
Sáng hôm nay mình dậy sớm hơn thường lệ, pha cà phê rồi mở laptop với ý định nghiêm túc: research xem có nên build một model chuyên ngành trên OpenLedger không. Mình đã đọc whitepaper đủ lần để hiểu cơ chế attribution, đã tính sơ bộ inference revenue potential, và đang ở giai đoạn cuối trước khi quyết định.
Rồi mình hỏi một câu mà suốt quá trình research trước đó mình chưa hỏi: nếu mình build xong model này, nó thuộc về ai?

Mình search trong whitepaper. Không có câu trả lời. Mình uống hết ly cà phê mà vẫn không tìm được. Đó là buổi sáng mình quyết định chưa build gì cả cho đến khi hiểu rõ điều đó.
Câu hỏi ownership có ít nhất ba lớp phức tạp chồng lên nhau.
Lớp đầu tiên là base model license. Hầu hết foundation models phổ biến hiện tại đều có license riêng về derivative works. Llama 3 của Meta có Llama 3 Community License, cho phép commercial use nhưng cấm dùng output để train model cạnh tranh với Meta. Mistral có Apache 2.0, liberal hơn nhưng vẫn có điều kiện attribution. Khi developer dùng ModelFactory để fine-tune Llama 3 với data từ Datanets, output model vẫn bị ràng buộc bởi Llama 3 Community License. OpenLedger không thể grant ownership vượt qua giới hạn mà Meta đặt ra. Whitepaper không đề cập điều này ở bất kỳ đâu.
Lớp thứ hai là data attribution và ownership. OpenLedger track influence của từng data point lên model output và trả rewards cho contributors. Nhưng reward không đồng nghĩa với ownership. Hãy lấy ví dụ cụ thể: một radiologist đóng góp 10,000 ảnh X-quang có annotation, chiếm 40% training data của một diagnostic model. Model được deploy và generate doanh thu đáng kể. Nếu radiologist sau đó phát hiện model đang được insurance company dùng để từ chối claim bệnh nhân, họ có cơ chế nào để can thiệp không? Whitepaper không có câu trả lời. Attribution tracking và ownership rights là hai thứ hoàn toàn khác nhau, và OpenLedger chỉ giải quyết thứ đầu.
Lớp thứ ba là protocol governance risk. Smart contract trên OpenLedger có thể include ownership clause về model được register trên chain. Nếu governance vote thay đổi platform fee hoặc thêm revenue sharing requirement, developer không có cách opt-out mà không remove model khỏi hệ thống. Khi đã invest đáng kể vào build và train model trên OpenLedger infrastructure, switching cost để migrate sang nơi khác rất cao. Đây là vendor lock-in không được acknowledge trong bất kỳ documentation nào.
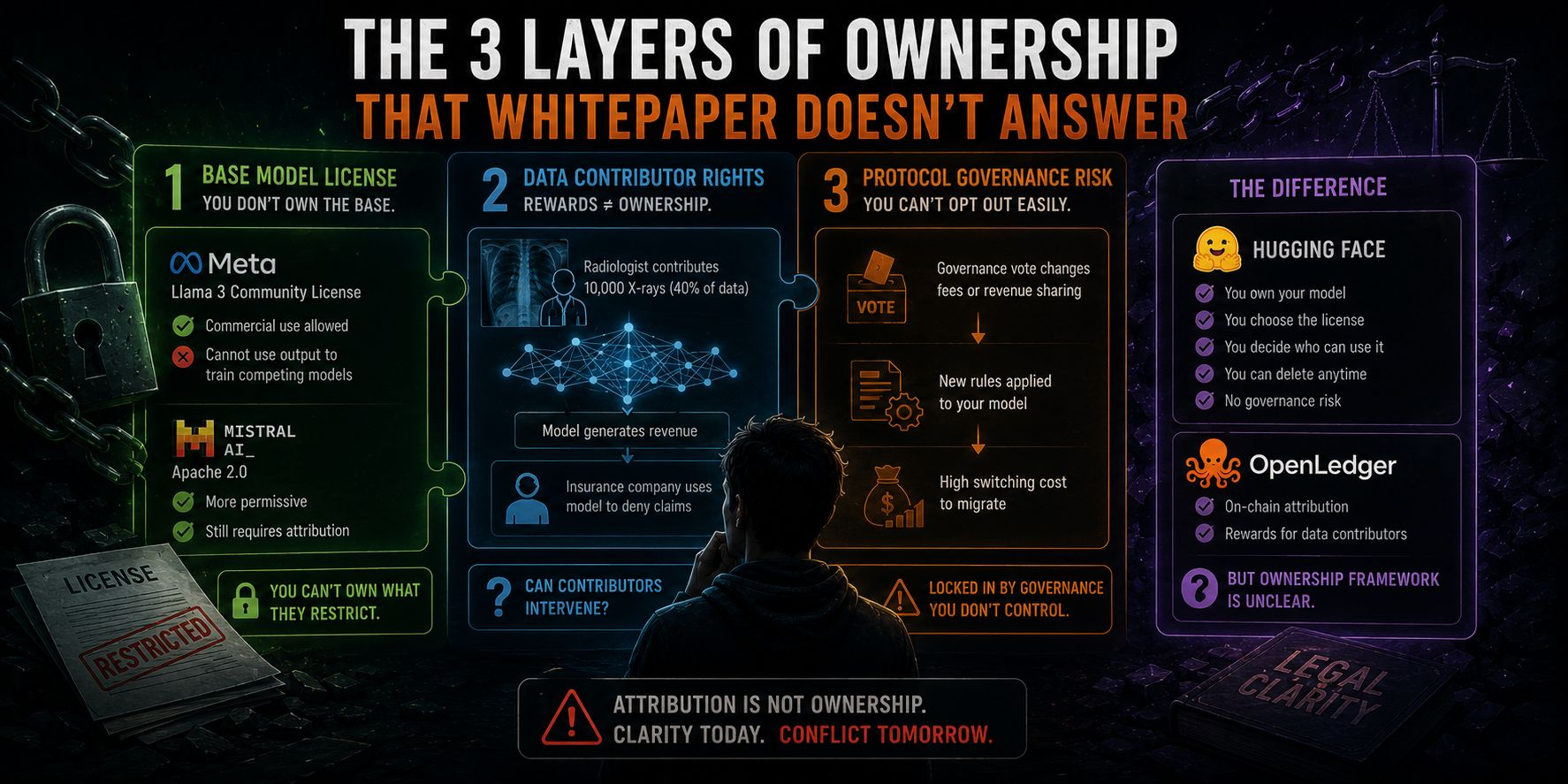
So sánh với Hugging Face: khi fine-tune model và upload lên Hub, ownership thuộc về bạn hoàn toàn. Bạn chọn license, quyết định ai được dùng, có thể delete bất cứ lúc nào. Không có attribution claim từ người upload data vào dataset của bạn, không có governance risk về platform fee.
OpenLedger offer thứ Hugging Face không có: on-chain attribution và rewards cho data contributors. Đó là value proposition thật. Nhưng nó đến với một bộ legal ambiguity mà developer cần hiểu rõ trước khi commit.
Mình vẫn chưa build model trên OpenLedger. Không phải vì không tin vào technology. Mà vì khi ownership framework không được định nghĩa rõ ràng từ đầu, conflict sẽ xảy ra sau này và không ai biết cơ chế giải quyết là gì.
Nhưng đây là điều mình tin: nếu OpenLedger publish một legal framework rõ ràng về model ownership, đây sẽ là lần đầu tiên trong lịch sử AI infrastructure có protocol nào giải quyết đồng thời cả attribution, rewards, và ownership trong một hệ thống duy nhất. Không phải Hugging Face, không phải AWS SageMaker, không phải bất kỳ ai khác đang làm điều đó. Đó là moat thật sự mà OpenLedger đang ngồi trên mà chưa khai thác hết.
Một legal whitepaper về model ownership trên OpenLedger sẽ không chỉ giải quyết lo ngại của mình. Nó sẽ là lý do để hàng nghìn developer nghiêm túc chọn OpenLedger thay vì Hugging Face cho project tiếp theo của họ.
