There was a time I almost dismissed this direction entirely because I was too tired of hearing promises about AI becoming lighter and easier. But after reading more carefully, I felt Openledger was not just polishing the surface of the fine tuning process, it was pulling LoRA and QLoRA into a clearer deployment structure, where the machinery in the background depends less on manual memory.
LoRA and QLoRA are not new. What made me stop was the way the project does not present them as isolated tools, because Openledger is trying to gather data, configuration, adapters, and the serving layer into one path that can be traced back. When it is made clear where an adapter comes from, which fine tuning run it belongs to, and by what logic it moves into a live environment, the technical layer stops being something that exists only on paper.
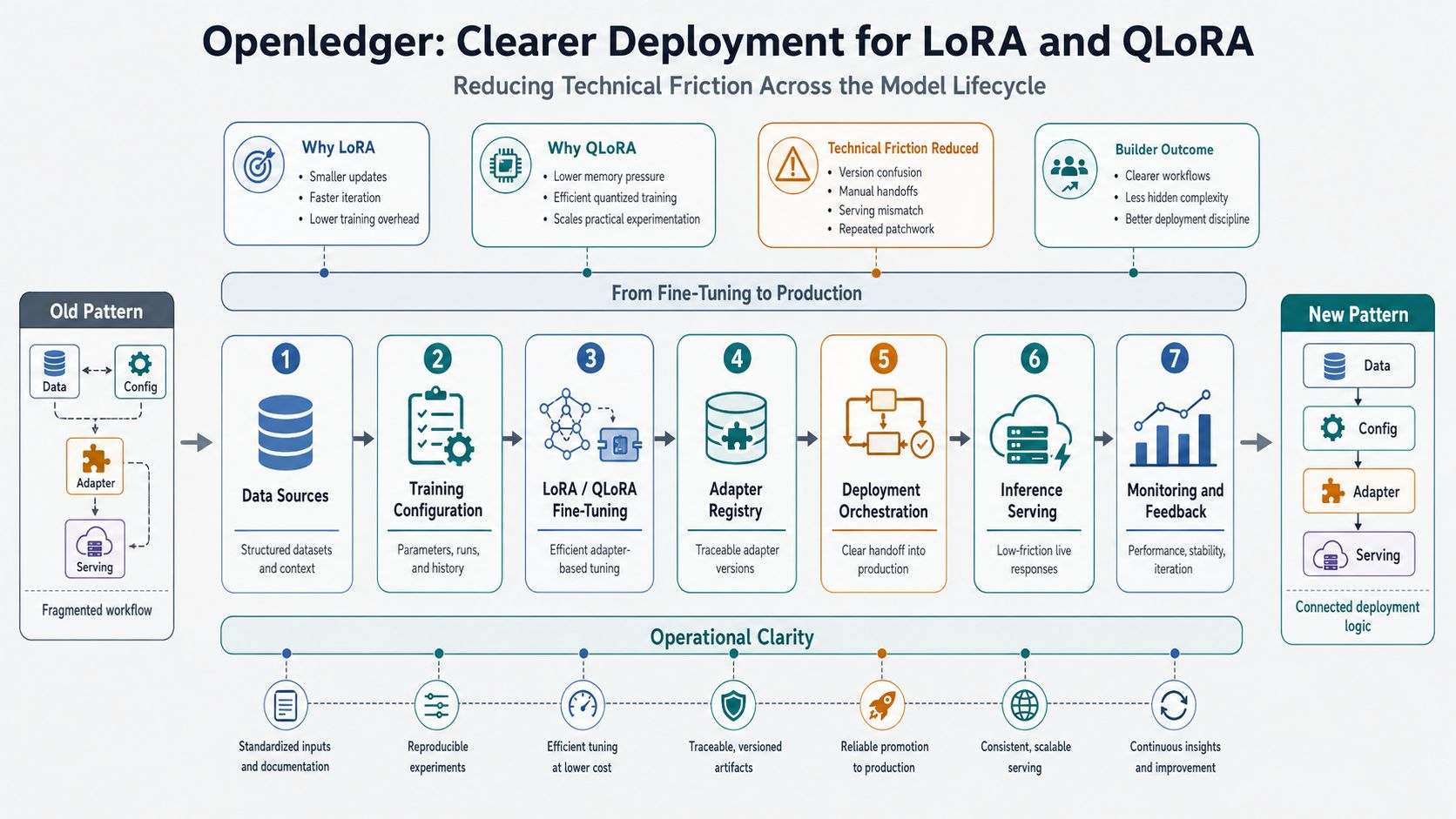
I think this is the point that separates this direction from many familiar AI narratives. People often emphasize that LoRA reduces the number of weights that need to be updated, while QLoRA lowers memory pressure, but the harder part comes after that, and Openledger is going straight into that harder stretch. An adapter being produced quickly does not say much, because what usually consumes a builder’s time is version management, matching the adapter to the right data, and then moving it into serving without creating another layer of patchwork.
From the perspective of someone who has had to stare at logs late into the night, this choice is harder than it looks. For LoRA and QLoRA to actually reduce technical friction, a system has to preserve the relationship between input data, fine tuning configuration, output adapters, and the way the model responds once it enters serving, and that is the place where Openledger makes me pay close attention. To be honest, many teams do not fail because of weak ideas or a lack of resources, they fail because of small things like mixing up checkpoints, confusing versions, or calling the wrong adapter.
What kept me with it longer was the way the project resets the relationship between the training stage and the deployment stage. Normally, people treat LoRA and QLoRA as tricks that make fine tuning lighter, while everything that comes after gets pushed into a blurry zone, but here Openledger is pulling the serving layer back to the center. When an adapter is no longer just a file created and then thrown somewhere else, but becomes a unit with an origin and a clear path into a live environment, the value of the infrastructure starts to show.
Of course, the more clearly a structure is defined, the greater the pressure to keep that structure from becoming hollow. Once there are many adapters, many base models, and many layers of data living together, the market will always look for the fastest way to optimize and cut corners in the places few people can see, so Openledger is only truly convincing if the logic connecting LoRA and QLoRA to the deployment layer is tight enough that real builders do not have to go back and trace every link after each change. Ironically, what exhausts teams is rarely a major failure, but small misalignments that refuse to die.
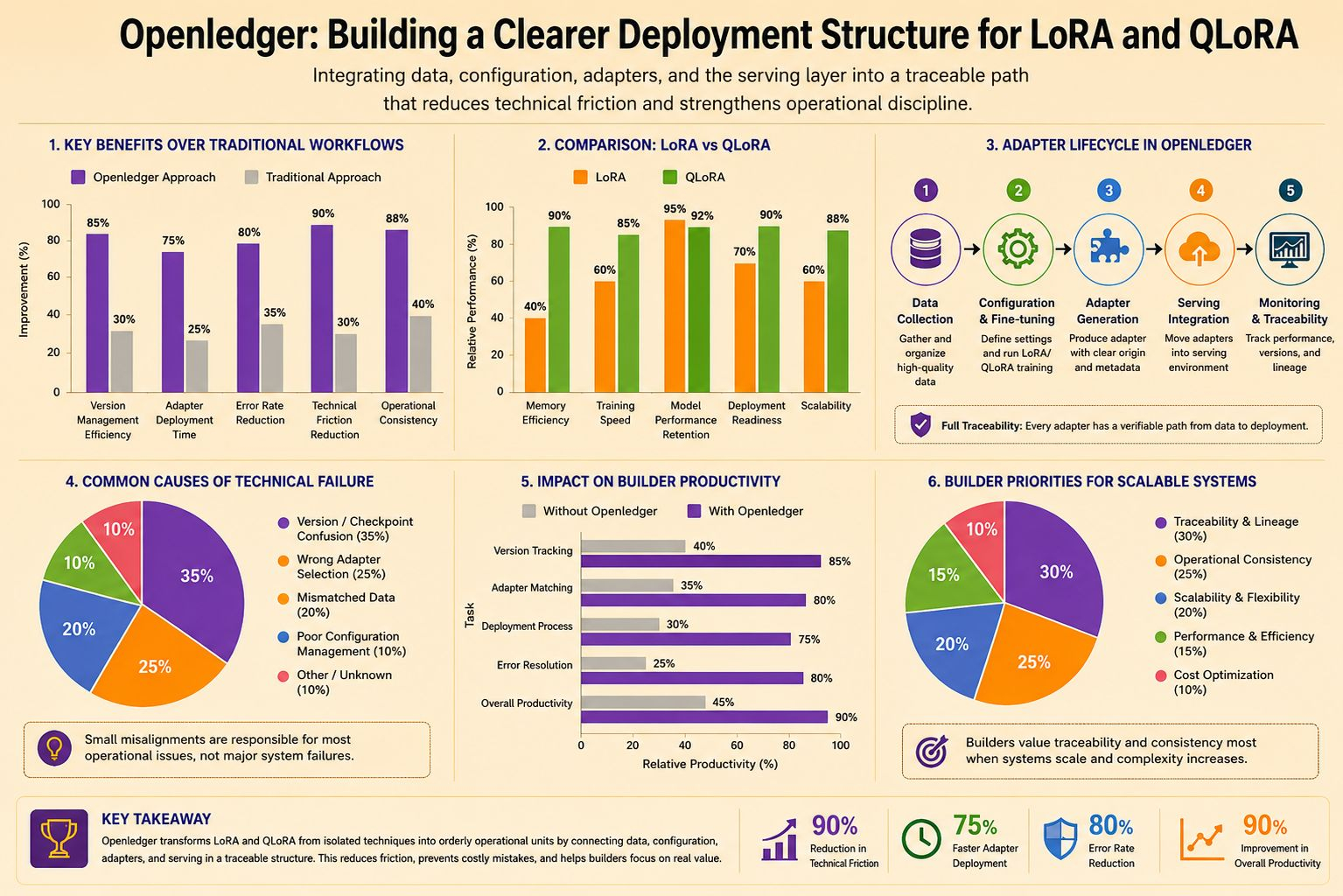
Maybe that is why I do not look at this project with easy excitement. After many cycles, I no longer trust systems that only talk about computational efficiency while ignoring the smallest units of technical labor, while Openledger suggests something more worth thinking about, that LoRA and QLoRA can be treated as orderly operational units rather than convenient patches. When an architecture knows how to preserve the link between training, attribution, and serving, builders spend less time putting out fires.
What keeps me thinking now is no longer how well the project can tell an AI story, but whether, once the scale becomes larger and the pressure to expand becomes heavier, Openledger can still preserve the discipline of its original choice. This path does not easily win over the crowd, because it forces a system to look closely at its smallest moving parts, resist the temptation to hide disorder behind a few polished layers of presentation, and prove that pulling LoRA and QLoRA into a clearer deployment structure is really about reorganizing operational logic, or whether in the end everything will slide back into the same familiar shortcut.