
@OpenLedger ha catturato la mia attenzione per un motivo che mi ha preso imbarazzantemente troppo tempo per articolare completamente. Continuavo a ripetermi che era per la tokenomics, o per l'angolo AI, o semplicemente per pura curiosità. Ma quando mi sono seduto e ci ho pensato seriamente, il vero gancio era una domanda che il progetto ti costringe a confrontare: chi possiede realmente i tuoi dati e, cosa più importante, chi cattura il valore che questi generano? Queste due cose sono state silenziosamente separate nell'era dell'AI, e la maggior parte delle persone, me compreso, non se ne è accorta fino a poco tempo fa.
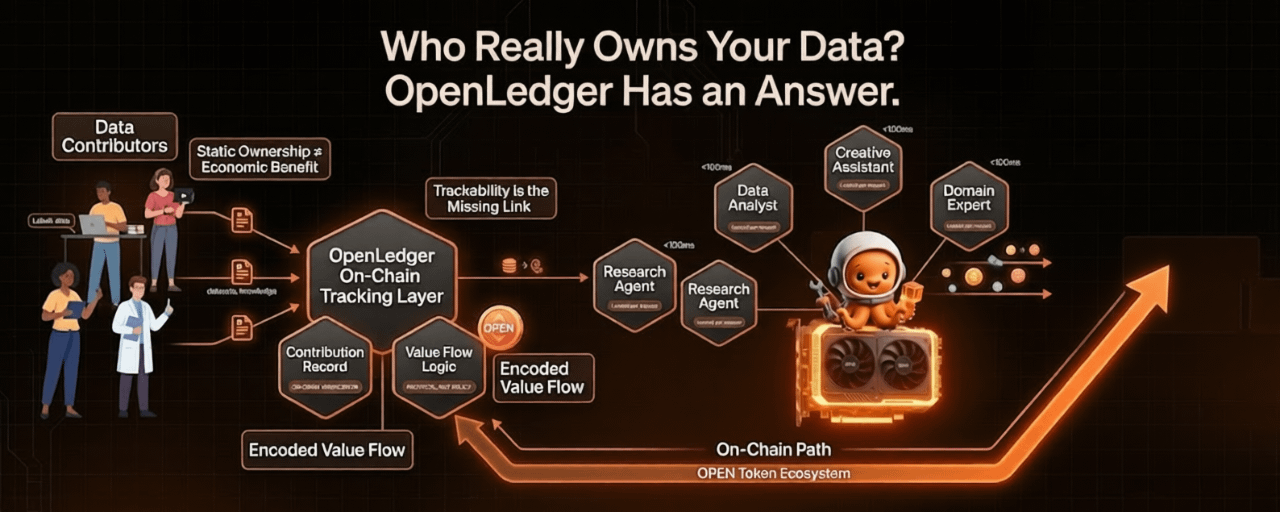
La proprietà dei dati sembra un problema risolto in superficie. La gente annuisce quando si presenta, assume che i quadri giuridici lo stiano gestendo e va avanti. Ho fatto lo stesso per molto tempo. È stato effettivamente passando attraverso la documentazione di OpenLedger che mi ha fatto clic in un modo che non era mai successo prima. La proprietà legale e il beneficio economico sono cose completamente diverse. Puoi possedere i tuoi dati in un senso tecnico mentre vedi ogni dollaro di valore che genera fluire altrove. Nel contesto dei sistemi IA, questo non è un caso marginale. È l'esito predefinito. Ogni dataset etichettato, ogni collezione di conoscenze specifiche di dominio, ogni storia di interazione curata alimenta modelli che vengono distribuiti su larga scala e le persone che hanno prodotto quel materiale grezzo quasi mai vedono un ritorno proporzionale a ciò che hanno contribuito.
OpenLedger lo inquadra meglio di quanto abbia mai visto altrove: il problema non è la proprietà, è la tracciabilità. Il valore scompare a monte. Fluisce a chi controlla il modello, e ulteriormente a monte a chi controlla l'infrastruttura su cui il modello opera. Quando i premi economici vengono distribuiti, i contributori originali sono così lontani dal processo che il loro ruolo è diventato invisibile. Questo non è un incidente o una svista. È il risultato naturale di un sistema in cui i dati non hanno un meccanismo affidabile per tracciare il proprio contributo alla creazione di valore a valle. Quando non puoi misurare un contributo, non puoi prezzarlo. Quando non puoi prezzarlo, non puoi compensarlo. Non sono sicuro del perché questo non renda più persone arrabbiate.
Questo è il gap specifico che OpenLedger sta puntando. L'approccio si concentra sulla costruzione di uno strato di tracciamento verificabile tra i contributori di dati, i sviluppatori di modelli e gli operatori agenziali, dove il contributo è registrato on-chain e la compensazione segue l'uso effettivo piuttosto che chiunque controlli l'infrastruttura circostante. Il token OPEN è l'unità attraverso cui opera questa logica economica. Non è decorativo. È il meccanismo che rende possibile la compensazione trustless tra i partecipanti senza richiedere un'autorità centrale per gestire la distribuzione. Sarò onesto, quando ho letto per la prima volta questo, cercavo il trucco. Non ne ho ancora trovato uno.
Ciò che trovo più interessante del framing di OpenLedger è come ridefinisca interamente la questione della proprietà. La proprietà statica, chi detiene i diritti su un file o un dataset, è quasi irrilevante. La domanda che conta realmente è chi beneficia quando i dati fanno qualcosa. Quando addestra un modello. Quando quel modello viene chiamato migliaia di volte. Quando gli output di quel modello creano valore per qualcuno a valle che non ha mai interagito con il contributore originale. OpenLedger sta costruendo un'infrastruttura per tracciare l'intera catena e garantire che il valore fluisca indietro attraverso di essa in modo proporzionale. Questo è un problema significativamente più difficile rispetto alla dichiarazione di proprietà, ed è il problema che ha reali conseguenze economiche su larga scala.
Questo è esattamente il motivo per cui l'approccio on-chain di OpenLedger conta più di quanto potrebbe sembrare inizialmente. Una piattaforma centralizzata può fare le stesse promesse: compensazione equa, tracciamento trasparente dell'uso, ricompense proporzionali. Ma una promessa da un'entità centralizzata è valida solo quanto gli incentivi di chi la gestisce. Quando le condizioni commerciali cambiano, quando le pressioni di crescita spostano le priorità, quando emerge un modello più redditizio, quelle promesse vengono silenziosamente riviste. OpenLedger codifica le regole di compensazione nel protocollo stesso piuttosto che in un documento di policy. I termini non vivono da qualche parte che può essere aggiornato con un preavviso di trenta giorni. Vivono nella logica del sistema, applicata dalla catena piuttosto che dalla buona volontà.
Per chiunque stia pensando seriamente di contribuire con dati o modelli preziosi all'ecosistema di OpenLedger su un lungo orizzonte temporale, quella distinzione è la differenza tra partecipare a qualcosa ed essere estratti da esso. Ci penso più di quanto dovrei. Ma più ci rifletto, più sembra essere la decisione di design più importante che il progetto ha preso...
Il contesto più ampio conta anche. L'industria dell'IA è nelle fasi iniziali di quella che alla fine sarà riconosciuta come una delle più grandi concentrazioni di valore nella storia economica: la conversione della conoscenza e dei dati generati dagli esseri umani in sistemi automatizzati che catturano la maggior parte del valore risultante per un piccolo numero di attori centralizzati. OpenLedger sta costruendo un'infrastruttura che potrebbe reindirizzare in modo significativo parte di quel valore verso le persone che hanno effettivamente prodotto gli input. Se avrà successo completamente è qualcosa che nessuno può dire con certezza al momento. Ma l'architettura è seria e il problema che viene affrontato è reale.
La proprietà dei dati nell'era dell'IA non è un problema risolto. È a malapena anche un problema ben definito nella maggior parte delle conversazioni che stanno avvenendo in questo momento. Ciò che OpenLedger sta facendo, costruendo l'infrastruttura economica per rendere la proprietà significativa piuttosto che simbolica, è esattamente il tipo di lavoro fondamentale che tende a sembrare ovvio in retrospettiva, una volta che esiste. Non mi aspettavo di interessarmi così tanto a questo quando ho iniziato a guardare. Ed ecco dove siamo.
