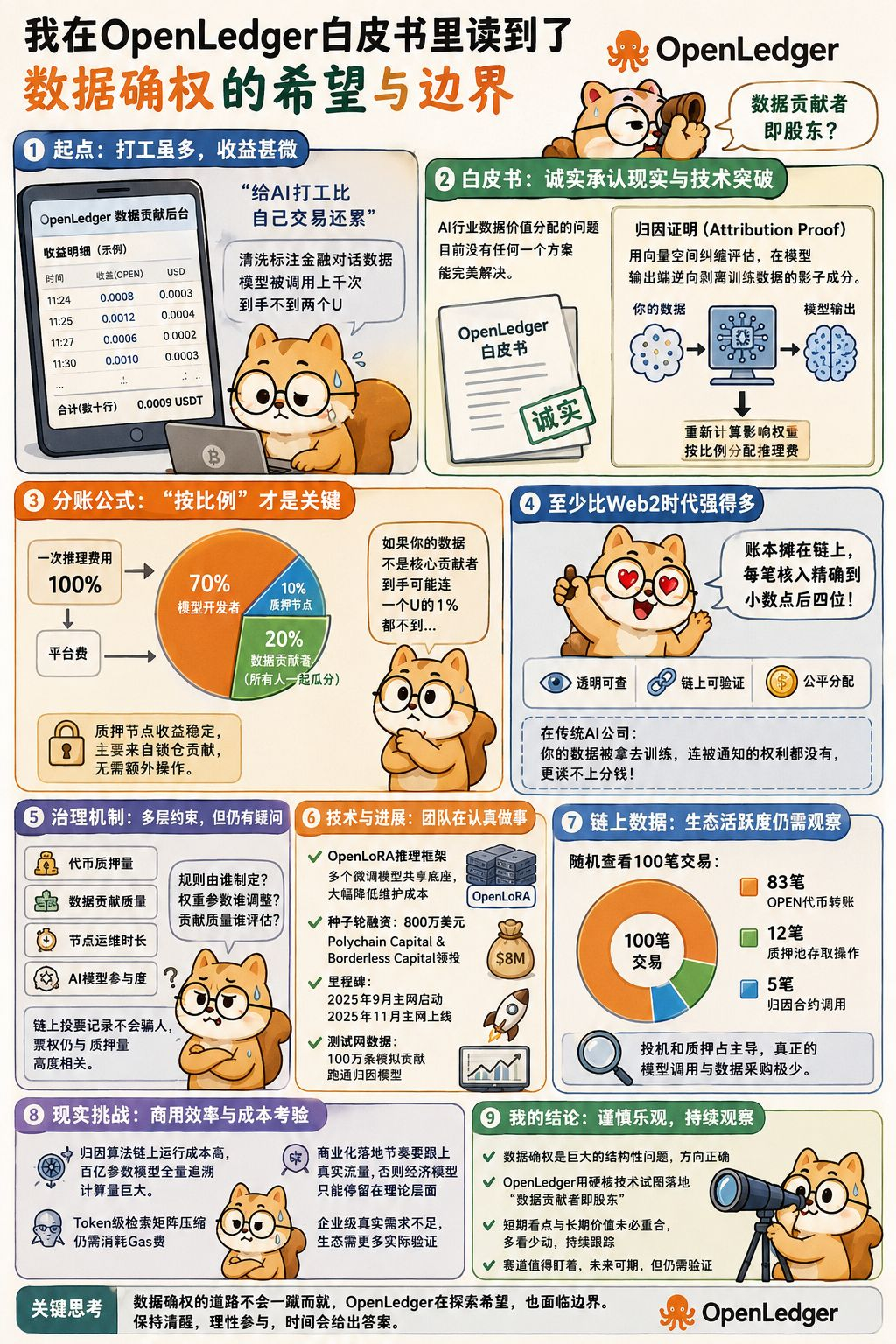
我那个做量化的朋友老陈,上周在群里甩了一张截图,配文写着“我给AI打工比自己交易还累”,我点开一看是OpenLedger的数据贡献后台,收益面板密密麻麻几十行,每笔收入都精确到小数点后四位,可加起来还不够他在高档商圈吃顿简餐。老陈这人我太了解了,他对小数点后四位有种近乎偏执的敏感,能让他专门发个截图吐槽,那数字肯定不是一般的难看,他后来说自己花了三个周末清洗标注了一批金融对话数据,结果模型被调用了上千次,到手不到两个U。我盯着那张截图看了很久,脑子里冒出一个以前不太愿意深想的念头:那些铺天盖地的“数据资产化”叙事底下,普通人的真实处境到底如何,这个问题值得每个人自己掂量掂量。
这个疑问后来把我拽进了OpenLedger白皮书,翻来覆去读了好几遍,坦白讲这份技术文档写得比市面上九成以上的项目都要诚实,因为它没有用那些“彻底重构AI生产关系”之类的宏大词汇来撑场面,反而在第一页就承认了一个很现实的问题:AI行业数据价值分配的问题,目前没有任何一个方案能完美解决。我欣赏这种克制,但也因此比平时多留了几个心眼。
@OpenLedger 归因证明这套机制从技术原理上看确实有两把刷子,用向量空间纠缠评估的方式在模型输出端逆向剥离训练数据的影子成分,这个思路我琢磨了两遍之后觉得它听起来像是把机器学习领域的Shapley值搬到了链上做实时结算。白皮书里用了一个比喻,说用户提交的数据在链上有唯一标识,每次有人调用基于该数据训练的模型,系统都会重新计算这批数据对本次推理输出的影响权重,然后按比例把推理费打到用户账户,这个设计本质上不再是计件打工的逻辑,更像是一种持股分红的思路,只要数据在被调用收益就会持续产生。
不过在我算完账之后发现,“按比例”这三个字才是整个故事里最需要仔细推敲的地方。我后来对着白皮书里的分账公式认真算了一笔账,一次推理费用进来平台先抽走一部分平台费,剩下的部分里模型开发者拿走差不多七成,质押节点拿走一成,最后所有被调用的数据贡献者一起瓜分剩下的两成,注意是所有数据贡献者一起分这两成。如果用户的数据恰好不是当次推理的核心贡献者,到手的金额可能连一个U的百分之一都达不到,质押节点的收益主要来自锁仓贡献,不需要额外做任何操作就能稳稳拿到那笔固定分红。说实话我也拿不准这个判断对不对,也许项目方有自己的考虑,但从一个普通参与者的角度看,白皮书前面宣扬的“赋能数据贡献者”的理念和最后那一页的分账公式之间,确实存在一个值得探讨的分配空间。
但换个角度看,这套分账设计至少比Web2时代强了不止一个档次,在传统AI公司里用户贡献的数据被拿去训练模型连被通知的权利都没有更谈不上分钱,OpenLedger至少把账本摊在链上让每个人都能看到,每一笔收入精确到小数点后四位,这个透明度的进步是实实在在的。
写到这里我突然想起一件事,去年我跟踪过另一个类似赛道的项目也是技术白皮书写得天花乱坠,最后却死在Gas费太贵这个现实问题上,OpenLedger能不能绕过类似的坑我现在确实不敢打包票,但这恰恰是需要持续观察的原因。
投票治理机制里那个“多层约束”也让我琢磨了好一阵子,白皮书里强调治理权重不只按代币质押量计算,还把数据贡献质量、节点运维时长、AI模型参与度全部纳入核算,听起来像是对巨鲸寡头化的一种制衡。但我仔细一想,这套规则本身由谁制定、权重参数由谁调整、那些被纳入核算的“贡献质量”又由谁来评估,这些问题在白皮书里并没有给出足够透明的答案,我专门翻到白皮书后面发现确实有一个数据质量评估模块的章节,不过坦白讲那个模块具体怎么运行、由谁审核,我翻了两遍还是没有找到明确的说明。链上的治理投票记录不会骗人,票权最终仍然和质押量高度相关,散户手里攒的那点代币在多因子模型里加完权重之后能产生的影响力相对有限。
说句公道话,这个项目该肯定的地方也不少,它的技术路线里有几个设计确实让我觉得团队在认真做事,比如那个叫OpenLoRA的推理框架把多个微调模型的小适配器塞进同一个基础模型底座上运行,维护费摊下来每个模型都省了一大笔开销。背后由Polychain Capital和Borderless Capital领投的八百万美元种子轮,以及二零二五年九月主网启动后在十一月宣布主网正式上线的节奏,说明资金实力和工程推进能力确实不差,测试网那边的数据我也翻过,一百万条模拟贡献跑通了归因模型,不过说实话放在今天的AI大模型行业里来看,这个体量还只是一个初步验证性的规模,距离真正的商业化落地还有不短的路要走。
我上周专门用区块链浏览器查了一下OpenLedger的智能合约交互记录,随机选了一个区块仔细看了一百笔交易,结果发现其中八十三笔是$OPEN 代币转账,十二笔是质押池的存取操作,只有五笔调用了归因相关的合约接口,这个比例让我对生态的真实活跃度有了更具体的感受。
除了链上数据的问题,还有一个更大的现实挑战摆在面前:这套机制的商用效率到底能支撑到什么程度。开源的归因算法在链上运行的成本并不低,面对百亿参数级别的大模型,全量追溯的计算量高到难以想象,虽然白皮书里提到用Token级别检索矩阵来压缩处理量,但现实情况是链上数据溯源需要消耗Gas费,如果整个生态的商业化落地节奏跟不上数据调用的真实流量不够,那再精巧的经济模型也只能停留在理论层面。我翻看链上活动记录时发现,交易量主要集中在OPEN代币的投机买卖和高APY质押池的资金进出上,真正调用智能合约跑模型推理或者付费采购高质量数据的企业地址,少到几乎可以忽略不计,在这种状况下那些被“数据即资产”叙事吸引进来的普通参与者,在真正的商用流量到来之前代币的支撑逻辑还需要更多实际数据来验证。
不过我会继续保持比较谨慎的观察节奏,也许是我多虑了,也许半年后生态流量就起来了,但在那之前我更愿意多看少动。话说回来我仍然觉得OpenLedger押注的赛道本身是一个巨大的结构性问题,数据确权这个问题不解决AI时代的长尾分配就永远不可能公平,OpenLedger用一套硬核技术试图落地“数据贡献者即股东”的构想,这个方向我认为是对的。但对于普通参与者而言短期看点和长期价值不一定完全重合,真正能在这个生态里获得稳定回报的可能不是那个花三个周末清洗数据的老陈,而是那些盯着巨鲸质押动态做波段分析的人,链上数据会清楚告诉每个人哪些地址在大规模锁仓、解锁周期在什么时候、质押率在什么水平触顶或见底,这些信号比任何宣传话术都诚实。
我会继续把OpenLedger放在我的年度观察清单里,持续跟踪它的生态扩展进度,至于最终能不能跑通我现在不下定论,但这条赛道值得盯着。当然我也可能完全看走眼,如果明年这时候OpenLedger真跑出了百万级日活调用量,我会回来重新评估自己的判断,但至少在今天我觉得保持谨慎观察是一个合理的选择。#OpenLedger