There is a familiar kind of fatigue that comes after many years of staying in this market, the fatigue of watching too many systems speak about AI with absolute confidence while sidestepping the most basic question, where value is actually created and what trace of it still remains after the output has been packaged neatly. I read Openledger’s materials in exactly that state, with almost no interest left for smooth sounding descriptions. But when I reached the Perceptron section, my reading slowed down, because this time what was being pushed forward did not feel like a new presentation layer, but like a branch showing that the whole system is leaning clearly toward verifiable intelligence.
What kept me sitting there was not that Perceptron sounded new. This market has never lacked new names. What drew my attention more was the way Openledger uses that branch to reveal a deeper shift in the logic of how the infrastructure is being built. When people talk about intelligence, the easiest parts to describe are always speed and fluency. What is much harder is proving which data had an effect, which model processed it, which reasoning steps were involved, and why those contributions do not disappear once the result is placed in front of the user.
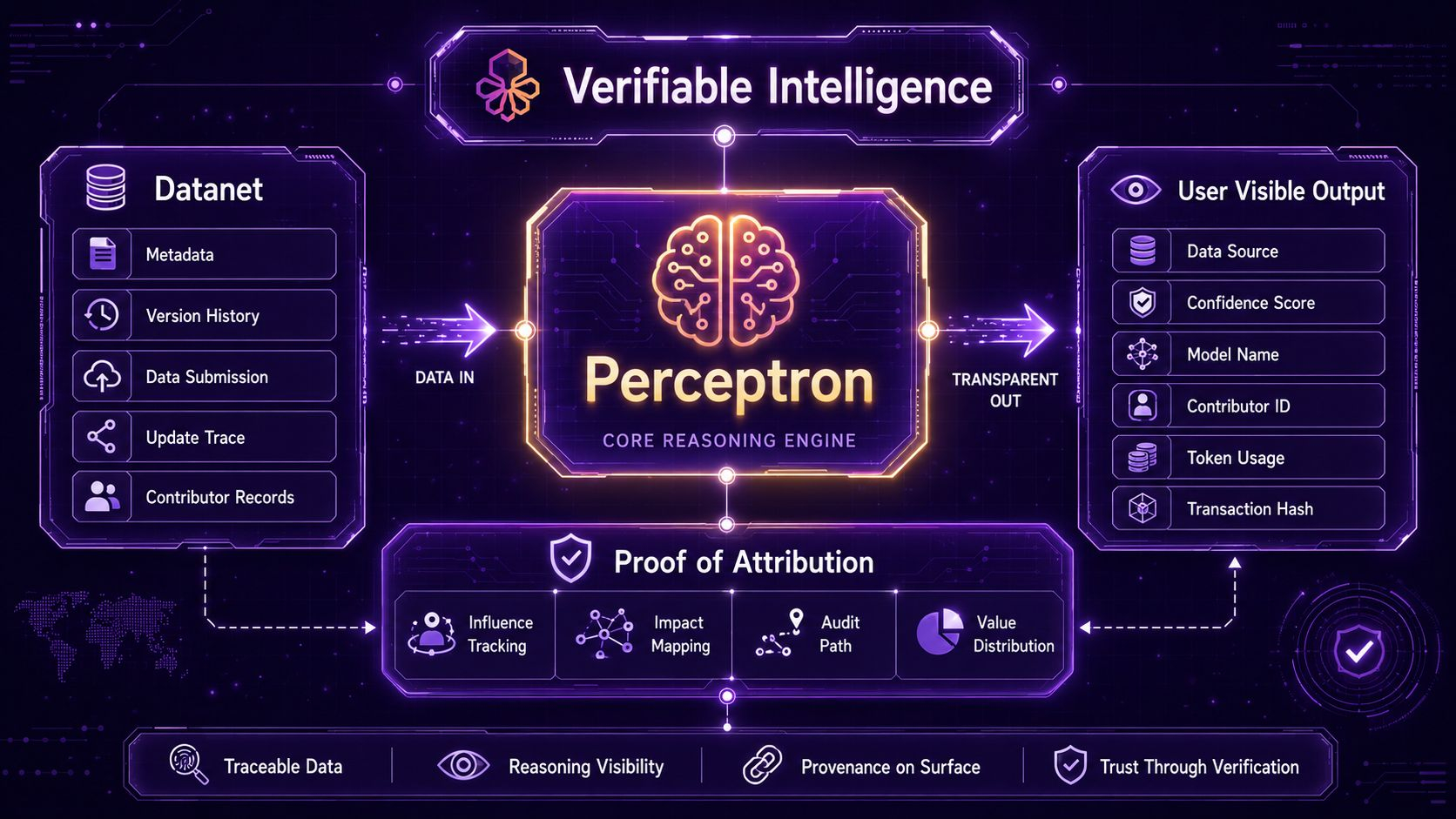
Viewed from an architectural angle, I can see that the project does not want intelligence to exist as a polished finished object, separated from the whole backstage that raised it. Datanet shows that data is not treated as anonymous raw material. Every dataset has to carry metadata, versioning, a history of changes, and an update process so that every modification leaves a trace. Those details sound operational on the surface, but in fact they are the clearest statement of what Openledger wants, data must have a history, and that history must become the foundation for explaining the output.
That is why Perceptron does not stand out in the way a product receives extra promotional attention, but because it sits exactly at the intersection of data, reasoning, and value distribution. I think this is the point that separates Openledger from many familiar AI narratives. If verifiable intelligence remains only a promise, users will still be asked to trust a black box that has simply been described more elegantly. But when a branch is brought forward as the clearest reflection of the relationship between the output and the traces that created it, the whole system is forced to live under a stricter standard.
The heaviest part still lies in Proof of Attribution. This is not a technical layer added to make the description sound more academic, but an attempt to connect an outcome to the data that truly left an impact on it. A system that accepts this problem also accepts the burden of computation, the burden of explanation, and the burden of value distribution afterward. That is why I see Perceptron as the most prominent branch as Openledger shifts its center of gravity toward verifiable intelligence. It is where the hardest part of the vision is dragged down from conceptual language into the zone where it actually has to operate.
At the technical level, what matters is that they do not behave as if attribution has one single solution for every scale. With smaller models, the estimation of data influence can rely on influence function approximation. When the scale grows, the logic for tracing impact shifts toward token matching on compressed corpora using suffix arrays. Many people will find those parts dry, but to me that is exactly what confirms that Openledger is not merely borrowing the language of provenance to build a narrative. A system that is truly serious has to possess a way to calculate the path of influence.
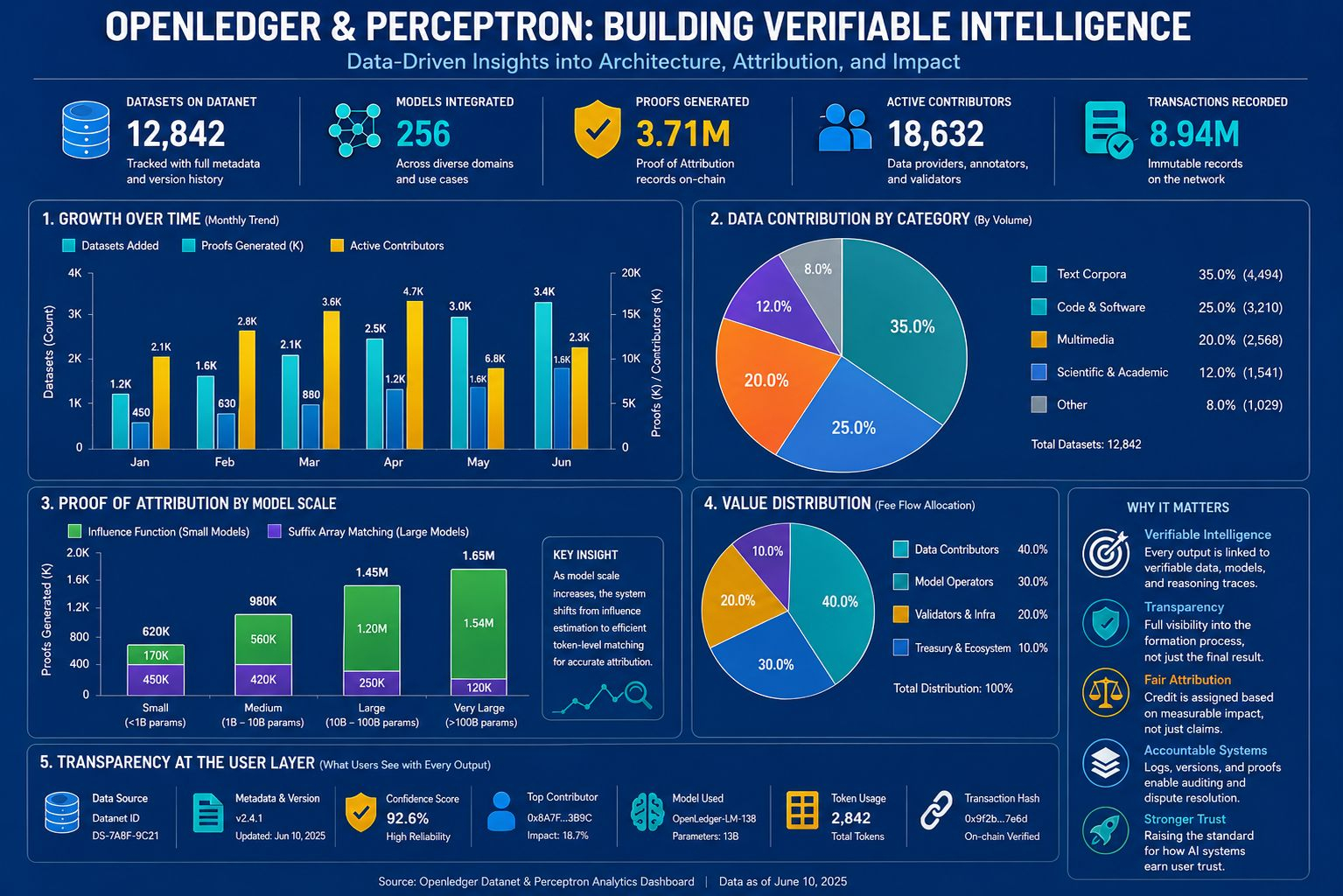
At the layer users touch every day, an answer must not appear as a clean block of content with every trace behind it scrubbed away. Data source, metadata, confidence score, contributor identification, model name, token usage, transaction hash, everything related to the formation process has to be pulled up to the surface as part of the experience itself. I value the way Openledger approaches this, because provenance only matters when it appears at the exact moment the user encounters the result, not when it is buried in an explanation page that almost nobody opens.
Of course, a traceability layer does not automatically make everything fair. Similar datasets can still create disputes over the level of contribution. Clean data is not always the data that creates the strongest impact. End users will not always prioritize provenance over speed. But I think Openledger’s seriousness lies in the fact that they do not blur those collisions, they pull them back into logs, version history, attribution paths, and fee flows so that disagreements can rest on things that can actually be checked. After many years of watching the market glorify smoothness while abandoning the question of who actually raised those outputs, what I find most worth following is the way Openledger is trying to force intelligence to carry the history of its own formation all the way to the product surface, and if that choice is carried through to the end, could this be the moment when the standard for trusting AI begins to be rewritten from the foundation up.