Sarò onesto, tutti notano i due estremi.
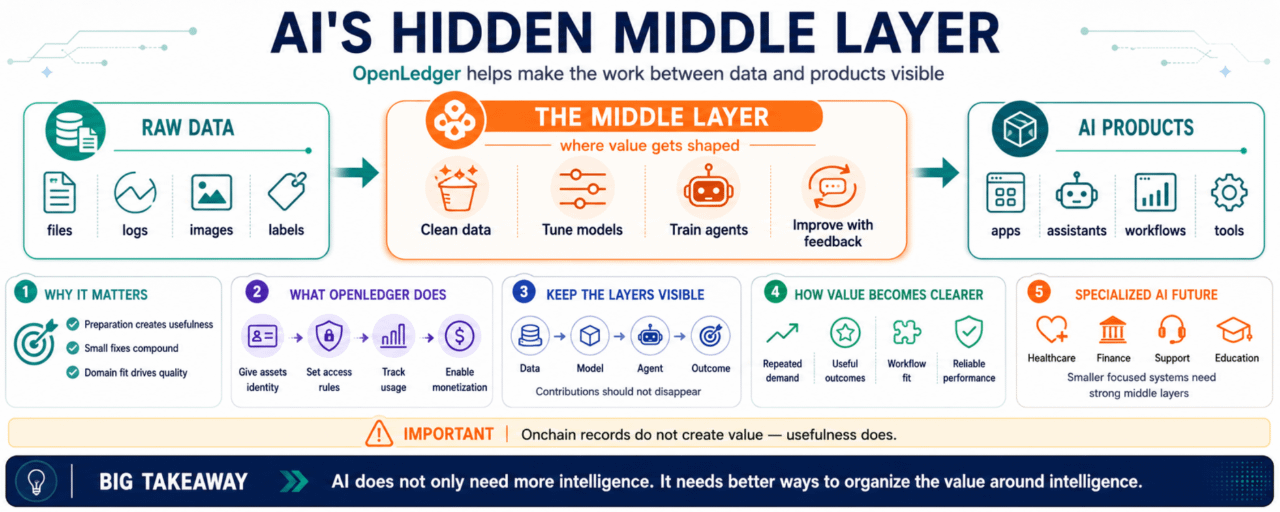
Da un lato, ci sono dati grezzi.
File, testo, registri, immagini, log, conversazioni, etichette, segnali.
Dall'altro lato, ci sono prodotti AI finiti.
App, agenti, assistenti, flussi di lavoro, dashboard, strumenti.
Il mezzo è meno visibile.
È lì che i dati vengono ripuliti.
Dove i modelli vengono modellati.
Dove gli agenti apprendono un processo.
Dove il feedback diventa miglioramento.
Dove la conoscenza del settore diventa qualcosa che una macchina può realmente utilizzare.
E sinceramente, quel livello intermedio potrebbe essere dove si trova gran parte del valore reale.
@OpenLedger diventa interessante se visto da questo angolo.
Non solo come una blockchain AI. Non solo come un luogo per monetizzare dati, modelli e agenti. Piuttosto come un sistema che cerca di dare struttura alla parte dell'AI che di solito scompare tra input e output.
Perché i dati grezzi da soli spesso non sono sufficienti.
Un'azienda potrebbe avere anni di ticket di supporto, ma questo non la rende automaticamente utile per l'AI. Qualcuno deve pulirla. Qualcuno deve rimuovere il rumore. Qualcuno deve organizzarla in un modo che abbia senso. Qualcuno deve collegarla a un modello o a un flusso di lavoro.
Il valore non sta solo nei dati.
Sta nella preparazione.
La stessa cosa succede con i modelli.
Un modello base può fare molte cose, ma potrebbe non comprendere bene un compito specifico. Quindi un team lo affina. Lo testa. Lo corregge. Aggiunge esempi. Lo collega a strumenti. Costruisce un processo attorno ad esso. Lentamente, il modello diventa utile per un lavoro specifico.$PLAY
Quel lavoro non è sempre visibile dall'esterno.
Ma senza di esso, il prodotto finale potrebbe non funzionare.
È qui che le cose diventano interessanti.
Il valore dell'AI non si crea in un momento pulito. Si accumula attraverso piccoli aggiustamenti. Un dataset migliore. Un'etichetta più pulita. Un modello più affilato. Un agente più affidabile. Un flusso di lavoro che rimuove frizioni. Un ciclo di feedback che continua a migliorare i risultati.
Queste non sono cose drammatiche. Sono cose silenziose.
Ma le cose silenziose si accumulano.
#OpenLedger sembra chiedersi se quei pezzi possano diventare asset riconoscibili invece di passi nascosti. Se un dataset preparato migliora un modello, forse quel contributo dovrebbe essere tracciabile. Se un modello specializzato alimenta un agente, forse il suo utilizzo non dovrebbe svanire. Se un agente continua a completare compiti utili, forse dovrebbe avere il suo proprio record economico.
Questo è un modo diverso di pensare alla liquidità.
La liquidità non riguarda solo il tradare qualcosa. A volte si tratta di rendere qualcosa che era precedentemente invisibile più facile da usare, da valutare e da premiare.$PORTAL
E il livello intermedio dell'AI ha un problema di visibilità.
La gente vede lo strumento finale e assume che il valore sia lì. Ma spesso, lo strumento è buono solo grazie al lavoro sottostante. I dati puliti. L'addestramento mirato. Le regole. Gli esempi. Le correzioni umane. Il comportamento dell'agente che è stato affinato nel tempo.
Di solito puoi dire quando qualcosa è passato attraverso quel livello intermedio perché si sente meno generico.
Comprende il compito.
Fa meno errori strani.
Si adatta al flusso di lavoro.
Risponde nel contesto giusto.
Non ha bisogno di costante supervisione.
Quel tipo di utilità raramente appare per caso.
Quindi la domanda cambia.
Invece di chiedere, “Chi possiede il prodotto finale dell'AI?”
Forse dobbiamo anche chiedere, “Chi ha plasmato l'intelligenza che ha reso il prodotto funzionante?”
Questa è una domanda più attenta.
Il focus di OpenLedger su dati, modelli e agenti sta proprio lì. Non riguarda solo l'asset in sé, ma la connessione tra gli asset. I dati che hanno plasmato il modello. Il modello che ha alimentato l'agente. L'agente che ha creato il risultato. Il risultato che ha generato valore.#StrategyHintsNewBTCBuy
Un sistema normale potrebbe appiattire tutto ciò in un unico prodotto.
Un registro può almeno cercare di mantenere visibili i livelli.
Non perfettamente.
Non senza compromessi.
Ma meglio che fingere che i livelli non esistano.
Questo è importante perché l'AI sta diventando più specializzata.
I prossimi sistemi utili potrebbero non essere sempre i modelli generali più grandi. Potrebbero essere combinazioni più piccole di buoni dati, modelli focalizzati e agenti addestrati attorno a flussi di lavoro specifici. Flussi di lavoro sanitari. Ricerca finanziaria. Supporto clienti. Educazione. Logistica. Conformità. Strumenti per sviluppatori.
In ogni caso, il livello intermedio conta.
Il pubblico potrebbe vedere solo l'assistente o l'agente. Ma i costruttori sanno che il vero lavoro è far adattare il sistema all'ambiente.
OpenLedger sembra costruire per quella realtà.
Un luogo dove le parti dietro l'AI possono portare identità, regole di accesso e percorsi di monetizzazione. Un luogo dove i contributori non sono ricompensati solo a livello del prodotto finale, ma potenzialmente attraverso i pezzi che aiutano a creare.
Certo, questo funziona solo se gli asset sono effettivamente utili.
Un cattivo dataset non diventa prezioso solo perché è on-chain.
Un modello debole non diventa importante solo perché ha un record.
Un agente che non risolve nulla non avrà importanza solo perché può essere tracciato.
Il mercato deve comunque giudicare l'utilità.
Ma potrebbe essere questo il punto.
Se l'uso può essere registrato, allora il valore può lentamente diventare più chiaro. Non attraverso affermazioni clamorose, ma attraverso una domanda ripetuta.
Dopo un po', diventa ovvio che l'AI non ha bisogno solo di più intelligenza. Ha bisogno di modi migliori per organizzare il valore attorno all'intelligenza.
OpenLedger è un tentativo di organizzare quel livello intermedio.
La parte tra materia prima e prodotto finito.
La parte in cui molti piccoli miglioramenti si trasformano in qualcosa che finalmente funziona.
@OpenLedger #OpenLedger $OPEN
Articolo
C'è uno strato intermedio nell'AI di cui le persone non parlano abbastanza.
Il token menzionato in questo articolo potrebbe essere soggetto a un'elevata volatilità. Fai le tue ricerche.
Disclaimer: include opinioni di terze parti. Nessuna consulenza. Binance AI può essere utilizzata senza garanzia. Consulta i T&C.